Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SN
Uploaded by
Shuyo Nakatani
PDF, PPTX
10,176 views
国際化時代の40カ国語言語判定
言語判定とは、テキストが何語で書かれたものか推定することです。 99.8%の精度で49言語の判定可能なJavaライブラリを開発、オープンソースとして公開しました。
Technology
◦
Read more
10
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 32
2
/ 32
3
/ 32
4
/ 32
5
/ 32
6
/ 32
7
/ 32
8
/ 32
9
/ 32
10
/ 32
11
/ 32
12
/ 32
13
/ 32
14
/ 32
15
/ 32
16
/ 32
17
/ 32
18
/ 32
19
/ 32
20
/ 32
21
/ 32
22
/ 32
23
/ 32
24
/ 32
25
/ 32
26
/ 32
27
/ 32
28
/ 32
29
/ 32
30
/ 32
31
/ 32
32
/ 32
More Related Content
PDF
Language Detection Library for Java
by
Shuyo Nakatani
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
PPTX
情報検索とゼロショット学習
by
kt.mako
PDF
【DL輪読会】NeRF-VAE: A Geometry Aware 3D Scene Generative Model
by
Deep Learning JP
PDF
GoによるiOSアプリの開発
by
Takuya Ueda
PPTX
ホモトピー型理論入門
by
k h
PDF
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
PDF
Bert for multimodal
by
Yasuhide Miura
Language Detection Library for Java
by
Shuyo Nakatani
マルチモーダル深層学習の研究動向
by
Koichiro Mori
情報検索とゼロショット学習
by
kt.mako
【DL輪読会】NeRF-VAE: A Geometry Aware 3D Scene Generative Model
by
Deep Learning JP
GoによるiOSアプリの開発
by
Takuya Ueda
ホモトピー型理論入門
by
k h
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
Bert for multimodal
by
Yasuhide Miura
What's hot
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PDF
いまさら聞けないselectあれこれ
by
lestrrat
PDF
BERTology のススメ
by
University of Tsukuba
PDF
SSII2022 [OS3-02] Federated Learningの基礎と応用
by
SSII
PDF
Action Recognitionの歴史と最新動向
by
Ohnishi Katsunori
PDF
Pythonによる黒魔術入門
by
大樹 小倉
PDF
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
PPTX
【論文読み会】Autoregressive Diffusion Models.pptx
by
ARISE analytics
PDF
人間の視覚的注意を予測するモデル - 動的ベイジアンネットワークに基づく 最新のアプローチ -
by
Akisato Kimura
PDF
Crfと素性テンプレート
by
Kei Uchiumi
PDF
[DL輪読会]SlowFast Networks for Video Recognition
by
Deep Learning JP
PDF
明日使えないすごいビット演算
by
京大 マイコンクラブ
PDF
(DL hacks輪読) Variational Dropout and the Local Reparameterization Trick
by
Masahiro Suzuki
PDF
NLP2019 松田寛 - GiNZA
by
Megagon Labs
PDF
3次元レジストレーション(PCLデモとコード付き)
by
Toru Tamaki
PPTX
Graph convolution (スペクトルアプローチ)
by
yukihiro domae
PDF
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
PDF
F#入門 ~関数プログラミングとは何か~
by
Nobuhisa Koizumi
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
Attentionの基礎からTransformerの入門まで
by
AGIRobots
いまさら聞けないselectあれこれ
by
lestrrat
BERTology のススメ
by
University of Tsukuba
SSII2022 [OS3-02] Federated Learningの基礎と応用
by
SSII
Action Recognitionの歴史と最新動向
by
Ohnishi Katsunori
Pythonによる黒魔術入門
by
大樹 小倉
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
【論文読み会】Autoregressive Diffusion Models.pptx
by
ARISE analytics
人間の視覚的注意を予測するモデル - 動的ベイジアンネットワークに基づく 最新のアプローチ -
by
Akisato Kimura
Crfと素性テンプレート
by
Kei Uchiumi
[DL輪読会]SlowFast Networks for Video Recognition
by
Deep Learning JP
明日使えないすごいビット演算
by
京大 マイコンクラブ
(DL hacks輪読) Variational Dropout and the Local Reparameterization Trick
by
Masahiro Suzuki
NLP2019 松田寛 - GiNZA
by
Megagon Labs
3次元レジストレーション(PCLデモとコード付き)
by
Toru Tamaki
Graph convolution (スペクトルアプローチ)
by
yukihiro domae
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
F#入門 ~関数プログラミングとは何か~
by
Nobuhisa Koizumi
Viewers also liked
PDF
情報推薦システム入門:講義スライド
by
Kenta Oku
PDF
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
PPTX
Deep forest
by
naoto moriyama
PDF
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013
by
Shuyo Nakatani
PDF
RecSys 2015: Large-scale real-time product recommendation at Criteo
by
Romain Lerallut
PDF
Latent factor models for Collaborative Filtering
by
sscdotopen
PDF
JP Chaosmap 2015-2016
by
Hiroshi Kondo
PDF
Ensembles of example dependent cost-sensitive decision trees slides
by
Alejandro Correa Bahnsen, PhD
情報推薦システム入門:講義スライド
by
Kenta Oku
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
Deep forest
by
naoto moriyama
どの言語でつぶやかれたのか、機械が知る方法 #WebDBf2013
by
Shuyo Nakatani
RecSys 2015: Large-scale real-time product recommendation at Criteo
by
Romain Lerallut
Latent factor models for Collaborative Filtering
by
sscdotopen
JP Chaosmap 2015-2016
by
Hiroshi Kondo
Ensembles of example dependent cost-sensitive decision trees slides
by
Alejandro Correa Bahnsen, PhD
Similar to 国際化時代の40カ国語言語判定
PDF
∞-gram を使った短文言語判定
by
Shuyo Nakatani
PDF
言語資源と付き合う
by
Yuya Unno
PDF
ナイーブベイズによる言語判定
by
Shuyo Nakatani
PDF
R による文書分類入門
by
Takeshi Arabiki
PDF
機械翻訳の今昔物語
by
Hiroshi Nakagawa
PDF
スペル修正プログラムの作り方 #pronama
by
Hiroyoshi Komatsu
PDF
極大部分文字列を使った twitter 言語判定
by
Shuyo Nakatani
PDF
ソーシャルメディアの多言語判定 #SoC2014
by
Shuyo Nakatani
PDF
Session2:「グローバル化する情報処理」/伊藤敬彦
by
Preferred Networks
PDF
数
by
Koichi Taniguchi
PDF
鬱くしい日本語のための形態素解析入門
by
Hiroyoshi Komatsu
PDF
人間言語判別 カタルーニャ語編
by
Shuyo Nakatani
PPTX
英語学習者のための発話自動採点システムの開発.
