시스템 생명 주기(SystemLife Cycle)요구사항(requirement)프로젝트들의 목적을 정의한 명세들의 집합입력과 출력에 관한 정보를 기술분석(analysis)문제들을 다룰 수 있는 작은 단위들로 나눔상향식(bottom-up)/하향식(top-down) 접근 방법설계(design)추상 데이타 타입(abstract data type) 생성알고리즘 명세와 설계 기법 고려2
3.
시스템 생명 주기(SystemLife Cycle)세분화와 코딩(refinement and coding)데이타 객체에 대한 표현 선택수행되는 연산에 대한 알고리즘 작성검증(verification)정확성 증명(correctness proof)수학적 기법들을 이용해서 증명테스트(testing)프로그램의 정확한 수행 검증 – 테스트데이터프로그램의 성능 검사독립적 단위로 테스트(unit testing) 후 전체 시스템으로 통합 (integration testing)black-box testingTesting a program or function based on the possible input values, treating the code as a “black box”clear(white)-box testing: Testing a program or function based on covering all of the branches or paths of the code3
4.
시스템 생명 주기(SystemLife Cycle)오류 제거(error removal)문법오류(syntax error)와 논리오류(logic error)독립적 단위로 테스트(unit testing) 후 전체 시스템으로 통합 (integration testing)유지보수(Maintenance)4
5.
객체 지향 설계구조적프로그래밍 설계와의 비교유사점분할-정복 기법 : 복잡한 문제를 여러개의 단순한 부분 작업으로 나누어 각각을 개별적으로 해결차이점과제 분할 방법 5
6.
알고리즘적 분해와 객체지향적 분해알고리즘적 분해(함수적 분해)고전적 프로그래밍 기법소프트웨어를 기능적 모듈로 분해Pascal의 프로시저, FORTRAN의 서브프로그램, C의 함수객체 지향적 분해응용 분야의 개체를 모델링하는 객체의 집합소프트웨어의 재사용성 조장변화에 유연한 소프트웨어 시스템직관적6
7.
객체 지향 프로그래밍의기본 정의와 개념객체(object)계산을 수행하고 상태를 갖는 개체데이타 + 절차적 요소객체 지향 프로그래밍(object-oriented programming)객체는 기본적인 구성 단위(building block)각 객체는 어떤 타입(클래스)의 인스턴스(instance)클래스는 상속 (inheritance)관계로 연관됨객체 지향 언어(object-oriented language)객체 지원모든 객체는 클래스에 속함상속 지원객체 기반 언어(object-based language)객체와 클래스는 지원하되 상속은 지원하지 않는 언어7
8.
프로그래밍 언어의 발전과C++의 역사고급 프로그래밍 언어1세대 언어 - FORTRAN수식 계산 가능2세대 언어 - Pascal, C알고리즘을 효과적으로 표현3세대 언어 - Modula 추상 데이타 타입 개념 도입4세대 언어(객체 지향 언어) - Smalltalk, Objective-C, C++상속 기능 지원C의 장점효율성(efficient) : 하드웨어를 직접 제어할 수 있는 기능 유연성(flexible) : 대부분의 응용 분야에 사용 가능가용성(available) : 모든 컴퓨터에 C 컴파일러 존재8
9.
데이타 추상화와 캡슐화데이타캡슐화(data encapsulation)정보 은닉(information hiding)외부로부터 데이타 객체의 자세한 구현을 은닉데이타 추상화(data abstraction)객체의 명세(specification)와 구현(implementation)을 분리무엇(what)과 어떻게(how)를 명확하게 구분9
10.
데이타 타입데이타 타입(datatype)객체(object)들과 이 객체들에 대한 연산(operation)의 집합C++의 데이타 타입기본 데이타 타입Char, int, float, double 등타입 수식어 : short, long, signed, unsigned파생 데이타 타입포인터(pointer) 타입, 참조(reference) 타입데이타를 묶어주는 구조배열(array), 구조(struct), 클래스(class)사용자 정의 데이타 타입추상 데이타 타입(abstract data type; ADT)객체와 연산에 대한 명세가 객체의 표현과 연산의 구현으로부터 분리된 방식으로 구성된 데이타 타입10
11.
