Downloaded 217 times








![20Copyright©2017 NTT Corp. All Rights Reserved.
• Raft is a methodology for SMR based systems
• In Search of an Understandable Consensus Algorithm
[Ongaro and Ousterhout, USENIX ATC 2014]
• The performance and functionalities of Raft are same to
Paxos (Multi Paxos) [Lamport TOCS ʻ98]
• And Raft is more understandable: details required by
implementations are well specified
Why do we need SMR techniques?](https://image.slidesharecdn.com/coreosfest-170601225958/75/Understanding-performance-aspects-of-etcd-and-Raft-20-2048.jpg)

![22Copyright©2017 NTT Corp. All Rights Reserved.
• Now we have the methodology for replicating
state machines
• In a highly available and linearizable manner
• Can we replicate any state machines easily?
• According to Leslie Lamport, (it seems to be) yes
• From Part-time Parliament [Lamport TOCS ʻ98]
Why do we need SMR techniques?](https://image.slidesharecdn.com/coreosfest-170601225958/75/Understanding-performance-aspects-of-etcd-and-Raft-22-2048.jpg)





![36Copyright©2017 NTT Corp. All Rights Reserved.
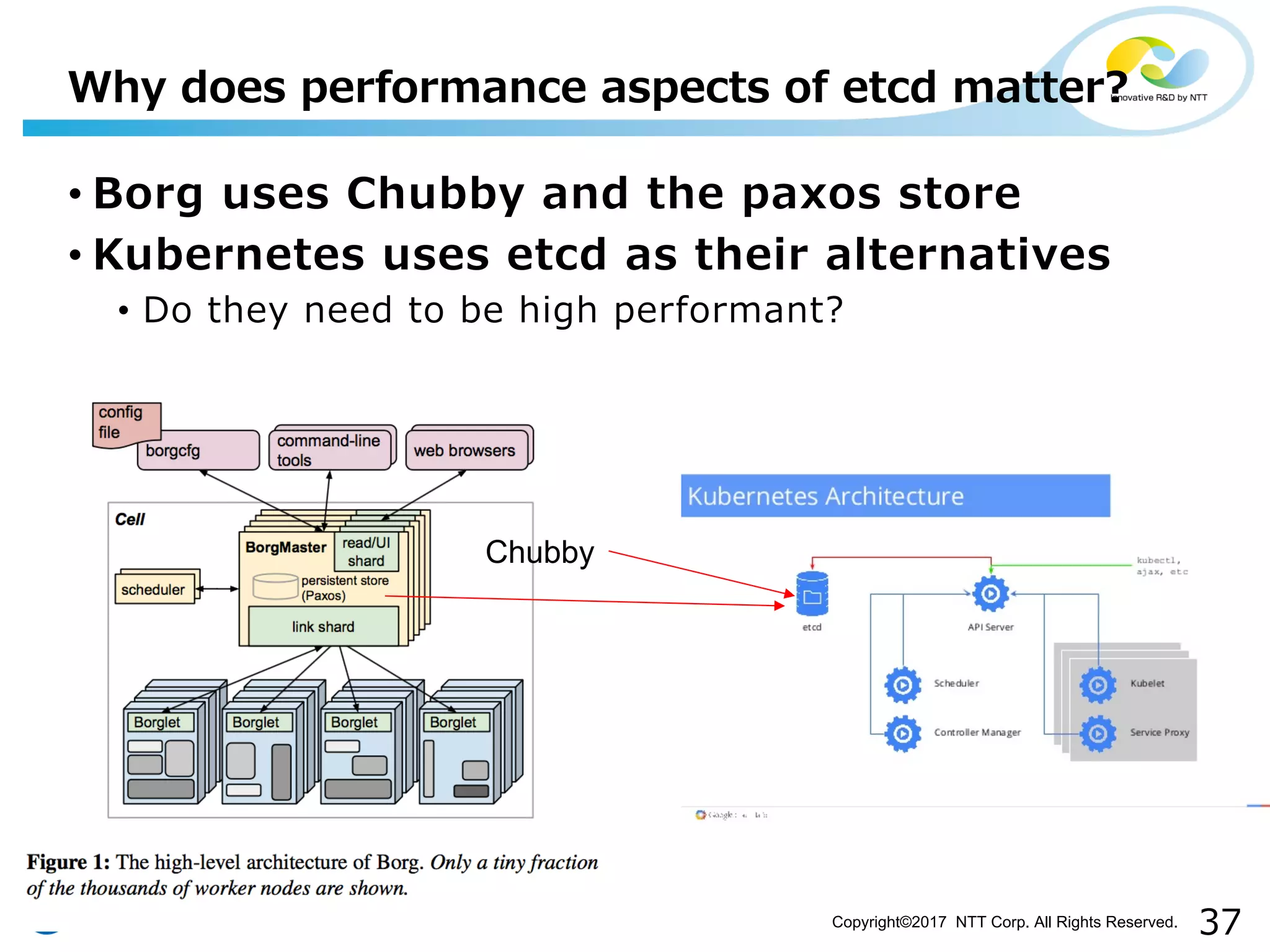
• What is etcd?