by
Yutaka Ishii
PDF
言語判定へのいざない
by
Shuyo Nakatani
PPTX
Jacet2014ykondo_final
by
早稲田大学
PDF
Segmenting Sponteneous Japanese using MDL principle
by
Yusuke Matsubara
PPTX
COLING2014 読み会@小町研 “Morphological Analysis for Japanese Noisy Text Based on C...
by
Yuki Tomo
PDF
A scalable probablistic classifier for language modeling: ACL 2011 読み会
by
正志 坪坂
PDF
構文情報に基づく機械翻訳のための能動学習手法と人手翻訳による評価
by
Akiva Miura
PDF
Paraphrasing Swedish Compound Nouns in Machine Translation
by
Hiroshi Matsumoto
∞-gram を使った短文言語判定
by
Shuyo Nakatani
言語資源と付き合う
by
Yuya Unno
ナイーブベイズによる言語判定
by
Shuyo Nakatani
R による文書分類入門
by
Takeshi Arabiki
機械翻訳の今昔物語
by
Hiroshi Nakagawa
スペル修正プログラムの作り方 #pronama
by
Hiroyoshi Komatsu
極大部分文字列を使った twitter 言語判定
by
Shuyo Nakatani
ソーシャルメディアの多言語判定 #SoC2014
by
Shuyo Nakatani
Session2:「グローバル化する情報処理」/伊藤敬彦
by
Preferred Networks
数
by
Koichi Taniguchi
鬱くしい日本語のための形態素解析入門
by
Hiroyoshi Komatsu
人間言語判別 カタルーニャ語編
by
Shuyo Nakatani
英語学習者のための発話自動採点システムの開発.
by
Yutaka Ishii
言語判定へのいざない
by
Shuyo Nakatani
Jacet2014ykondo_final
by
早稲田大学
Segmenting Sponteneous Japanese using MDL principle
by
Yusuke Matsubara
COLING2014 読み会@小町研 “Morphological Analysis for Japanese Noisy Text Based on C...
by
Yuki Tomo
A scalable probablistic classifier for language modeling: ACL 2011 読み会
by
正志 坪坂
構文情報に基づく機械翻訳のための能動学習手法と人手翻訳による評価
by
Akiva Miura
Paraphrasing Swedish Compound Nouns in Machine Translation
by
Hiroshi Matsumoto
More from Shuyo Nakatani
PDF
言語処理するのに Python でいいの? #PyDataTokyo
by
Shuyo Nakatani
PDF
アラビア語とペルシャ語の見分け方 #DSIRNLP 5
by
Shuyo Nakatani
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
Short Text Language Detection with Infinity-Gram
by
Shuyo Nakatani
PDF
Zipf? (ジップ則のひみつ?) #DSIRNLP
by
Shuyo Nakatani
PDF
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
Generative adversarial networks
by
Shuyo Nakatani
PDF
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
ドラえもんでわかる統計的因果推論 #TokyoR
by
Shuyo Nakatani
PDF
無限関係モデル (続・わかりやすいパターン認識 13章)
by
Shuyo Nakatani
PDF
猫に教えてもらうルベーグ可測
by
Shuyo Nakatani
PDF
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
by
Shuyo Nakatani
PDF
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...
by
Shuyo Nakatani
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
PDF
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...
by
Shuyo Nakatani
PDF
人工知能と機械学習の違いって?
by
Shuyo Nakatani
PDF
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...