데이타 추상화와 데이타캡슐화의 장점소프트웨어 개발의 간소화복잡한 작업을 부분 작업들로 분해테스트와 디버깅각 부분 작업을 독자적으로 테스팅, 디버깅재사용성자료 구조에 대한 코드와 연산을 추출해서 다른 소프트웨어 시스템에서도 사용데이타 타입의 표현에 대한 수정데이타 타입의 내부 구현에 직접 접근하는 연산들만 수정11
12.
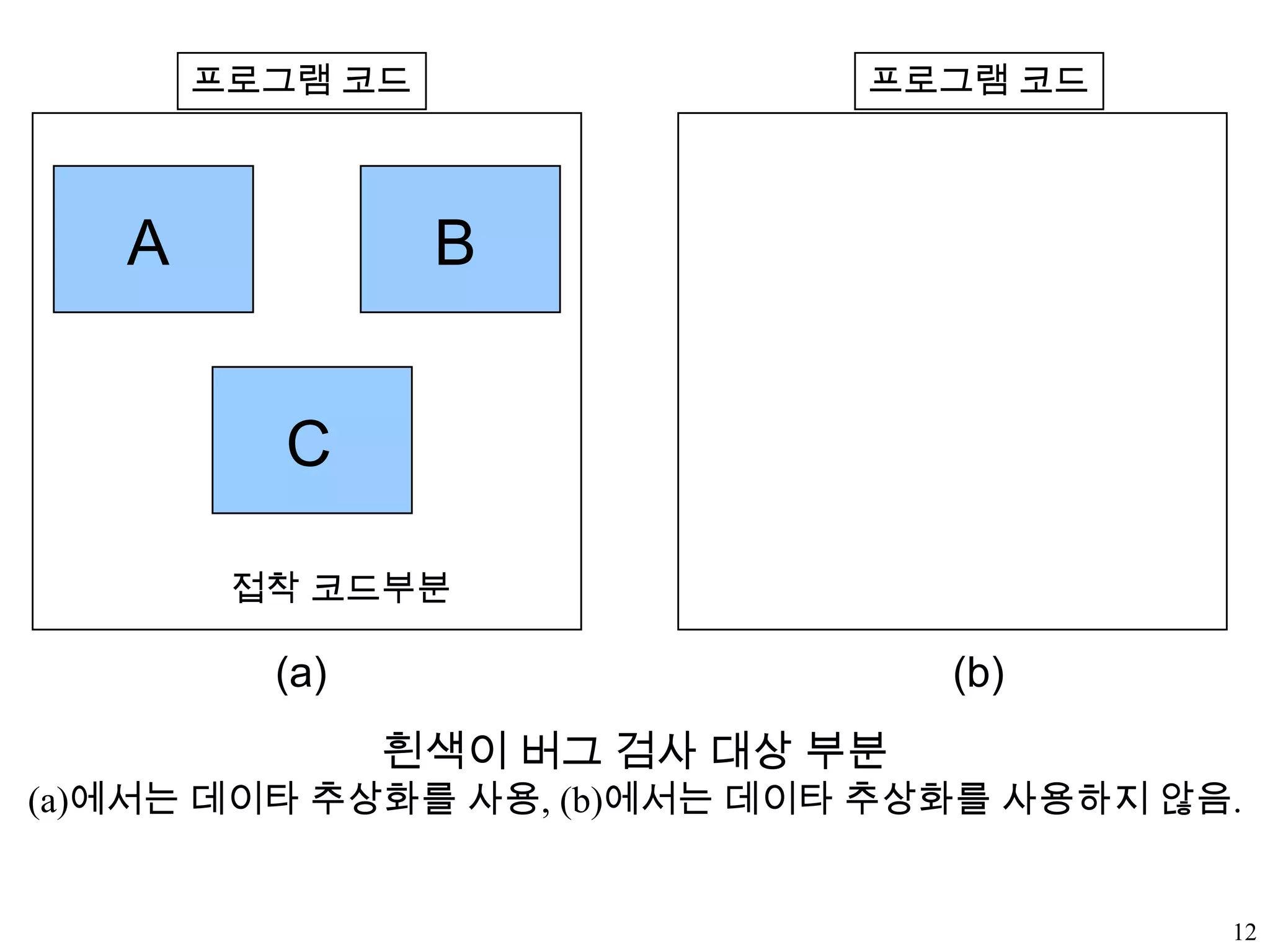
12프로그램 코드프로그램 코드ABC접착코드부분(a)(b)흰색이 버그 검사 대상 부분(a)에서는 데이타 추상화를 사용, (b)에서는 데이타 추상화를 사용하지 않음.