• No need to explain here…
• A highly available and consistent KVS
• General purpose configuration store
• As an open source clone of Googleʼs Chubby [Burrows,
OSDI ʼ06]
• The most important and interesting user would be
kubernetes
Why does performance aspects of etcd matter?](https://image.slidesharecdn.com/coreosfest-170601225958/75/Understanding-performance-aspects-of-etcd-and-Raft-36-2048.jpg)
![38Copyright©2017 NTT Corp. All Rights Reserved.
• The paxos store needs to be high performant
• Borg is a distributed operating system, and the paxos
store is a kind of its runqueue
Why does performance aspects of etcd matter?
[Verma et, al. EuroSys ’15]
A case of non distributed OS
A case of Borg
Operating Systems: Three Easy Pieces
http://pages.cs.wisc.edu/~remzi/OSTEP/cpu-intro.pdf](https://image.slidesharecdn.com/coreosfest-170601225958/75/Understanding-performance-aspects-of-etcd-and-Raft-38-2048.jpg)













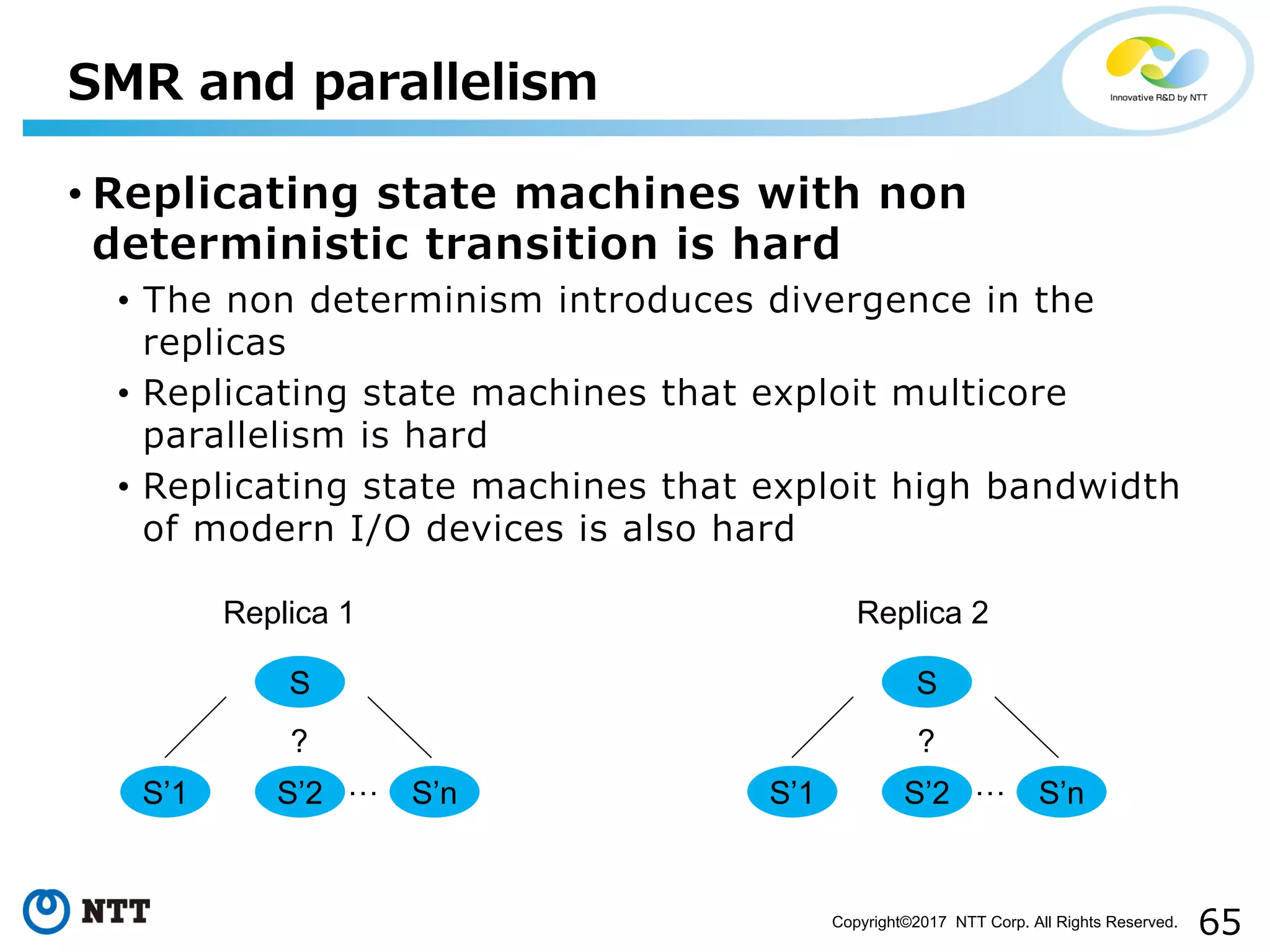
![66Copyright©2017 NTT Corp. All Rights Reserved.