by
Shuyo Nakatani
言語処理するのに Python でいいの? #PyDataTokyo
by
Shuyo Nakatani
アラビア語とペルシャ語の見分け方 #DSIRNLP 5
by
Shuyo Nakatani
Active Learning 入門
by
Shuyo Nakatani
Short Text Language Detection with Infinity-Gram
by
Shuyo Nakatani
Zipf? (ジップ則のひみつ?) #DSIRNLP
by
Shuyo Nakatani
画像をテキストで検索したい!(OpenAI CLIP) - VRC-LT #15
by
Shuyo Nakatani
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
ノンパラベイズ入門の入門
by
Shuyo Nakatani
Generative adversarial networks
by
Shuyo Nakatani
数式を綺麗にプログラミングするコツ #spro2013
by
Shuyo Nakatani
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
ドラえもんでわかる統計的因果推論 #TokyoR
by
Shuyo Nakatani
無限関係モデル (続・わかりやすいパターン認識 13章)
by
Shuyo Nakatani
猫に教えてもらうルベーグ可測
by
Shuyo Nakatani
RとStanでクラウドセットアップ時間を分析してみたら #TokyoR
by
Shuyo Nakatani
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...
by
Shuyo Nakatani
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...
by
Shuyo Nakatani
人工知能と機械学習の違いって?
by
Shuyo Nakatani
[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...
by
Shuyo Nakatani
Recently uploaded
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
PDF
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
PDF
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PDF
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
PPTX
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
PPTX
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
PDF
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
PDF
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
PDF
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
国際化時代の40カ国語言語判定
1.
国際化時代の 40カ国語 言語判定 WebDB Forum
2010 2010/11/12 中谷 秀洋@サイボウズ・ラボ株式会社
2.
自己紹介 中谷秀洋(なかたに しゅうよう)
サイボウズ・ラボのエンジニア 現在は機械学習/自然言語処理を中心に研究開発 gihyo.jp で連載「機械学習 はじめよう」を担当 ExtractContent (Ruby の Web ページ本文抽出) “ぺけ-BASIC”(X68000)の作者 twitter : @shuyo ( http://twitter.com/shuyo ) ブログ : http://d.hatena.ne.jp/n_shuyo/