13.
C++의 기초C++ 프로그램의구성헤더 화일.h 접미사선언 저장에 사용시스템/사용자 정의 화일전처리기 명령 #include를 사용하여 화일에 포함시킴소스 화일.C 접미사소스 코드 저장에 사용프로그램의 실행컴파일 -> 링크 -> 적재헤더 화일 중복 방지13#ifdef FILENAME_H#define FILENAME_H//헤더 화일 내용 삽입...#endif
14.
C++에서의 영역 (Scope)화일영역함수 정의에 속하지 않은 선언,클래스 정의, 네임스페이스네임스페이스 영역네임스페이스(namespace)논리적으로 연관된 변수나 함수를 한 그룹으로 만드는 기법영역 정보를 사용해서 네임스페이스 안의 개체에 접근예) std::cout지역 영역블록 안에서 선언된 이름클래스 영역클래스 정의에 관련된 선언14
15.
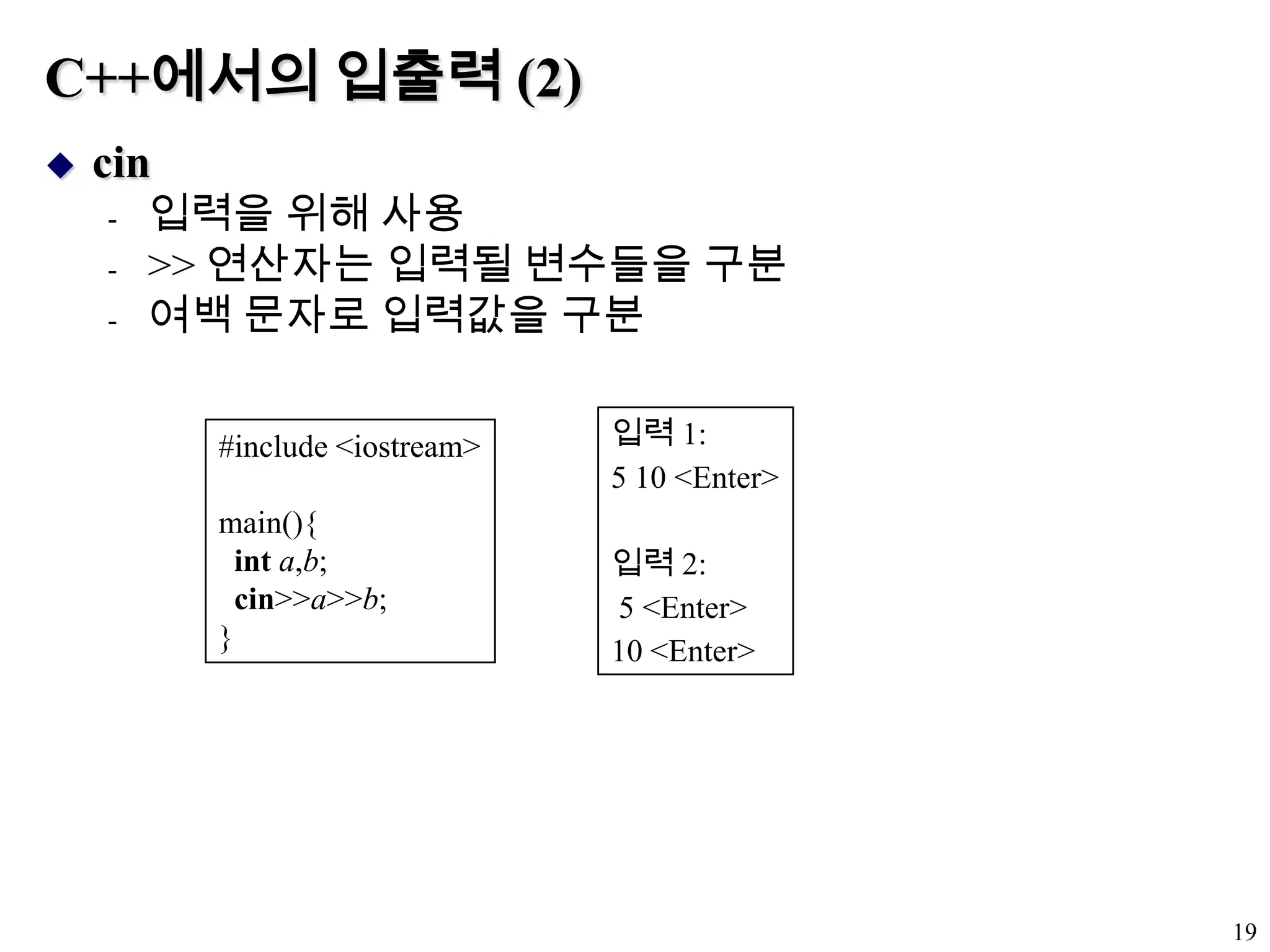
C++ 명령문과 연산자C++명령문C와 같은 문법과 의미C++ 연산자new, delete 제외하고 C의 연산자와 동일C++의 입출력왼편/ 오른편 시프트 연산자(<<, >>) 사용C와 C++의 중요한 차이점연산자 다중화(operator overloading) 허용15
16.
