Downloaded 108 times















![Time-series forecasting of indoor temperature using pre-trained Deep Neural Networks
Appendix
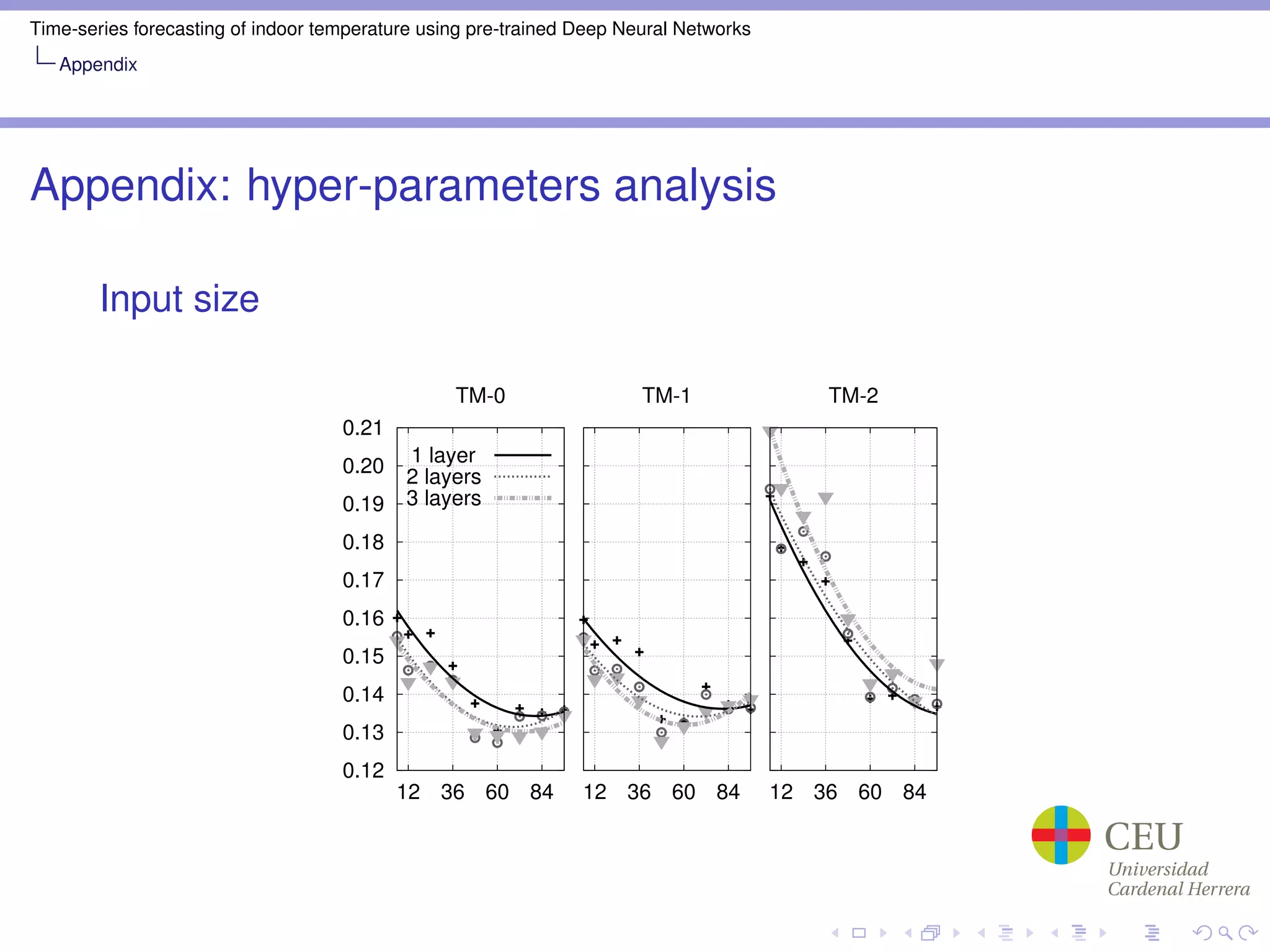
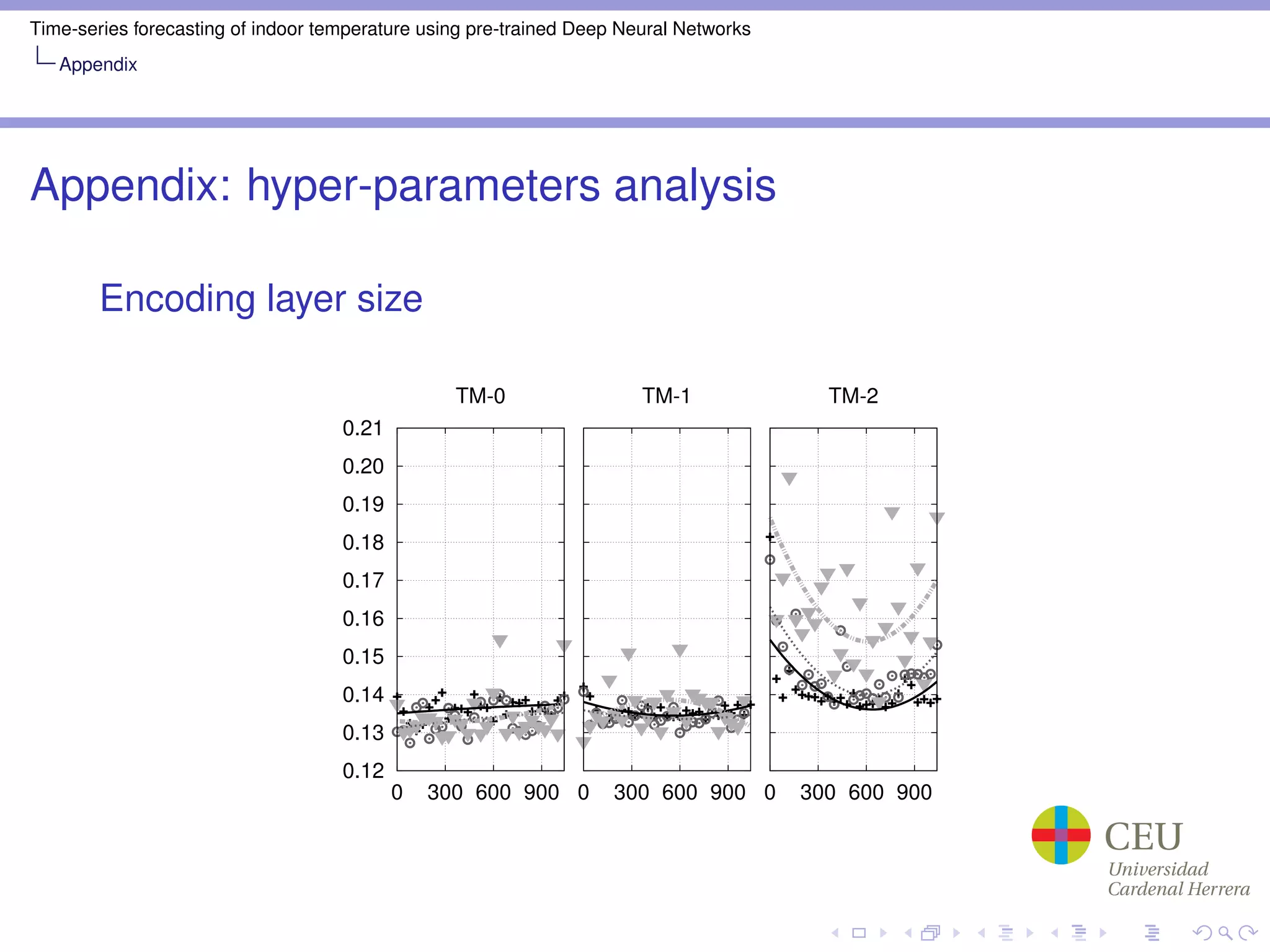