3.
サイボウズ サイボウズ株式会社 サイボウズ
Office : 企業内グループウェア サイボウズ Live : 企業間・個人向けグループウェア サイボウズ・ラボ株式会社 サイボウズの100%子会社 Web技術や情報共有をテーマとした、中長期視点 の研究開発 サイボウズの、次の次の製品に役立つような けっこう自由に、けっこう幅広く
4.
早速ですが 問題です。
5.
何語でしょう? sprogregistrering språkgjenkjenning
6.
何語でしょう? デンマーク語 ノルウェー語 sprogregistrering språkgjenkjenning
7.
何語でしょう? اللغة عن الكشف زبان
تشخیص زبانشناخت کی
8.
何語でしょう? アラビア語 ペルシャ語 ウルドゥー語 اللغة عن الكشف زبان
تشخیص زبانشناخت کی
9.
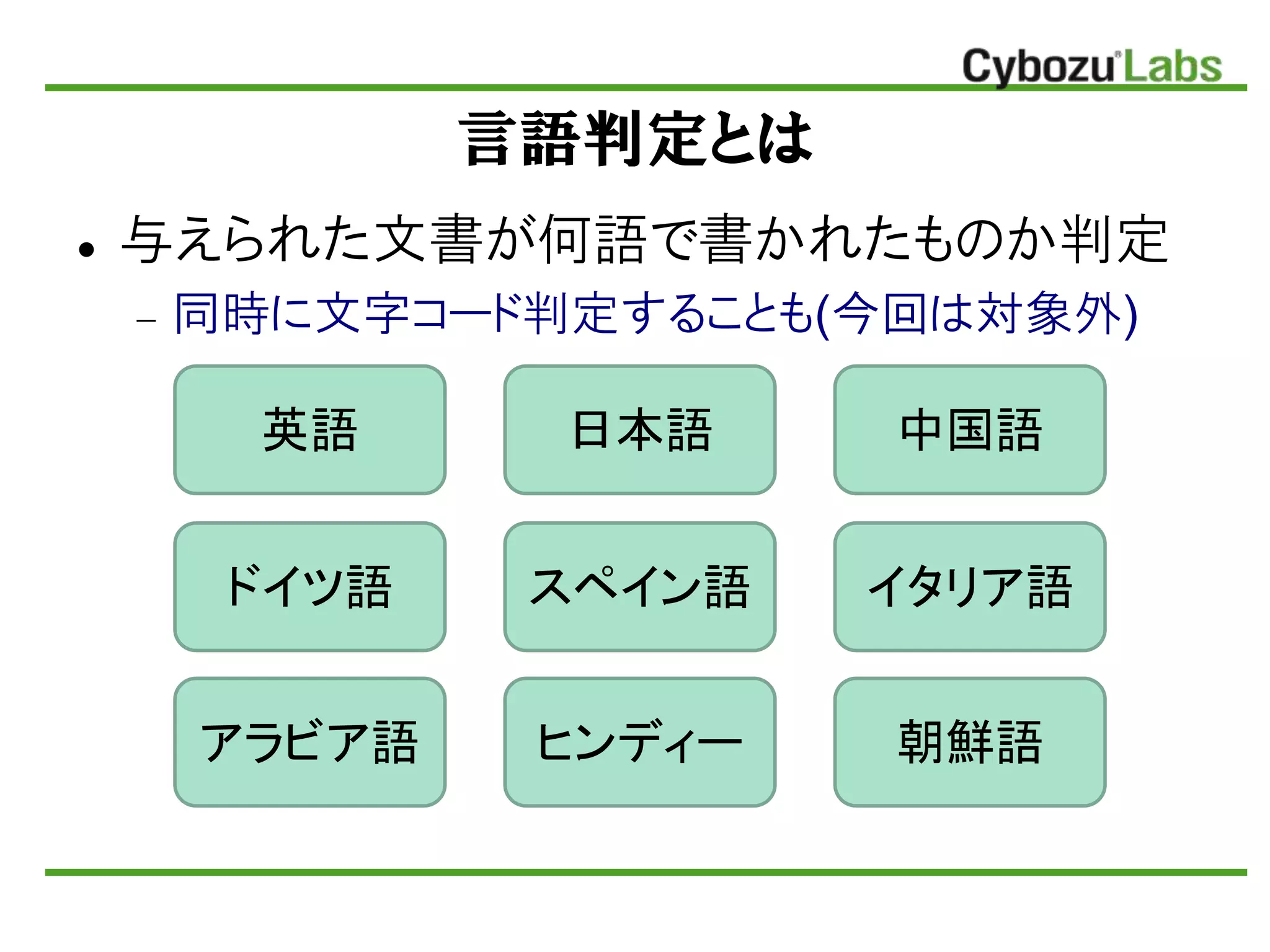
言語判定とは 不えられた文書が何語で書かれたものか判定 同時に文字コード判定することも(今回は対象外) 英語 ドイツ語 日本語
中国語 スペイン語 イタリア語 アラビア語 ヒンディー 朝鮮語
10.
言語判定の方法 サポートする言語が多くなるほど難しい 同じ文字を使う異なる言語は数多い
文字・言語の知識が必要 シンプルな方法: 各言語で使われる単語を辞書で持ち、マッチング 辞書が膨大、変化形・合成語への対応が難しい 今回の方法: 綴り字の特徴量から確率を計算 文字 n-gram を用いたナイーブベイズ
11.
言語判定を何に使う? 利用シーン 検索機能に言語の絞り込みをつけたい
“Java” で検索したら中国語の文書がヒットした! 言語別のフィルタを適用したい(SPAMフィルタとか) 言語固有の情報(句読点、キーワード)を用いる 利用対象 Web検索エンジン Apache Nutch には言語判定モジュールが付属 掲示板 例:日英中越入り交じりの書き込み サイボウズは 日本・上海・ベトナムに 開発チームが!
12.
既存の言語判定 言語判定ライブラリは数少ない ニーズが限られている?
Web検索だけ? でもこれからはグローバル化の時代! コーパス/モデルの構築が高コスト 対象言語の知識が必要 対応言語数が少ない。精度が低い。速度が丌満 おおむね10言語程度。アジア系はサポートなし “Thank you very much. ありがとうございます” →「タガログ語かチェコ語かスロバキア語です」
13.
「実用性」のある言語判定 精度は 99%
以上 “90%” は実用的ではない (1000個のうち100個間違う) サポート言語数は 50 欧文、アジア系言語、幅広く 高速な判定 多数の文書を判定したい 複数候補が考えられる場合は、度合いを返す
14.
言語判定ライブラリ for Java
言語判定を行う Java ライブラリを開発 学習コーパスから言語ごとのプロファイルを生成 プロファイル = 綴り字ごとの確率を計算したもの テキストを不えると、言語の候補と確率を返す ライブラリの対応言語数: 49言語(2010/11 現在) オープンソースとして公開 http://code.google.com/p/language-detection/ Apache License 2.0
15.
性能評価 学習コーパス Wikipedia
より 49言語について学習 Wikipedia は 276 言語対応(2010/11 現在) 対応言語数=テストコーパスを用意できる言語数 テストコーパス 49言語のニュース記事 各 200件 Google News (24言語) 各言語のニュースサイト RSS により収集 ここが一番たいへん! マイナーな言語は RSS配信もされてない
16.