C++ 데이타 선언데이타선언 : 한 데이타 타입을 어떤 이름에 연결상수 값변수 : 데이타 타입의 인스턴스상수 변수 : 선언시에 내용이 고정const int MAX=500;열거 타입 : 일련의 정수 상수를 선언enumsemester{SUMMER, FALL, SPRING};포인터 : 객체의 메모리 주소 저장int i=25;int *np;np = &i;참조 타입 : 객체에 대한 또 다른 이름을 제공int i=5;int& j=i;i=7;printf(“i=%d, j=%d”, i, j); i=7, j=716
C++의 함수정규 함수멤버함수: 특정 클래스와 연관된 함수함수의 구성함수 이름인자 리스트 (시그너처(입력))반환 타입(출력)몸체(함수를 구현한 코드)21Max : 함수 이름inta, intb : 인자 리스트int : 반환 타입{와}사이 : 함수 몸체intMax(inta, intb){if (a > b) returna;elsereturnb;}
22.
C++의 매개변수 전달값(value)에의한 전달전달된 객체는 그 함수의 지역 저장소에 복사실인자에 영향을 주지 않음실인자로 제공되는 변수가 함수에 의해 변경되지 않음참조(reference)에 의한 전달인자 리스트의 타입 명세자에 & 첨가전달된 객체의 주소만 함수의 지역 저장소에 복사실인자에 접근전달된 객체가 큰 메모리를 요구하는 경우 더 빨리 수행상수 참조 (constant reference) 인자 변경 불가const T& a배열은 참조로 전달22
23.
C++의 함수 이름다중화함수 다중화 혹은 함수 중복(function overloading)함수의 시그너처(인자 리스트)가 다르기만 하면 같은 이름을 가진 함수가 둘 이상 존재할 수 있음e.g.intMax(int,int);intMax(int, int, int);intMax(int*, int);intMax(float, int);intMax(int, float);23
C++에서의 동적 메모리할당new / delete 연산자 실행 시간에 자유 저장소를 할당받거나 반환new 연산자원하는 타입의 객체를 생성하고 그에 대한 포인터를 반환생성할 수 없으면 예외 발생delete 연산자new로 생성된 객체에게 할당된 기억 장소를 반환e.g.25int *ip = new int; . .deleteip;int *jp = new int[10]; //jp는 정수 배열. .delete [] jp;
26.
예외 발생오류와 다른특별한 조건이 발생했음을 알리는데 사용다양한 예외 각각에 대해 예외 클래스를 정의e.g26intDivZero(inta, intb, intc) { if (a <= 0∥b <= 0 ∥c <= 0) throw "All parameters should be >0”; return a + b * c + b / c; }
27.
예외 처리try 블록에발생될 수 있는 예외를 포함시켜서 처리try 블록 뒤에는 0개 이상의 catch 블록각 catch 블록은 예외 타입을 나타내는 한 인자를 가짐catch (char* e){} catch (bad_alloce){} catch (...){} 27
28.