• What kind of techniques are available?
• EVE [Kapritsos et al. OSDI ʻ12]
• Consider the divergence of state are considered as a result of
byzantine fault, and fix in the agreement process
• Rex [Guo et al. EuroSys ʻ14]
• Speculation based replication for multicore scalable systems
• https://github.com/Microsoft/rDSN
• Crane [Cui et al. SOSP ʻ15]
• Deterministic scheduling (originally established in the
context of debugging purpose) based replication techniques
• Posix applications can be replicated without modification
• https://github.com/columbia/crane
• All of them are research prototypes
• Replicating multicore scalable state machines is a cutting
edge research topic!
• Very hopeful, but using them today would require
significant engineering cost
SMR and parallelism](https://image.slidesharecdn.com/coreosfest-170601225958/75/Understanding-performance-aspects-of-etcd-and-Raft-66-2048.jpg)







![79Copyright©2017 NTT Corp. All Rights Reserved.
• [Ongaro and Ousterhout, USENIX ATC 2014]
• https://www.usenix.org/conference/atc14/technical-
sessions/presentation/ongaro
• https://raft.github.io/ has other important materials
• [Kapritsos et al. OSDI ʻ12]
• https://www.usenix.org/node/170851
• [Guo et al. EuroSys ʻ14]
• https://www.microsoft.com/en-us/research/publication/rex-
replication-at-the-speed-of-multi-core/
• Crane [Cui et al. SOSP ʻ15]
• http://i.cs.hku.hk/~heming/papers/crane-sosp15.pdf
• [Lamport TOCS ʻ98]
• http://lamport.azurewebsites.net/pubs/pubs.html#lamport-
paxos
• [Verma et, al. EuroSys ʼ15]
• https://research.google.com/pubs/pub43438.html
References](https://image.slidesharecdn.com/coreosfest-170601225958/75/Understanding-performance-aspects-of-etcd-and-Raft-79-2048.jpg)


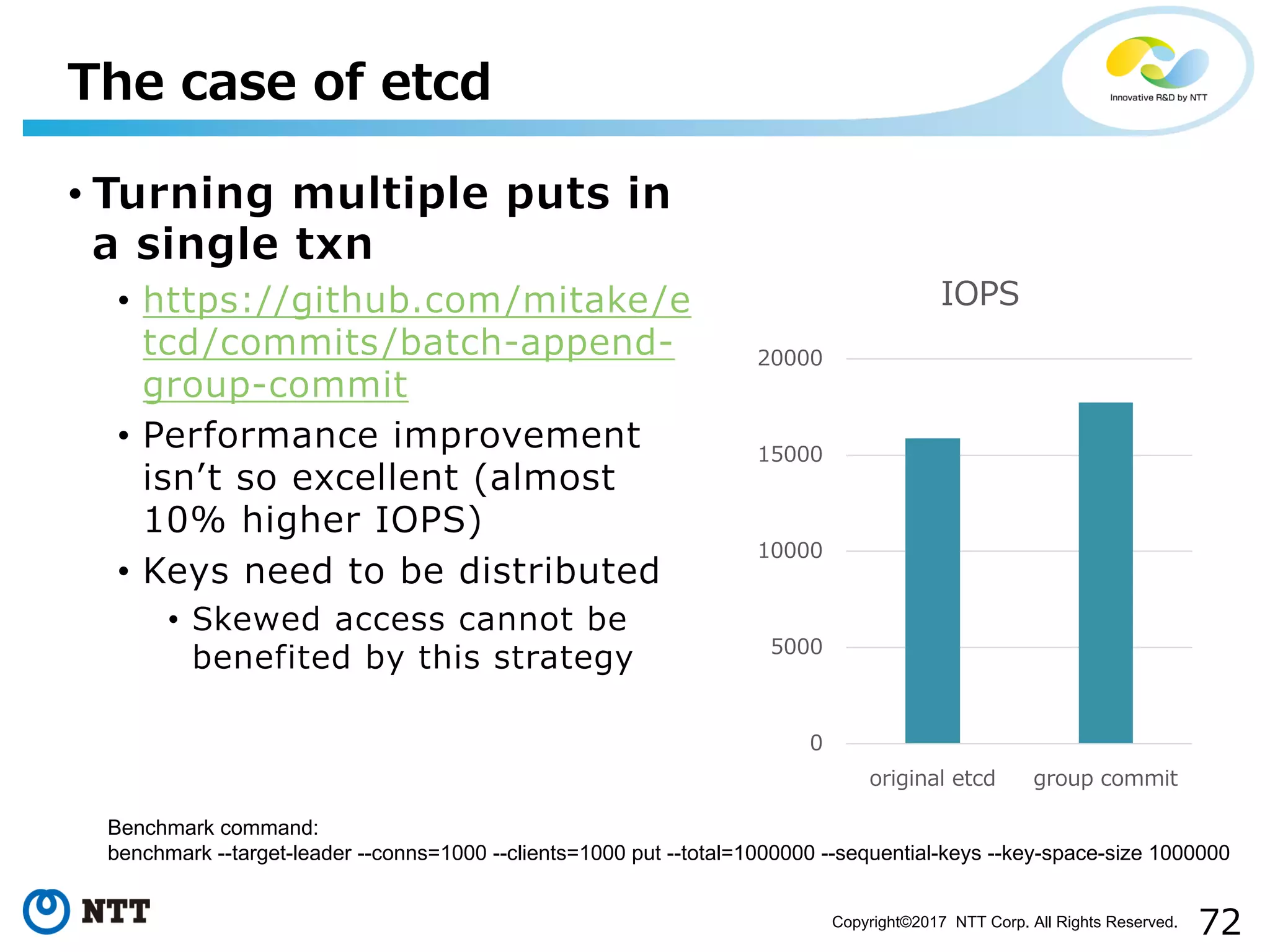
The document discusses performance aspects of etcd and Raft consensus algorithm. It begins with an introduction to state machine replication techniques and why they are important for building highly available and consistent distributed systems. It then provides some tips for managing etcd clusters and developing applications using the Raft consensus package, including how compaction can impact performance and reducing execution time of state machine operations. It also discusses an idea for optimization based on group commit.