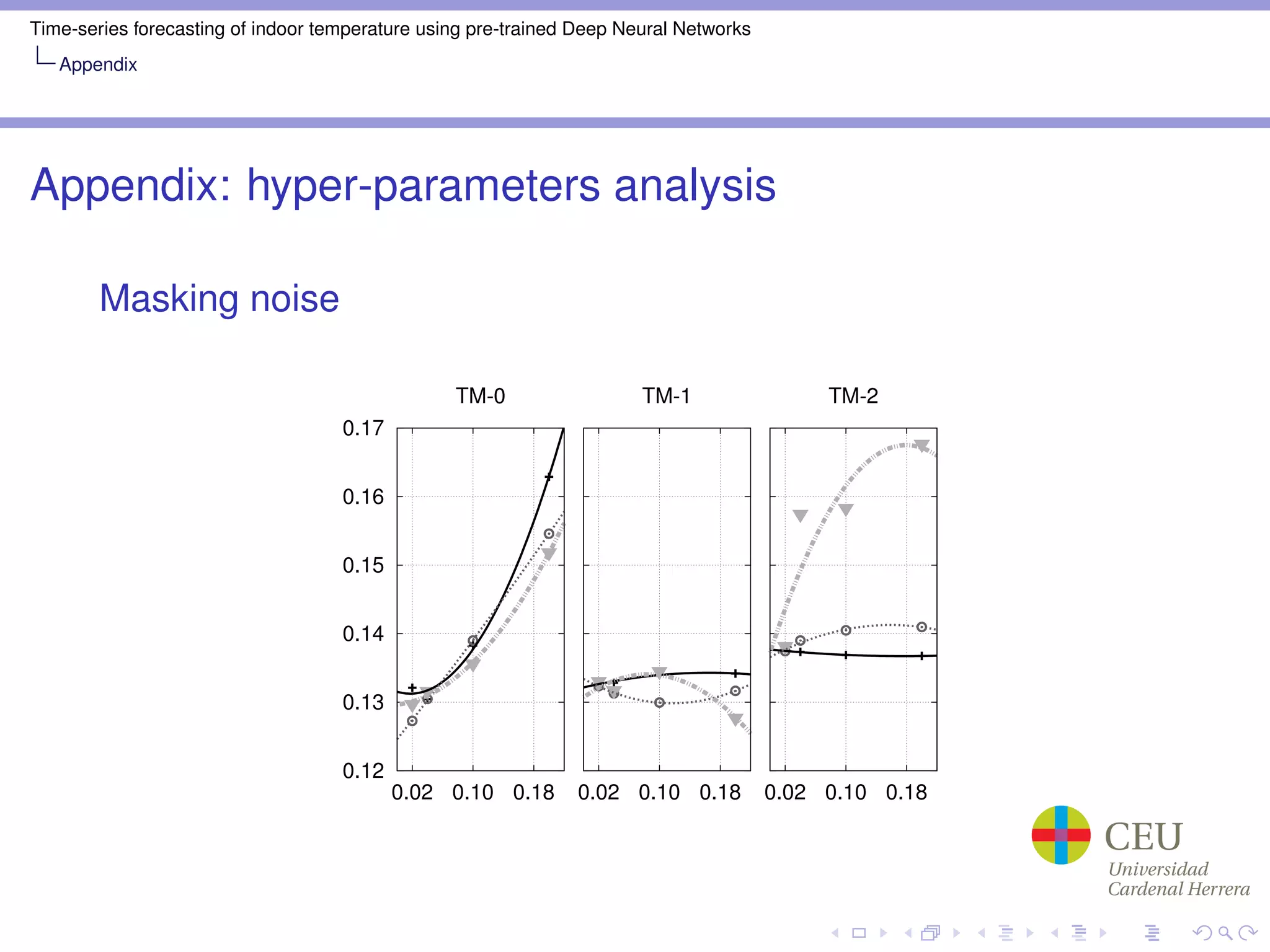
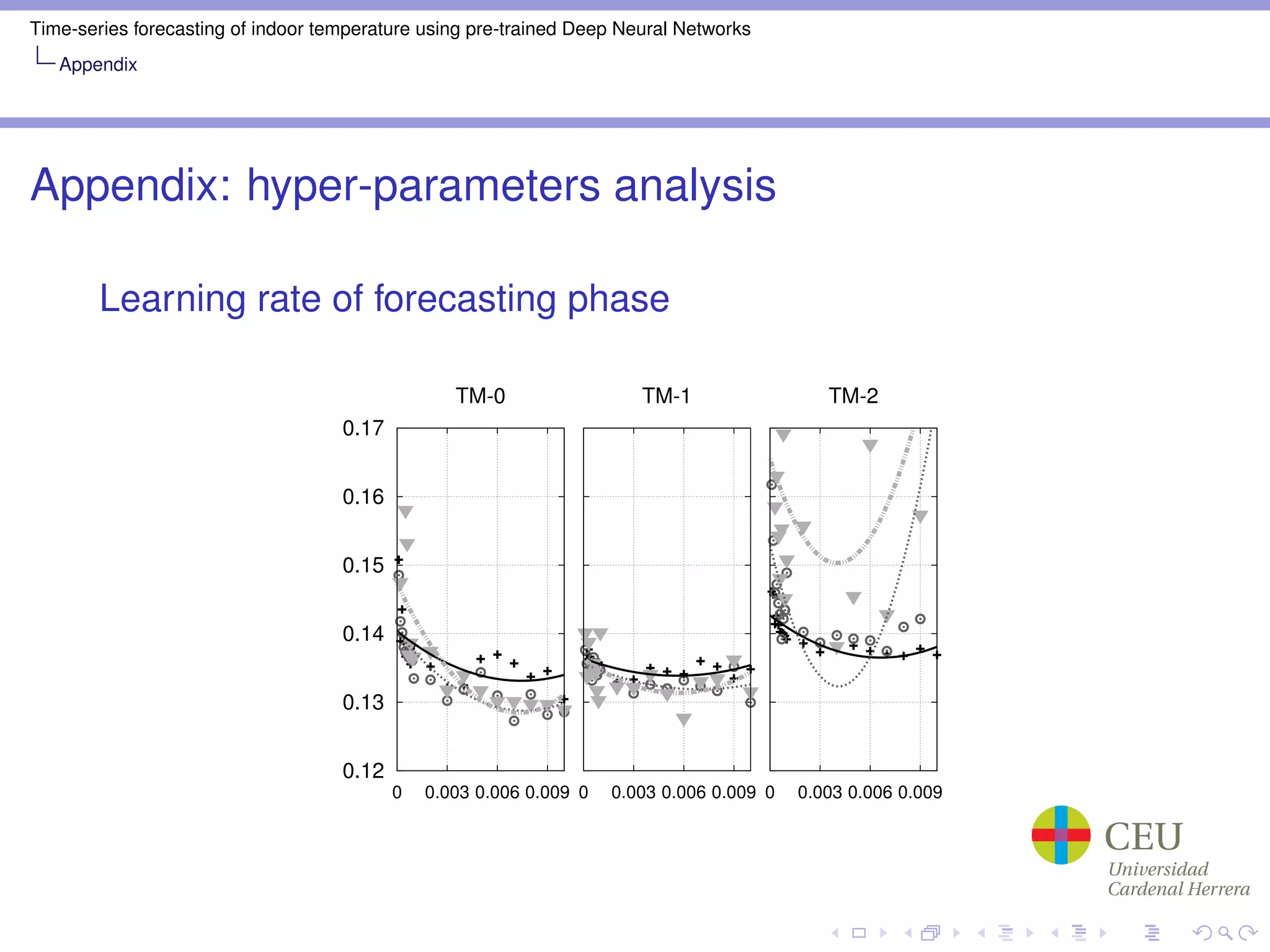
Appendix: Hyper-parameter optimization
Grid search part
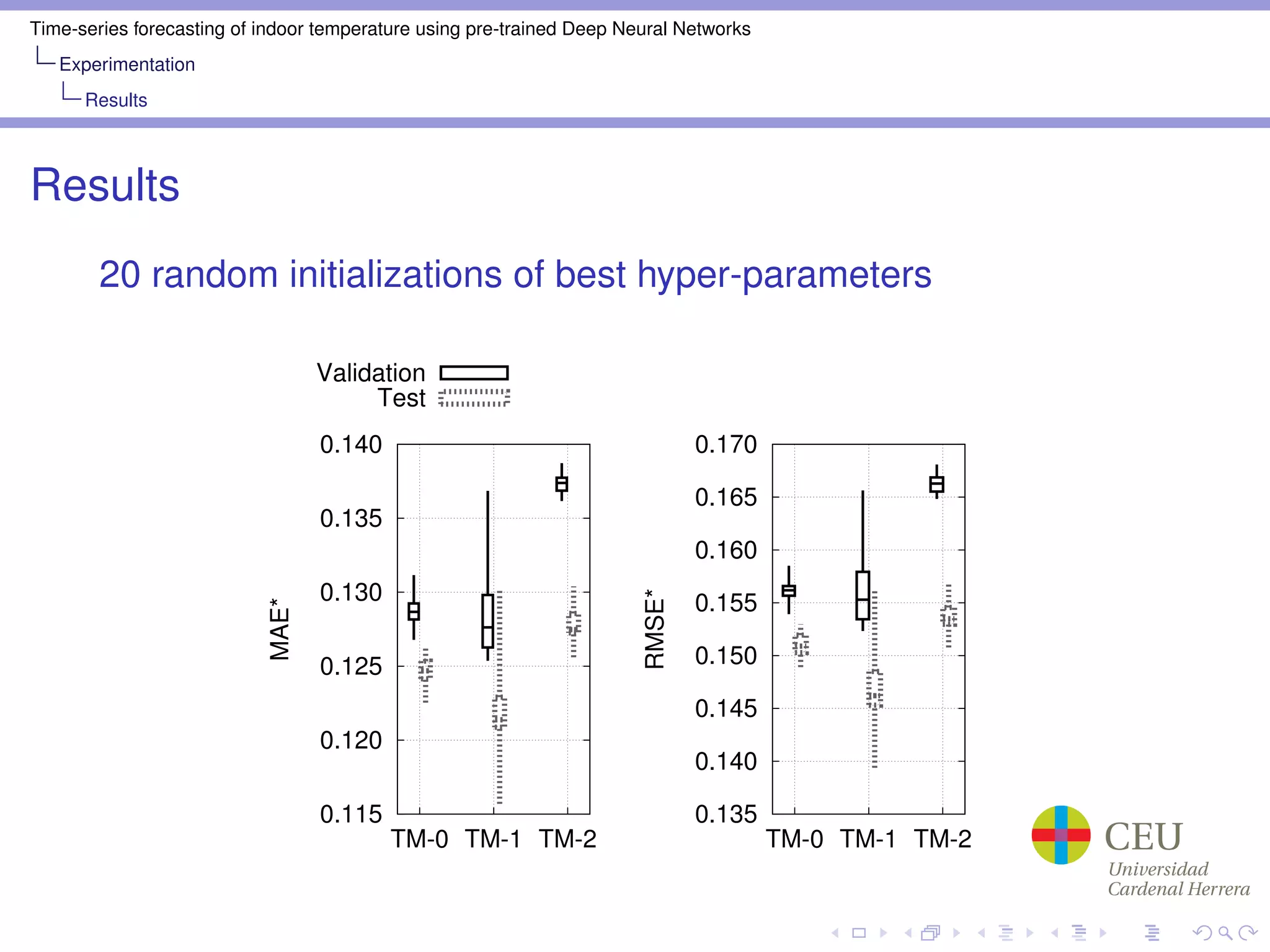
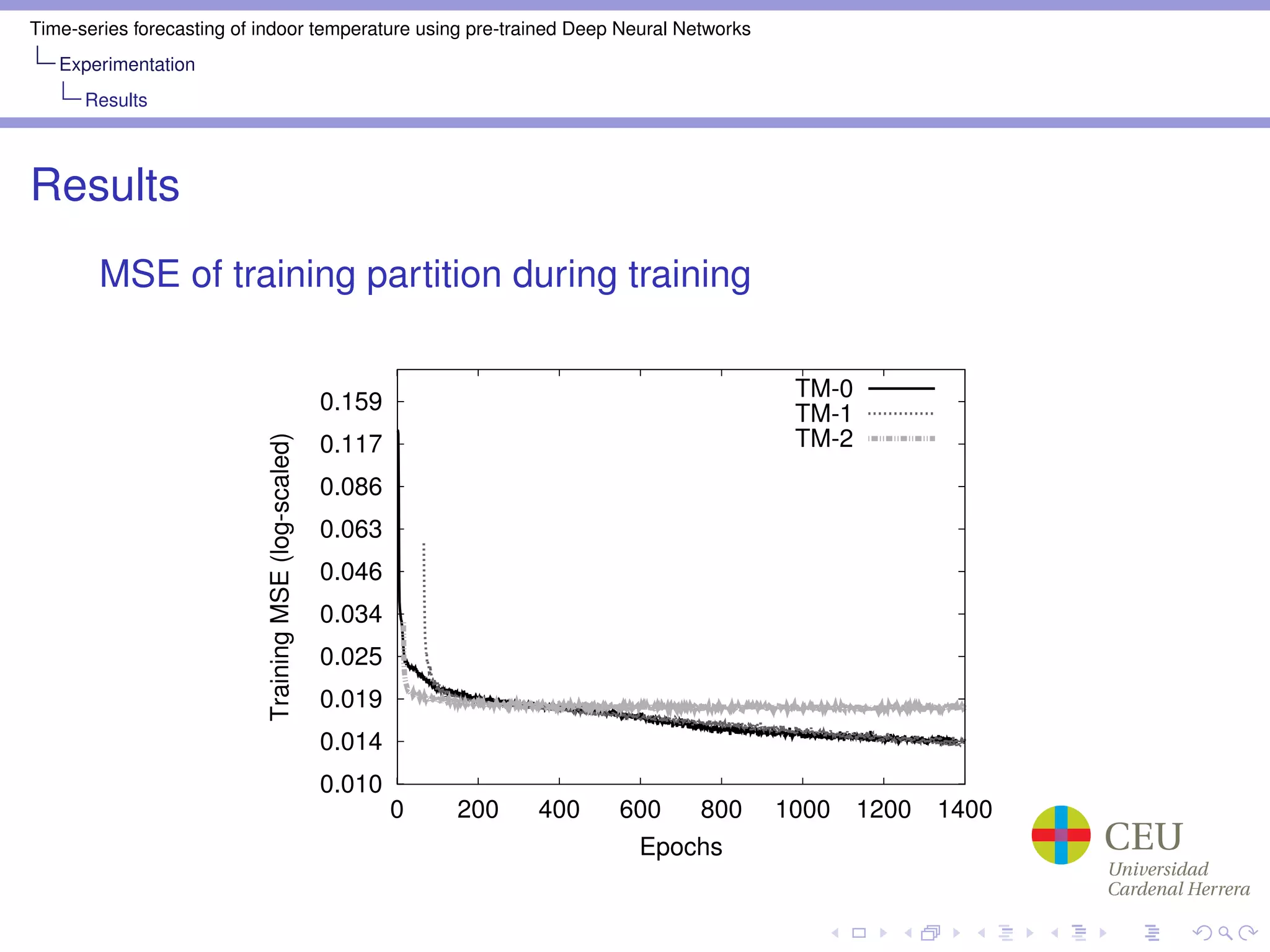