알고리즘 명세알고리즘 (algorithm)특정작업을 수행하는 명령어들의 유한 집합알고리즘의 요건입력 : 외부에서 제공되는 데이타가 0개 이상출력 : 적어도 한 개 이상의 결과 생성명확성 : 각 명령은 명확하고 모호하지 않아야 함유한성 : 알고리즘대로 수행하면 어떤 경우에도 반드시 종료유효성 : 반드시 실행 가능해야 함알고리즘 기술 방법자연어흐름도(flowchart)C++언어28
29.
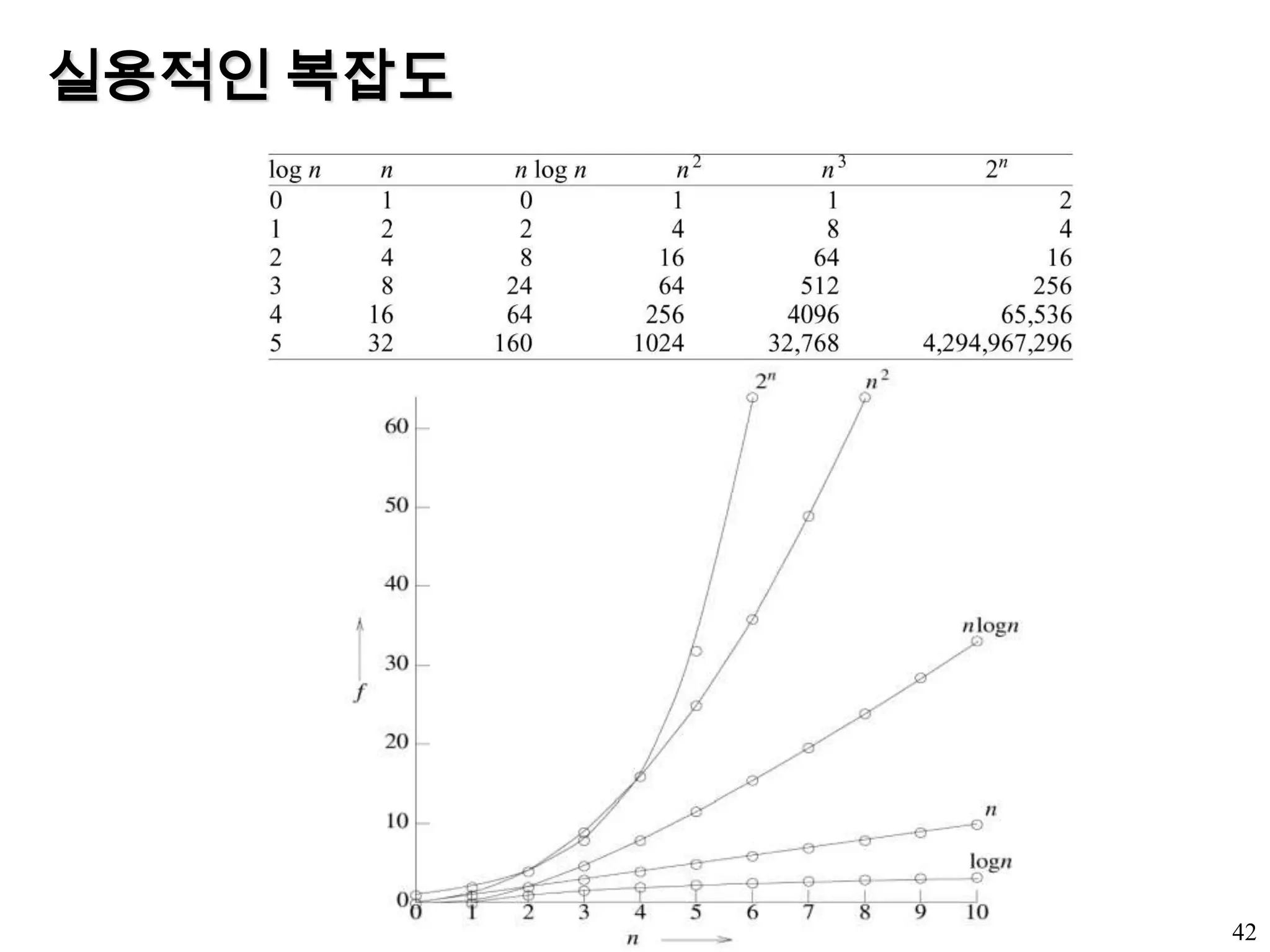
성능 분석과 측정(1)프로그램의 평가 기준우리가 원하는 작업을 하는가?원래 작업의 명세에 부합해서 정확히 작동하는가?문서화가 되어 있는가?논리적 작업 단위를 수행하는 기준으로 함수가 생성되었는가?코드가 읽기 쉬운가?성능 평가(performance evaluation)성능 분석 (performance analysis)사전 예측성능 측정 (performance measurement)이후 검사29
30.