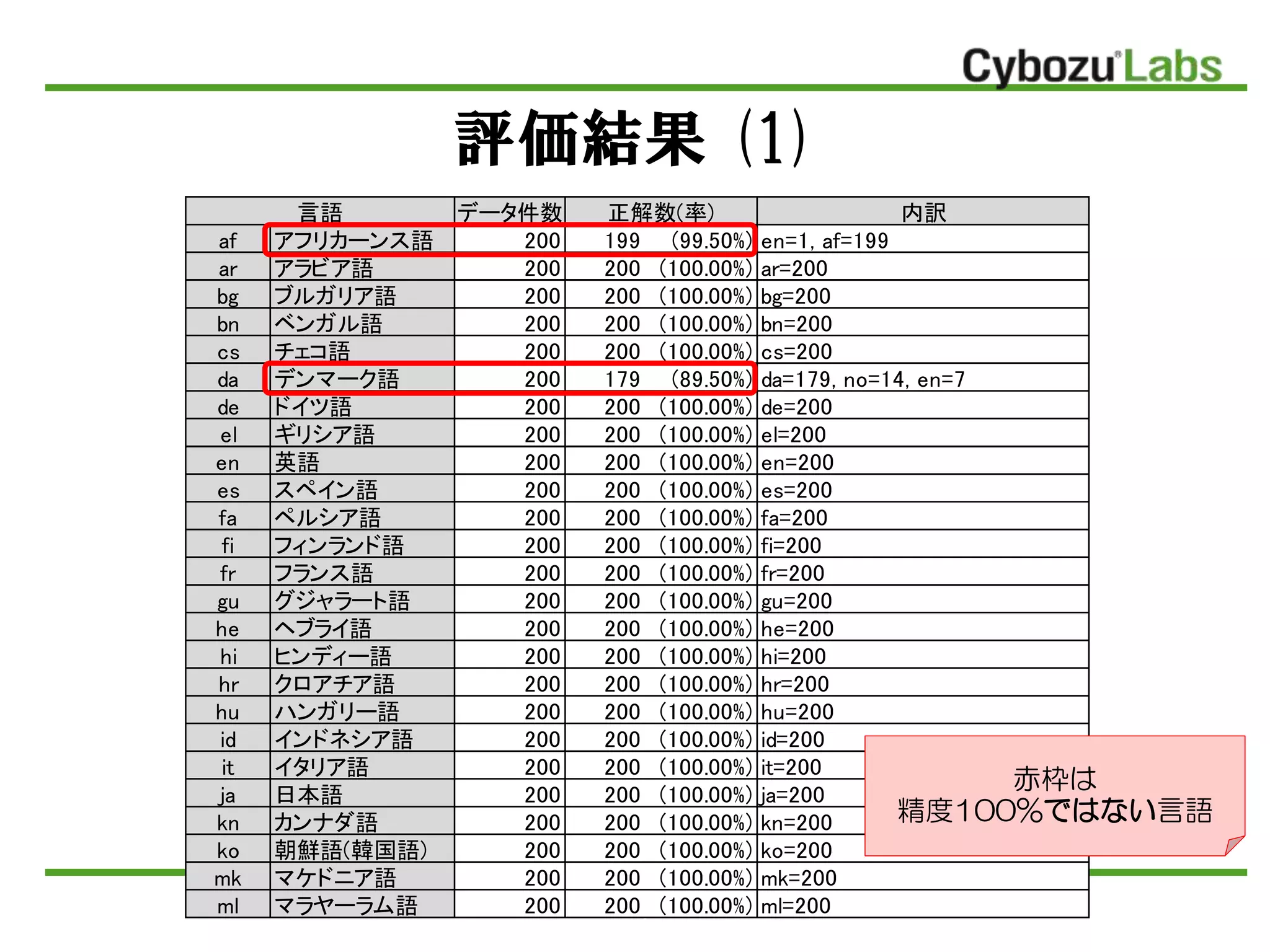
評価結果 (1) 言語 データ件数
正解数(率) 内訳 af アフリカーンス語 200 199 (99.50%) en=1, af=199 ar アラビア語 200 200 (100.00%) ar=200 bg ブルガリア語 200 200 (100.00%) bg=200 bn ベンガル語 200 200 (100.00%) bn=200 cs チェコ語 200 200 (100.00%) cs=200 da デンマーク語 200 179 (89.50%) da=179, no=14, en=7 de ドイツ語 200 200 (100.00%) de=200 el ギリシア語 200 200 (100.00%) el=200 en 英語 200 200 (100.00%) en=200 es スペイン語 200 200 (100.00%) es=200 fa ペルシア語 200 200 (100.00%) fa=200 fi フィンランド語 200 200 (100.00%) fi=200 fr フランス語 200 200 (100.00%) fr=200 gu グジャラート語 200 200 (100.00%) gu=200 he ヘブライ語 200 200 (100.00%) he=200 hi ヒンディー語 200 200 (100.00%) hi=200 hr クロアチア語 200 200 (100.00%) hr=200 hu ハンガリー語 200 200 (100.00%) hu=200 id インドネシア語 200 200 (100.00%) id=200 it イタリア語 200 200 (100.00%) it=200 ja 日本語 200 200 (100.00%) ja=200 kn カンナダ語 200 200 (100.00%) kn=200 ko 朝鮮語(韓国語) 200 200 (100.00%) ko=200 mk マケドニア語 200 200 (100.00%) mk=200 ml マラヤーラム語 200 200 (100.00%) ml=200 赤枠は 精度100%ではない言語
17.
評価結果 (2) 言語 データ件数
正解数(率) 内訳 mr マラーティー語 200 200 (100.00%) mr=200 ne ネパール語 200 200 (100.00%) ne=200 nl オランダ語 200 200 (100.00%) nl=200 no ノルウェー語 200 199 (99.50%) da=1, no=199 pa パンジャーブ語 200 200 (100.00%) pa=200 pl ポーランド語 200 200 (100.00%) pl=200 pt ポルトガル語 200 200 (100.00%) pt=200 ro ルーマニア語 200 200 (100.00%) ro=200 ru ロシア語 200 200 (100.00%) ru=200 sk スロバキア語 200 200 (100.00%) sk=200 so ソマリ語 200 200 (100.00%) so=200 sq アルバニア語 200 200 (100.00%) sq=200 sv スウェーデン語 200 200 (100.00%) sv=200 sw スワヒリ語 200 200 (100.00%) sw=200 ta タミル語 200 200 (100.00%) ta=200 te テルグ語 200 200 (100.00%) te=200 th タイ語 200 200 (100.00%) th=200 tl タガログ語 200 200 (100.00%) tl=200 tr トルコ語 200 200 (100.00%) tr=200 uk ウクライナ語 200 200 (100.00%) uk=200 ur ウルドゥー語 200 200 (100.00%) ur=200 vi ベトナム語 200 200 (100.00%) vi=200 zh-cn 中国語(簡体字) 200 200 (100.00%) zh-cn=200 zh-tw 中国語(繁体字) 200 200 (100.00%) zh-tw=200 合計 9800 9777 (99.77%)
18.