Overview of the speaker Hitoshi Mitake, software engineer at NTT Labs, focusing on etcd and Raft.
Discussion on Raft background, state machine replication, etcd management tips, and conclusion.
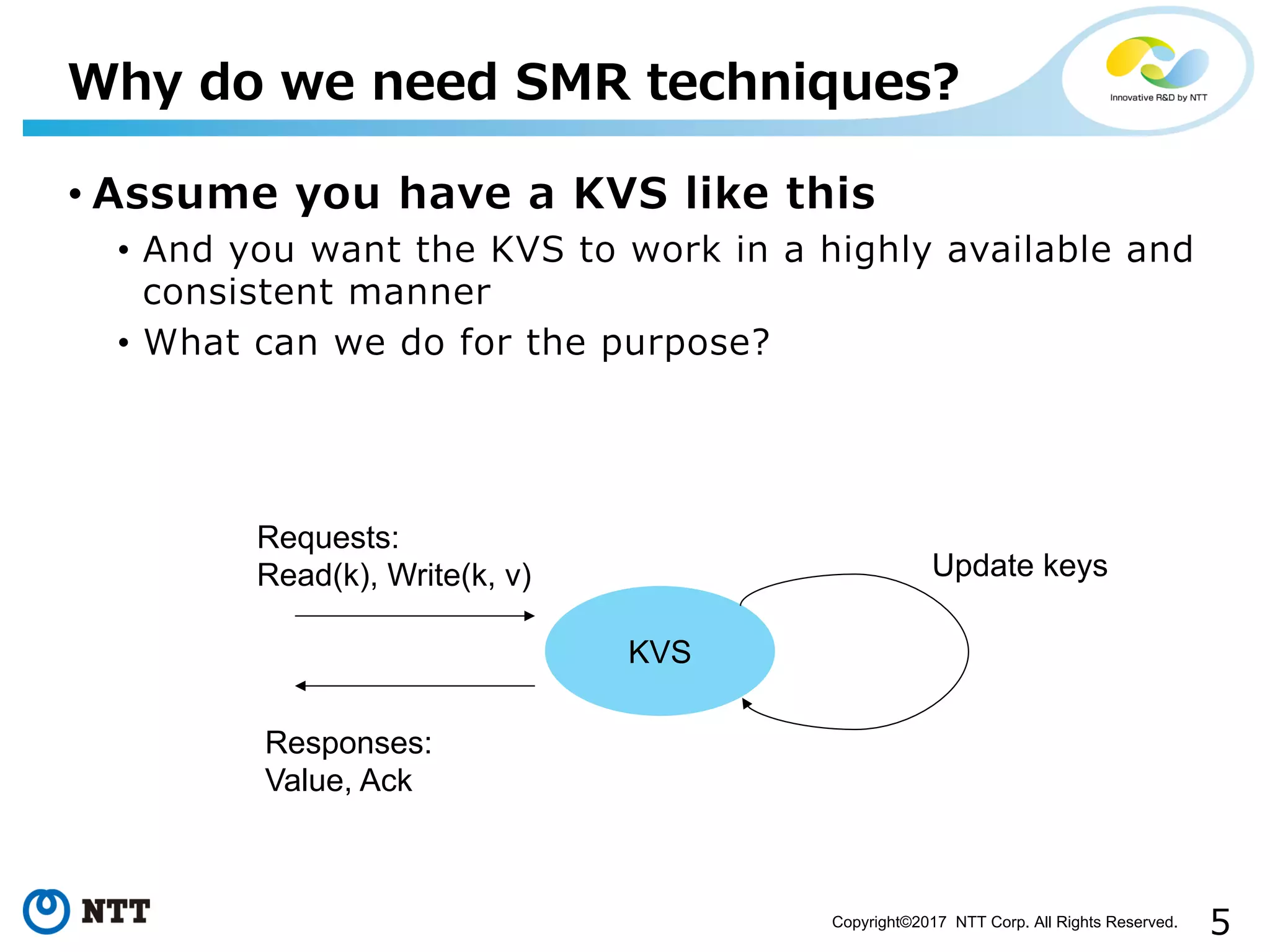