공간 복잡도 (1)공간복잡도(space complexity)프로그램을 실행시켜 완료하는 데 필요한 메모리 양고정 부분보통 명령어 공간, 단순 변수, 집합체, 상수를 위한 공간가변 부분변수, 참조된 변수가 필요로 하는 공간, 순환 스택 공간프로그램 P의 공간 요구 S(P) = c + SPc : 상수SP : 인스턴스 특성문제에 의존인스턴스로 인해 필요로 하는 공간30
31.
공간 복잡도 (2)a,b,c값 각각을 저장하고 Abc에서 값을 반환하는데 한 워드가 필요하다고 가정SP = 0SSum(n) = 031float Abc(float a, float b, float c){returna+b+b*c+(a+b-c)/(a+b)+4.0;}line float Sum(float *a, const int n){ float s = 0;for(inti = 0 ; i < n ; i++)s+= a[i];returns;}
32.
공간 복잡도(3)RSum을 호출할때마다 적어도 네 개의 워드(n과 a 값, 반환 값, 반환 주소에 필요한 공간 포함)순환 깊이가 n+1이므로 순환 스택 공간에 4(n+1)32line floatRsum(float *a, const intn){if(n<=0) return 0;else return(Rsum(a, n-1) + a[n-1]);}
33.
시간 복잡도 (1)시간복잡도프로그램을 완전히 실행시키는데 필요한 시간T(P) = 컴파일 시간 +실행시간(tP(인스턴스 특성))tP(n) = caADD(n)+csSUB(n)+cmMUL(n)+cdDIV(n) + …n : 인스턴스 특성Ca, Cs, Cm, Cd : +, -, x, / 연산을 위한 상수 시간ADD, SUB, MUL, DIV : 특성 n인 인스턴스에서 각 연산의 실행 횟수33
34.
시간 복잡도 (2)프로그램단계 수(number of steps)주석 : 0선언문 : 0변수, 상수 정의(int, long, short, char,...)사용자 데이타 타입 정의(class, struct, union, template)접근 결정(private, public, protected, friend)함수 타입 결정(void, virtual)산술식 및 지정문 : 1예외 : 함수 호출을 포함하는 산술식반복문 : 제어 부분에 대해서만 단계수 고려스위치 명령문switch(<expr>)의 비용 = <expr>의 비용각 조건의 비용 = 자기의 비용 + 앞서 나온 모든 조건의 비용if-else 문<expr>, <statement1>, <statement2>에 따라 각각 단계수가 할당34
35.
시간 복잡도 (3)프로그램단계 수(number of steps)함수 호출값에 의한 전달 인자 포함하지 않을 경우 : 1값에 인한 전달 인자 포함할 경우 : 값 인자 크기의 합순환적인 경우 : 호출되는 함수의 지역 변수도 고려메모리 관리 명령문 : 1함수 명령문 : 0비용이 이미 호출문에 할당분기 명령문 : 135
36.