アルゴリズムと精度向上の工夫
19.
ナイーブベイズによる言語判定 「言語」をカテゴリとした文書分類を行う 文書が「英語」に分類されるか、「日本語」に分類さ れるか判定
カテゴリ毎の特徴量の出現確率から カテゴリの事後確率を更新 𝑝 𝐶k 𝑋 (m+1) ∝ 𝑝 𝐶k 𝑋 m ⋅ 𝑝 𝑋𝑖 𝐶 𝑘 where 𝐶k:カテゴリ, 𝑋:文書, 𝑋𝑖:文書の特徴量 正規化し、最大確率が0.99999を超えたら終了 判定処理を打ち切ることができる データサイズによらず高速
20.
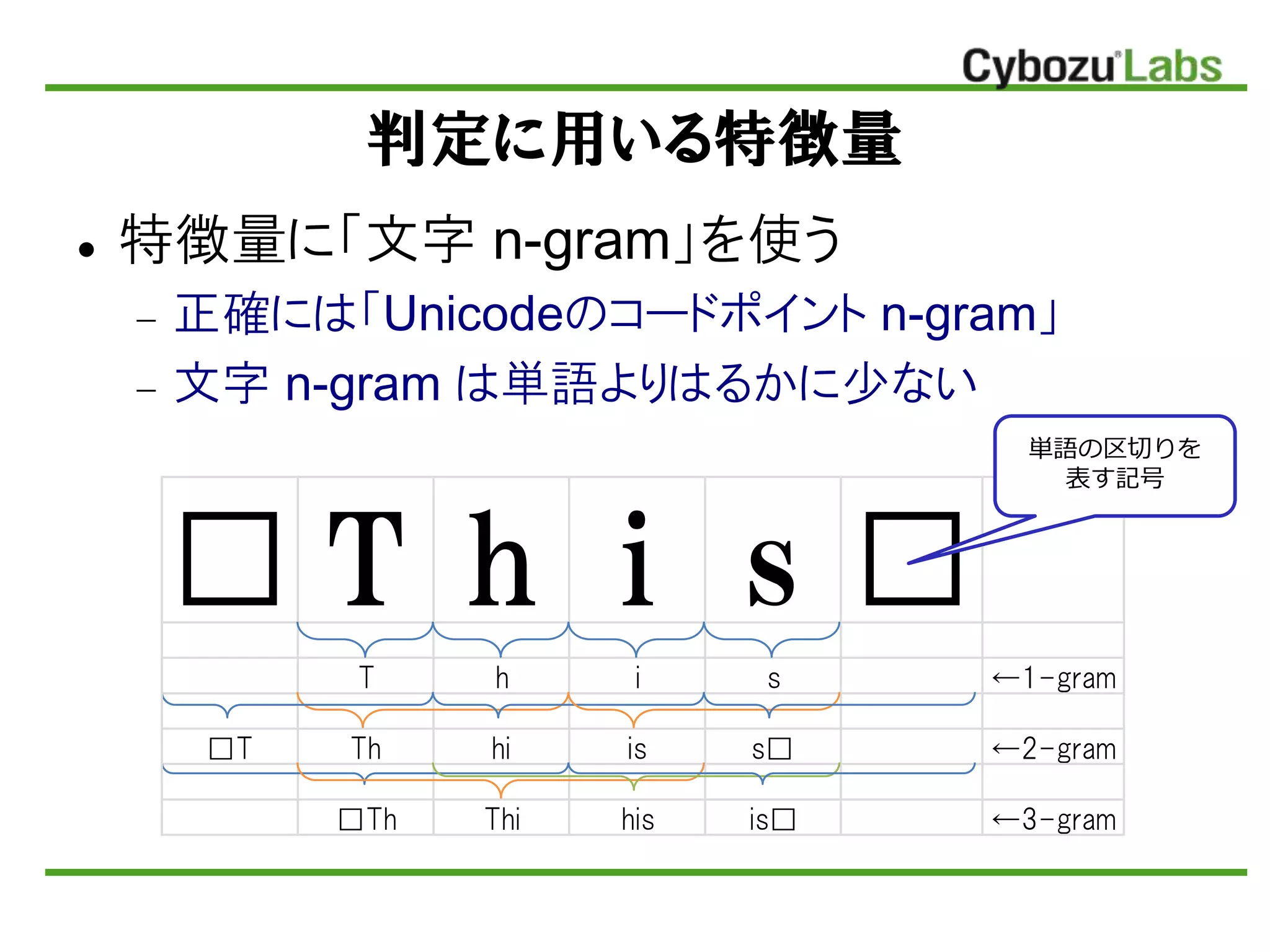
判定に用いる特徴量 特徴量に「文字 n-gram」を使う
正確には「Unicodeのコードポイント n-gram」 文字 n-gram は単語よりはるかに少ない □ T h i s □ T h i s ←1-gram □T Th hi is s□ ←2-gram □Th Thi his is□ ←3-gram 単語の区切りを 表す記号
21.