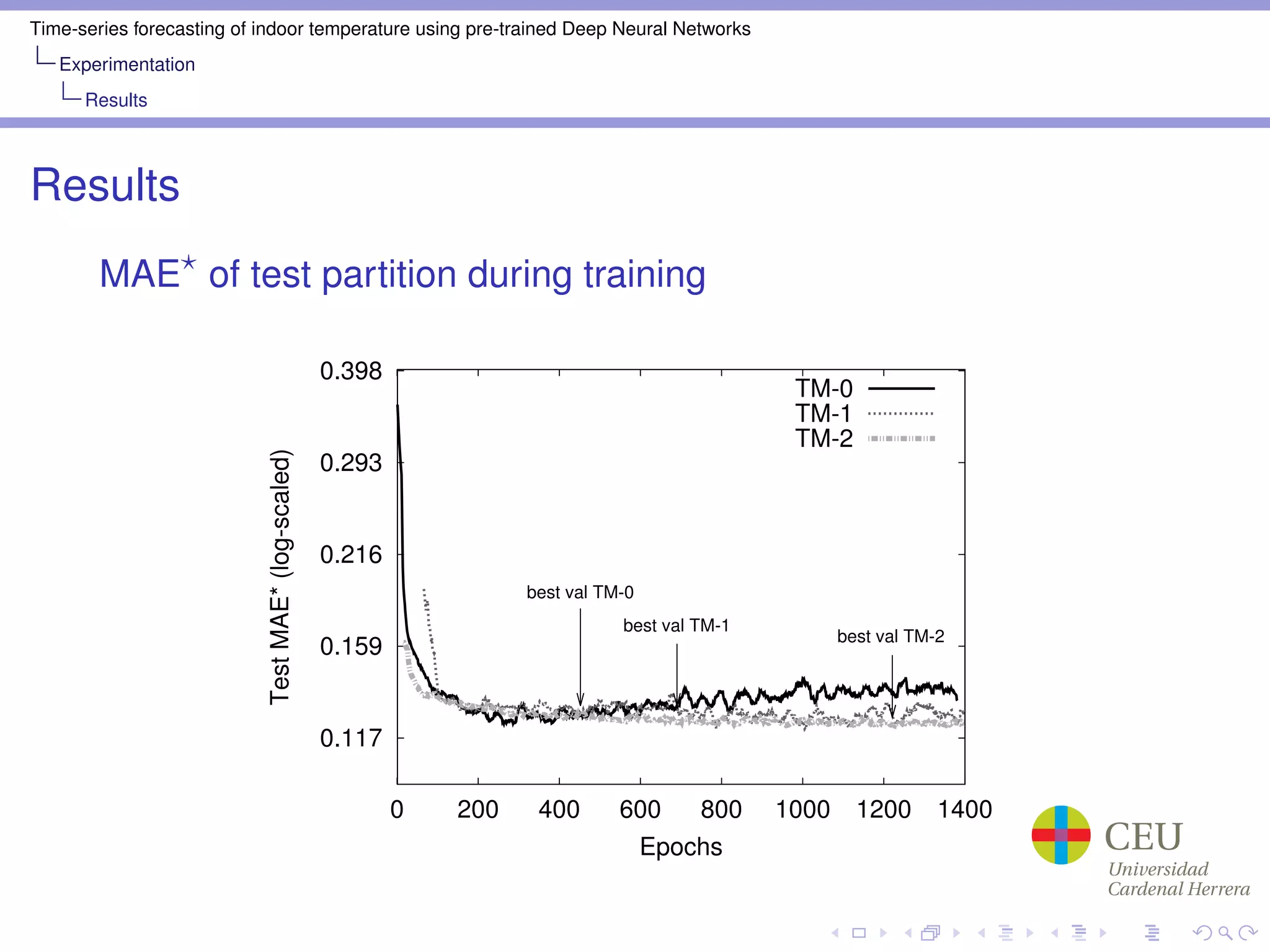
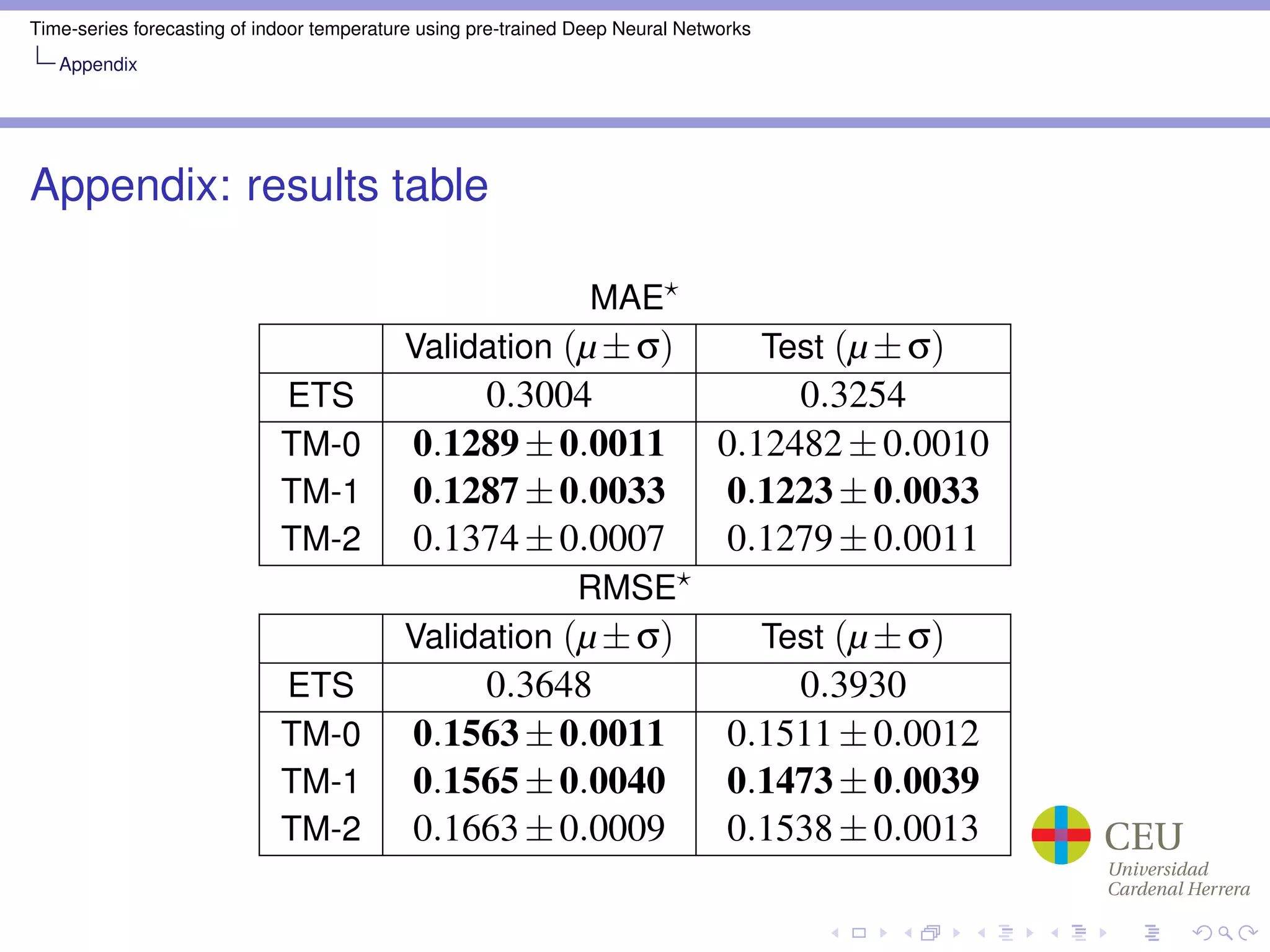
Train Mode: TM-0, TM-1, TM-2
Number of hidden layers: 1, 2, 3
Mask Noise: 0.02, 0.04, 0.10, 0.20
Random search part
100 random trials for every grid sweep