단계 수 테이블명령문의실행당 단계 수(s/e : step per execution) 결정s/e : 그 명령문의 실행 결과로 count가 변화하는 양명령문이 실행되는 총 횟수 계산36line floatSum(float * a, const intn){floats = 0;for(inti = 0 ; i < n ; i++)s+= a[i];returns;}
성능 측정(1)프로그램의 공간및 시간 요구량을 구하는 것순차 탐색 함수에 대한 최악의 경우 성능 측정시간을 측정할 n의 값들 결정n의 값들에 대해서 최악의 성질을 가진 데이타 결정점근적 해석 : Θ(n)작은 n 값, 무시된 저차 항들의 영향에 의해 정확하지 않을 수 있음43intSequentialSearch (int *a, const intn, const intx){// a[0:n-1]에 대해 탐색inti;for(i=0; i<n && a[i] != x; i++);if(i==n) return -1;else returni;}
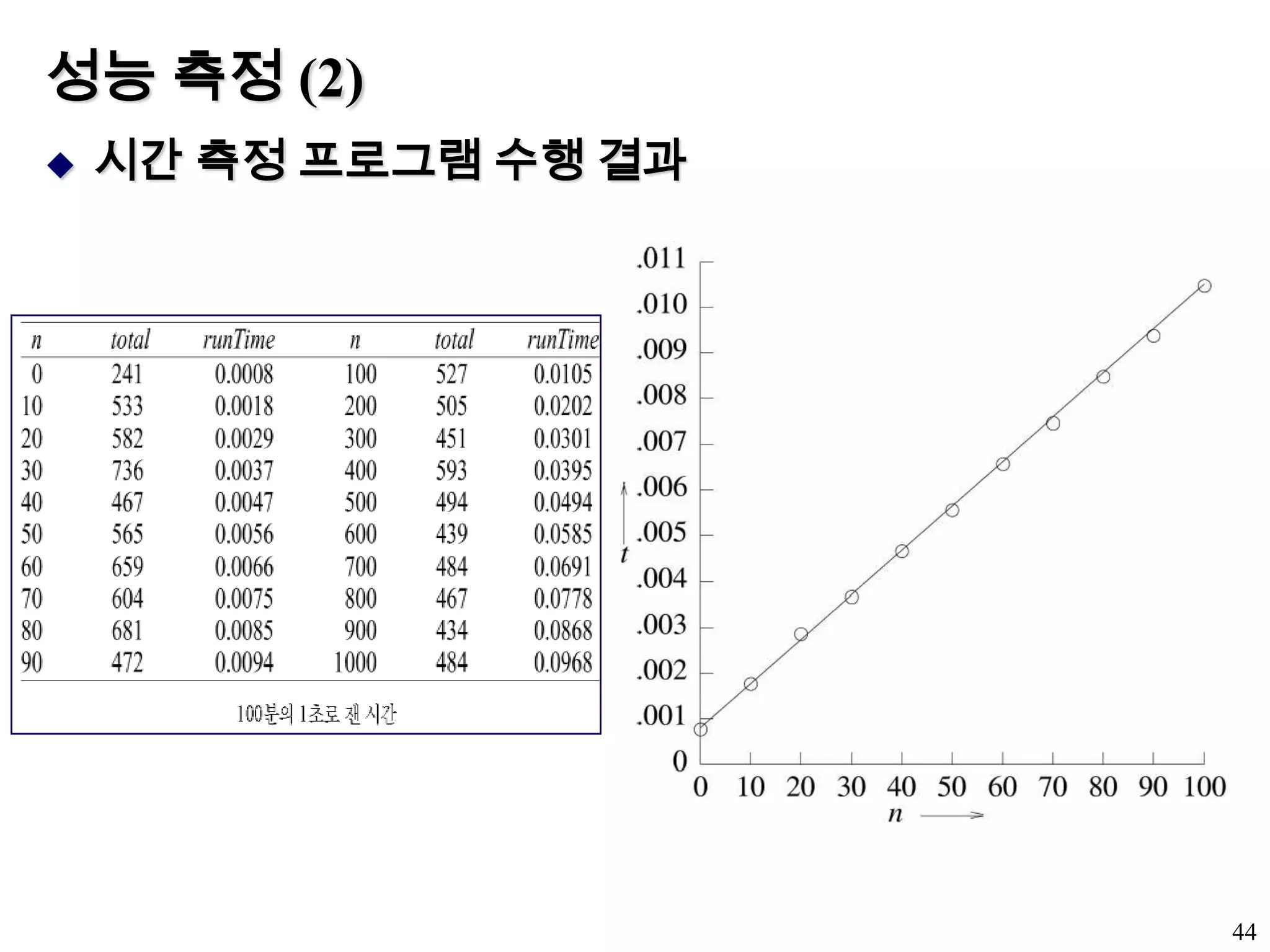
테스트 데이타의 생성최악의성능을 초래하는 데이타 세트 생성관심 있는 인스턴스 특성 값들에 대해 적당한 대규모의 무작위 테스트 데이타 생성생성한 테스트 데이타 각각에 대해 실행 시간 측정이들 시간의 최대 값을 최악의 경우의 시간으로 사용평균인 경우의 시간 측정주어진 특성의 모든 가능한 인스턴스에 대한 평균위에 언급된 기법을 사용해서 평균 시간의 어림값 계산실험을 위해 생성되어야 할 데이타들을 결정하기 위해 사용되는 알고리즘을 분석하는 것이 바람직45























![C++에서의 동적 메모리 할당new / delete 연산자 실행 시간에 자유 저장소를 할당받거나 반환new 연산자원하는 타입의 객체를 생성하고 그에 대한 포인터를 반환생성할 수 없으면 예외 발생delete 연산자new로 생성된 객체에게 할당된 기억 장소를 반환e.g.25int *ip = new int; . .deleteip;int *jp = new int[10]; //jp는 정수 배열. .delete [] jp;](https://image.slidesharecdn.com/2-110513010502-phpapp01/75/2-25-2048.jpg)





![공간 복잡도 (2)a,b,c 값 각각을 저장하고 Abc에서 값을 반환하는데 한 워드가 필요하다고 가정SP = 0SSum(n) = 031float Abc(float a, float b, float c){returna+b+b*c+(a+b-c)/(a+b)+4.0;}line float Sum(float *a, const int n){ float s = 0;for(inti = 0 ; i < n ; i++)s+= a[i];returns;}](https://image.slidesharecdn.com/2-110513010502-phpapp01/75/2-31-2048.jpg)
![공간 복잡도(3)RSum을 호출할 때마다 적어도 네 개의 워드(n과 a 값, 반환 값, 반환 주소에 필요한 공간 포함)순환 깊이가 n+1이므로 순환 스택 공간에 4(n+1)32line floatRsum(float *a, const intn){if(n<=0) return 0;else return(Rsum(a, n-1) + a[n-1]);}](https://image.slidesharecdn.com/2-110513010502-phpapp01/75/2-32-2048.jpg)