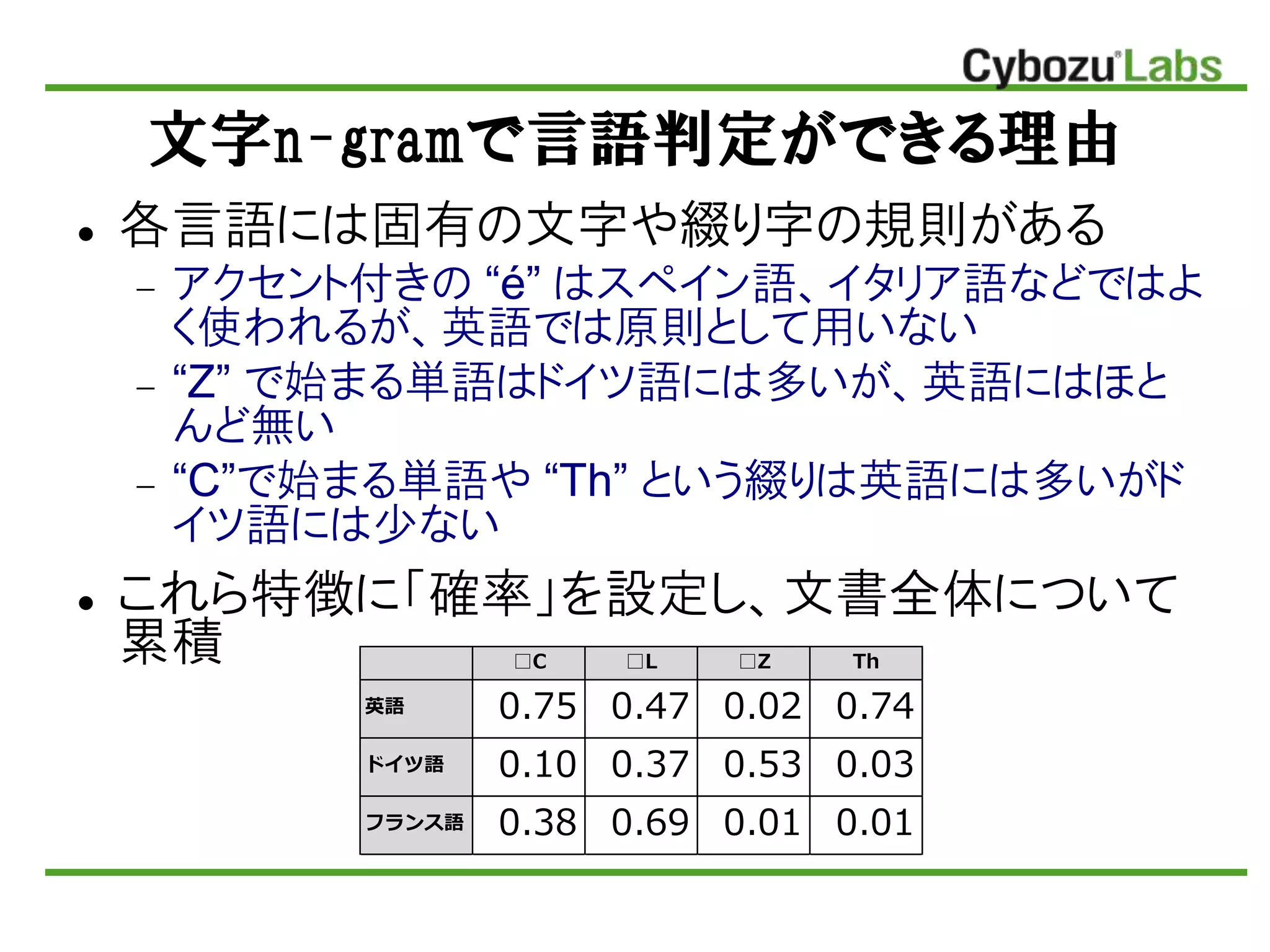
文字n-gramで言語判定ができる理由 各言語には固有の文字や綴り字の規則がある アクセント付きの
“é” はスペイン語、イタリア語などではよ く使われるが、英語では原則として用いない “Z” で始まる単語はドイツ語には多いが、英語にはほと んど無い “C”で始まる単語や “Th” という綴りは英語には多いがド イツ語には少ない これら特徴に「確率」を設定し、文書全体について 累積 □C □L □Z Th 英語 0.75 0.47 0.02 0.74 ドイツ語 0.10 0.37 0.53 0.03 フランス語 0.38 0.69 0.01 0.01
22.
これで判定できるようになったが…… アルゴリズムそのままでの精度は90%前後 「実用レベル」ではない
特定の言語で非常に精度が悪い 日本語、中国語(繁体字)、ロシア語、ペルシャ語、…… 精度が上がらない最大の原因: コーパス(学習/判定テキスト)の偏りとノイズ これらを様々な方法で除去 フィルタ 文字の正規化 対策のごく一部……
23.