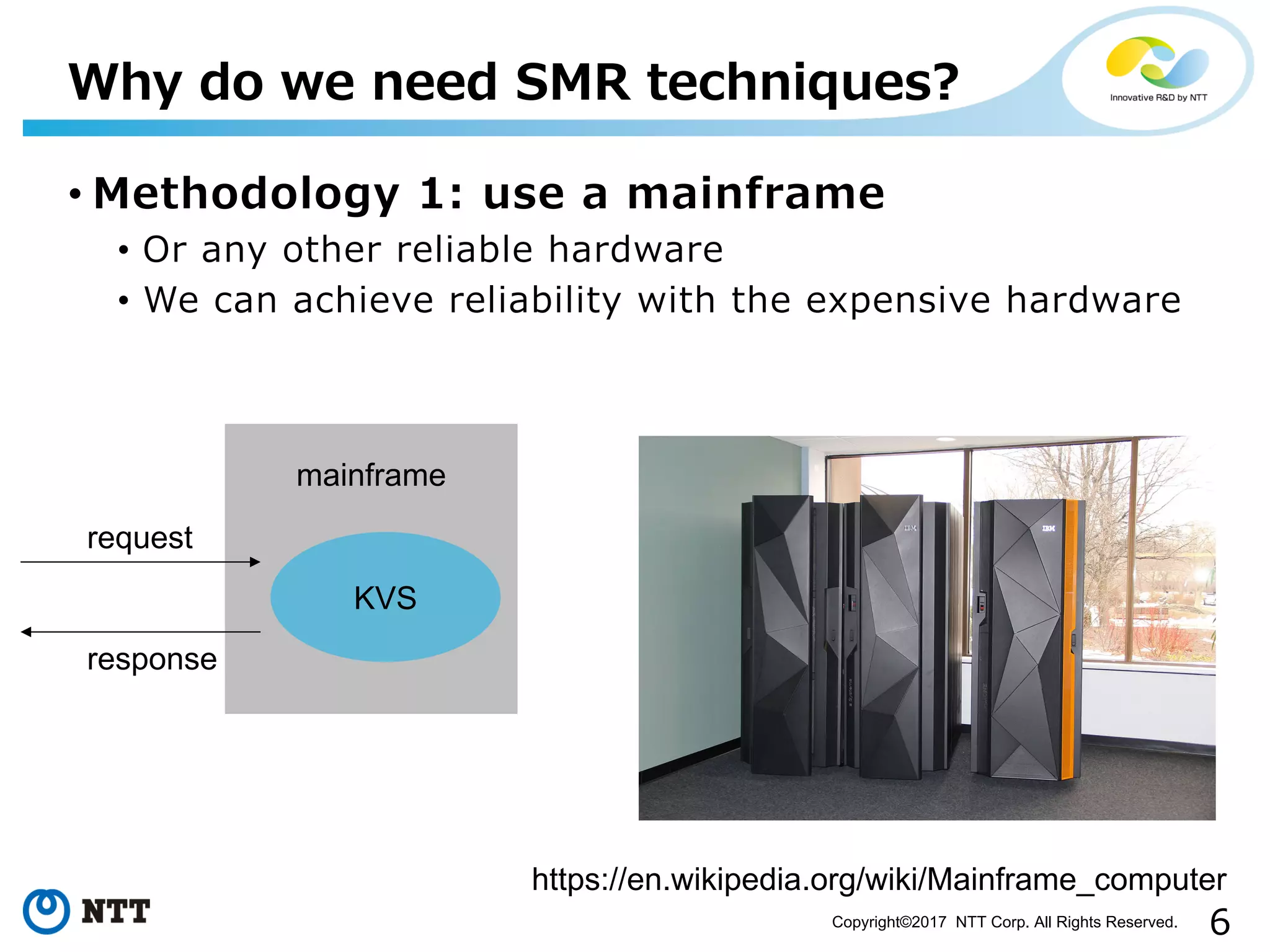
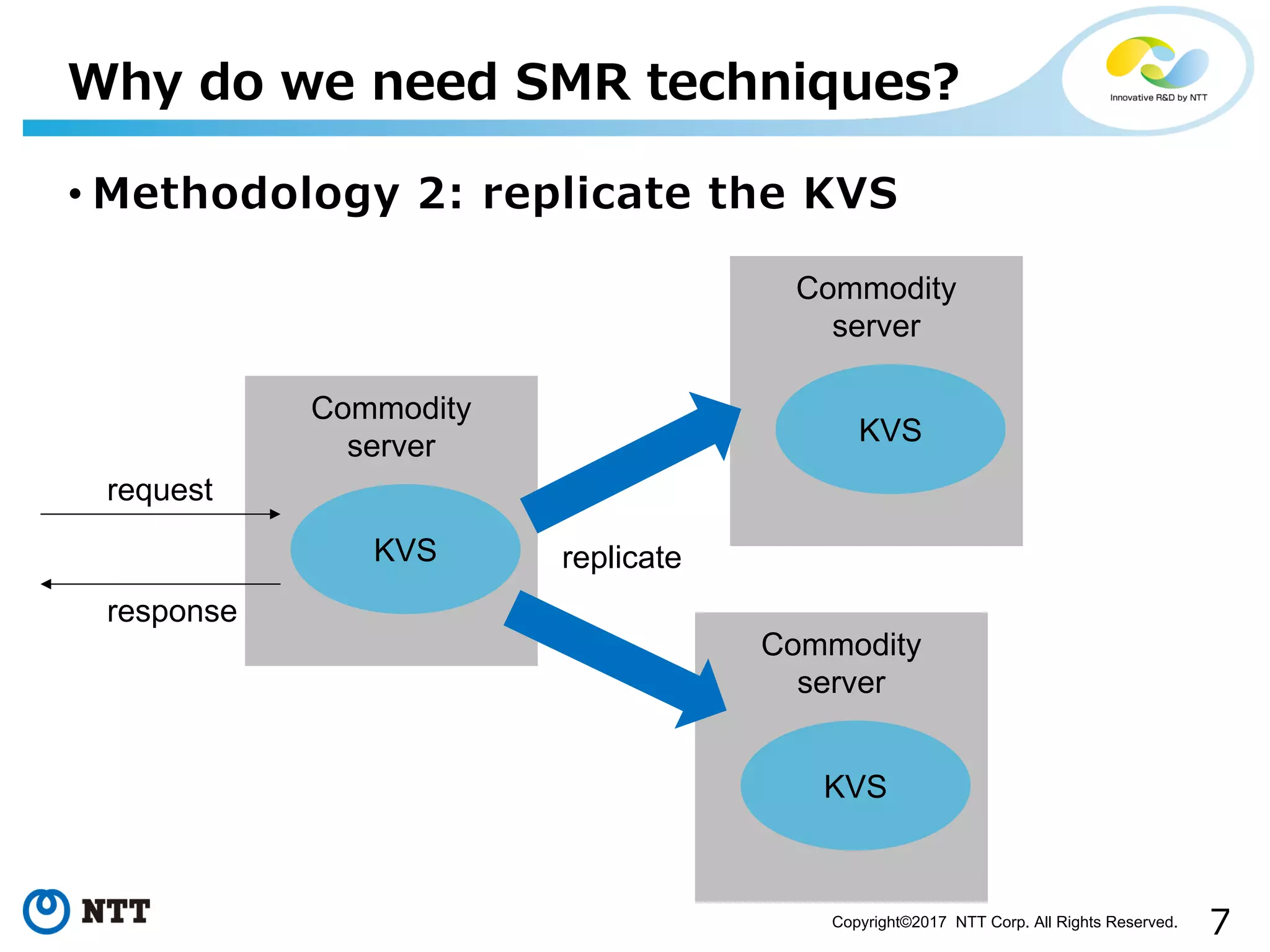
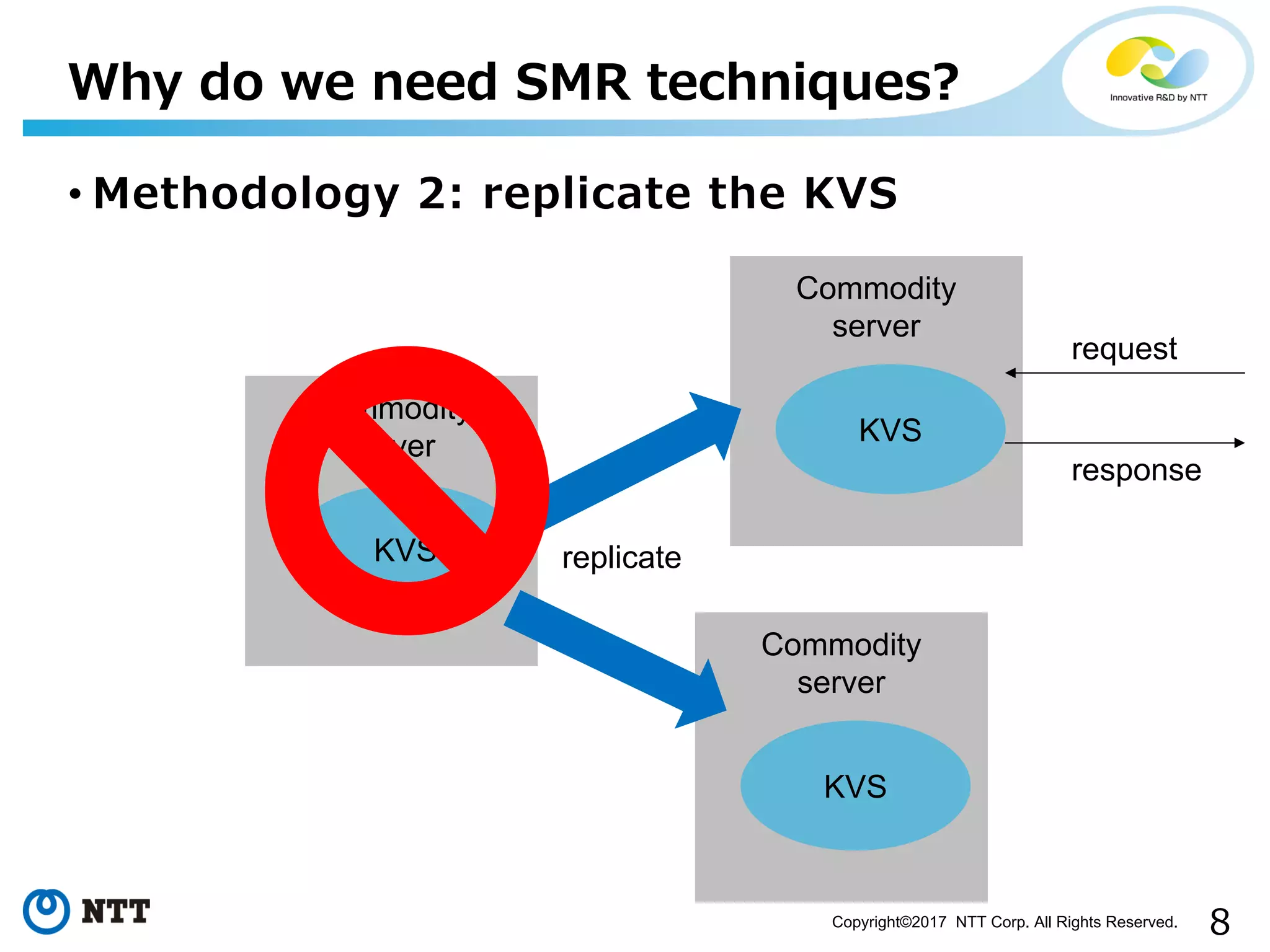
Introduction to SMR