![단계 수 테이블명령문의 실행당 단계 수(s/e : step per execution) 결정s/e : 그 명령문의 실행 결과로 count가 변화하는 양명령문이 실행되는 총 횟수 계산36line floatSum(float * a, const intn){floats = 0;for(inti = 0 ; i < n ; i++)s+= a[i];returns;}](https://image.slidesharecdn.com/2-110513010502-phpapp01/75/2-36-2048.jpg)





![성능 측정(1)프로그램의 공간 및 시간 요구량을 구하는 것순차 탐색 함수에 대한 최악의 경우 성능 측정시간을 측정할 n의 값들 결정n의 값들에 대해서 최악의 성질을 가진 데이타 결정점근적 해석 : Θ(n)작은 n 값, 무시된 저차 항들의 영향에 의해 정확하지 않을 수 있음43intSequentialSearch (int *a, const intn, const intx){// a[0:n-1]에 대해 탐색inti;for(i=0; i<n && a[i] != x; i++);if(i==n) return -1;else returni;}](https://image.slidesharecdn.com/2-110513010502-phpapp01/75/2-43-2048.jpg)





![[C++ Korea 2nd Seminar] C++17 Key Features Summary](https://cdn.slidesharecdn.com/ss_thumbnails/ckorea2ndseminarc17keyfeaturessummary-publish-160529025757-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Td 2015]녹슨 c++ 코드에 모던 c++로 기름칠하기(옥찬호)](https://cdn.slidesharecdn.com/ss_thumbnails/td2015cc-151104051810-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[KGC 2012]Boost.asio를 이용한 네트웍 프로그래밍](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2012boost-asio-121011023325-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[C++ Korea 3rd Seminar] 새 C++은 새 Visual Studio에, 좌충우돌 마이그레이션 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/ckorea3rdseminarcvisualstudio-170218150400-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Main Session] 미래의 Java 미리보기 - 앰버와 발할라 프로젝트를 중심으로](https://cdn.slidesharecdn.com/ss_thumbnails/java-180320135253-thumbnail.jpg?width=640&height=640&fit=bounds)






![[devil's camp] - 알고리즘 대회와 STL (박인서)](https://cdn.slidesharecdn.com/ss_thumbnails/stl-160830021024-thumbnail.jpg?width=640&height=640&fit=bounds)


















