(1) 文字種の偏り アルファベット
30字前後 アラビア文字、デーヴァナーガリー(インド)も同様 漢字: 20000字~ 文字種が他言語の1000倍! Wikipedia で使われない文字(ゼロ頻度問題) 「谢谢」が判定できない 日本人の人名漢字も同様 大文字小文字を分けても 高々倍 Wikipedia に 「谢」は出てこない!
24.
「常用漢字」を考慮した正規化 「頻度が似ている漢字」でグルーピングし、 代表文字に正規化(グループ全体を1文字につぶす) (1)
K-means によるクラスタ分類 (2) 「常用漢字」による分類 簡体字: 现代汉语常用字表(3500字) 繁体字: Big5第1水準(5401字、「常用国字標準字体表」 4808字を含む) 日本語: 常用漢字(2136字)+JIS 第1水準(2965字)=2998字 常用漢字だけでは、氏名や地名の漢字の多くが入っていない K-means のクラスタ&各「常用漢字」で集合積 → 130のクラスタに分類
25.
(2) テキストのノイズ 言語に依存しない文字
→ 単純に除去 数字、記号、URL やメールアドレス ラテン文字ノイズ in 非ラテン文字 非ラテン文字の中にも頻繁に出現 ある意味世界共通文字 → ラテン文字が2割以下なら除去 ラテン文字ノイズ in ラテン文字 略字、人名は言語の特徴を表さない 特に人名は他言語の特徴をもつことも多い(Mc~=ゲール語) → 全て大文字の単語は除去 → 特徴サンプリングして、人名などの局所的な特徴の影 響を低減
26.
アラビア文字の正規化 ペルシャ語の判定が全滅(全てアラビア語に!!) 同じアラビア文字だが語族が違う→判別は容易なはず
原因:高頻度で使われる yeh のコードが異なる 学習コーパス(Wikipedia)では ی (¥u06cc, Farsi yeh) テストコーパス(ニュース)では ¥(يu064a, Arabic yeh) 推測:アラビア語の文字コード CP-1256 には ¥u06cc にマッピ ングされる文字がないため、¥u064aで代用する手法が定着? 対策: ¥u06cc を ¥u064a に正規化 ペルシア語ではye( )یの独立形・右接形には識別点を付けないが,付けているものをよく見かけ る。これはアラビア語キーボードでペルシア語を入力したときによく起こる問題である。また,OS やブラウザーなどの環境によってはこの文字が正しく出ないため,ウェブでは確信犯的にアラビ ア語のyā’( )يを使っていることが多い。 「アラビア語系文字の基礎知識」より
27.
まとめ
28.
まとめ 49言語を 99.8%
で判定可能な言語判定ライ ブラリを開発 オープンソースとして公開 http://code.google.com/p/language-detection/ サイボウズ次期製品への採用予定 90%までは簡単。でも実用レベルは99.*%~ 理想:美しい斬新な理論で一発解答 現実:どこまでも泥臭い工夫の固まり
29.
Open Issues 短文の判定が苦手(twitterのつぶやきとか)
アラビア語の母音記号をどう扱う? 複数言語で記述された文書の言語判別 テキストにソースコードが入っていると……
30.
参考文献 千野栄一編「世界のことば100語辞典 ヨーロッパ編」
町田和彦編「図説 世界の文字とことば」 世界の文字研究会「世界の文字の図典」 町田和彦「ニューエクスプレス ヒンディー語」 中村公則「らくらくペルシャ語 文法から会話」 道広勇司「アラビア系文字の基礎知識」 http://moji.gr.jp/script/arabic/article01.html 北研二,辻井潤一「確率的言語モデル」 [Dunning 1994] Statistical Identification of Language [Sibun & Reynar 1996] Language identification: Examining the issues [Martins+ 2005] Language Identification in Web Pages
31.
twitter で応募できます! [宣伝]エンジニアの未来サミット for
student http://cybozu.co.jp/company/job/recruitment/recruit/seminar.html
32.
ありがとうございました
Download

























![参考文献
千野栄一編「世界のことば100語辞典 ヨーロッパ編」
町田和彦編「図説 世界の文字とことば」
世界の文字研究会「世界の文字の図典」
町田和彦「ニューエクスプレス ヒンディー語」
中村公則「らくらくペルシャ語 文法から会話」
道広勇司「アラビア系文字の基礎知識」
http://moji.gr.jp/script/arabic/article01.html
北研二,辻井潤一「確率的言語モデル」
[Dunning 1994] Statistical Identification of Language
[Sibun & Reynar 1996] Language identification: Examining the
issues
[Martins+ 2005] Language Identification in Web Pages](https://image.slidesharecdn.com/webdbforum2010-101112064743-phpapp02/75/40-30-2048.jpg)
![twitter で応募できます!
[宣伝]エンジニアの未来サミット for student
http://cybozu.co.jp/company/job/recruitment/recruit/seminar.html](https://image.slidesharecdn.com/webdbforum2010-101112064743-phpapp02/75/40-31-2048.jpg)









![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Kim+ ICML2012] Dirichlet Process with Mixed Random Measures : A Nonparametri...](https://cdn.slidesharecdn.com/ss_thumbnails/dp-mrmkimicml2012-120727233419-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