importance with KVS discussed through methodologies for reliability and availability.
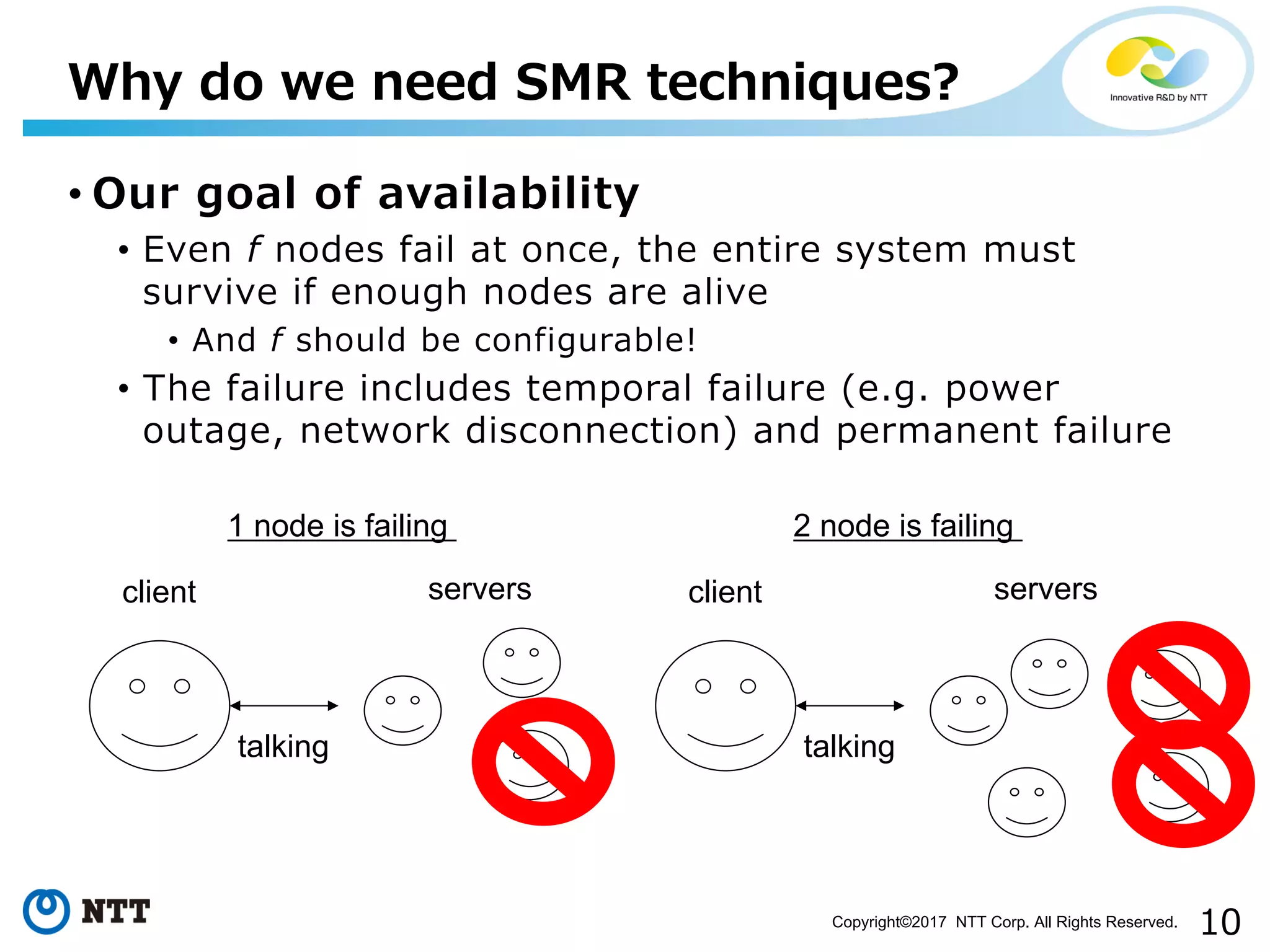