Input size: 12, 24, 36, 48, 60, 72, 84, 96
Learning rate: [10−3
,10−2
]
Momentum: ∼ N (10−3
,5×10−3
), ignoring negative values
Weight decay: [0,10−5
]
Hidden layer sizes: [4,1024]](https://image.slidesharecdn.com/2013icann-traspas-130911021253-phpapp01/75/Time-series-forecasting-of-indoor-temperature-using-pre-trained-Deep-Neural-Networks-24-2048.jpg)

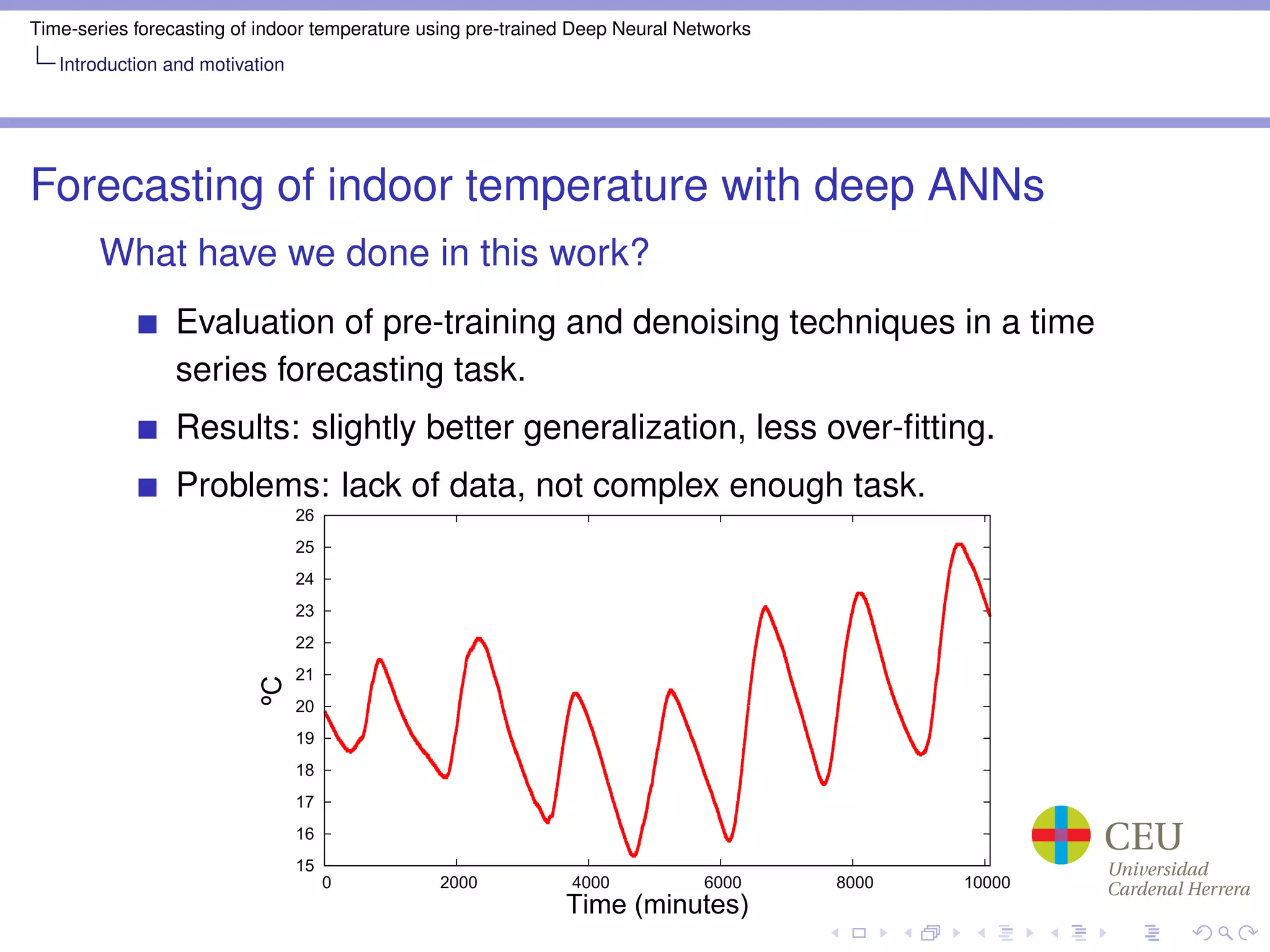
The document discusses time-series forecasting of indoor temperature using pre-trained deep neural networks, focusing on techniques such as stacked denoising auto-encoders and various training methods. Experiments showed improved generalization and less overfitting with pre-training, although limitations like sparse data were noted. Future work aims to enhance forecasting by increasing input window size and employing multivariate models.

















![[PR12] PR-050: Convolutional LSTM Network: A Machine Learning Approach for Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/pr12-convlstm-171126135417-thumbnail.jpg?width=640&height=640&fit=bounds)


























