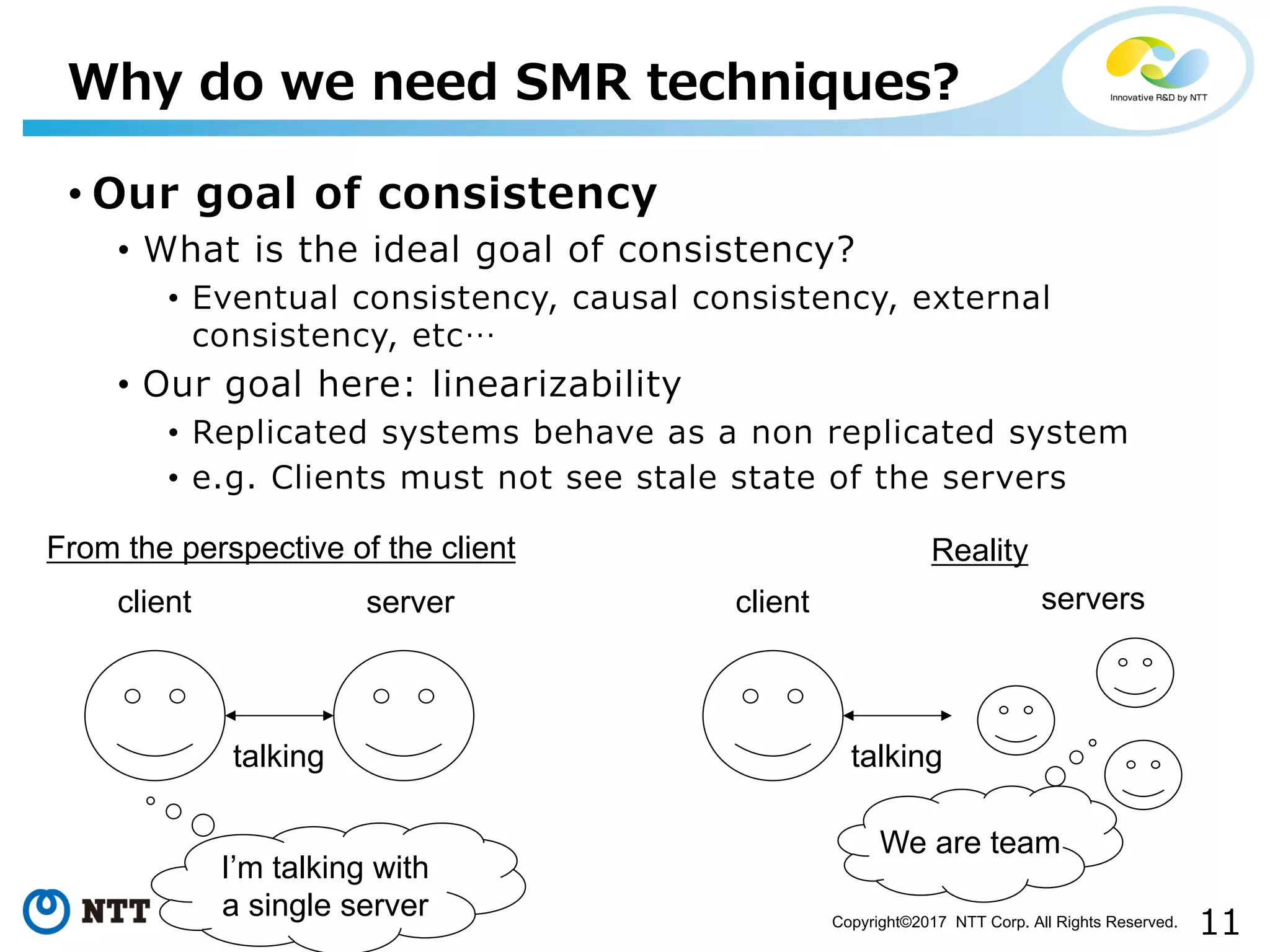
Explains goals for availability and consistency in replicated systems and their complexity.
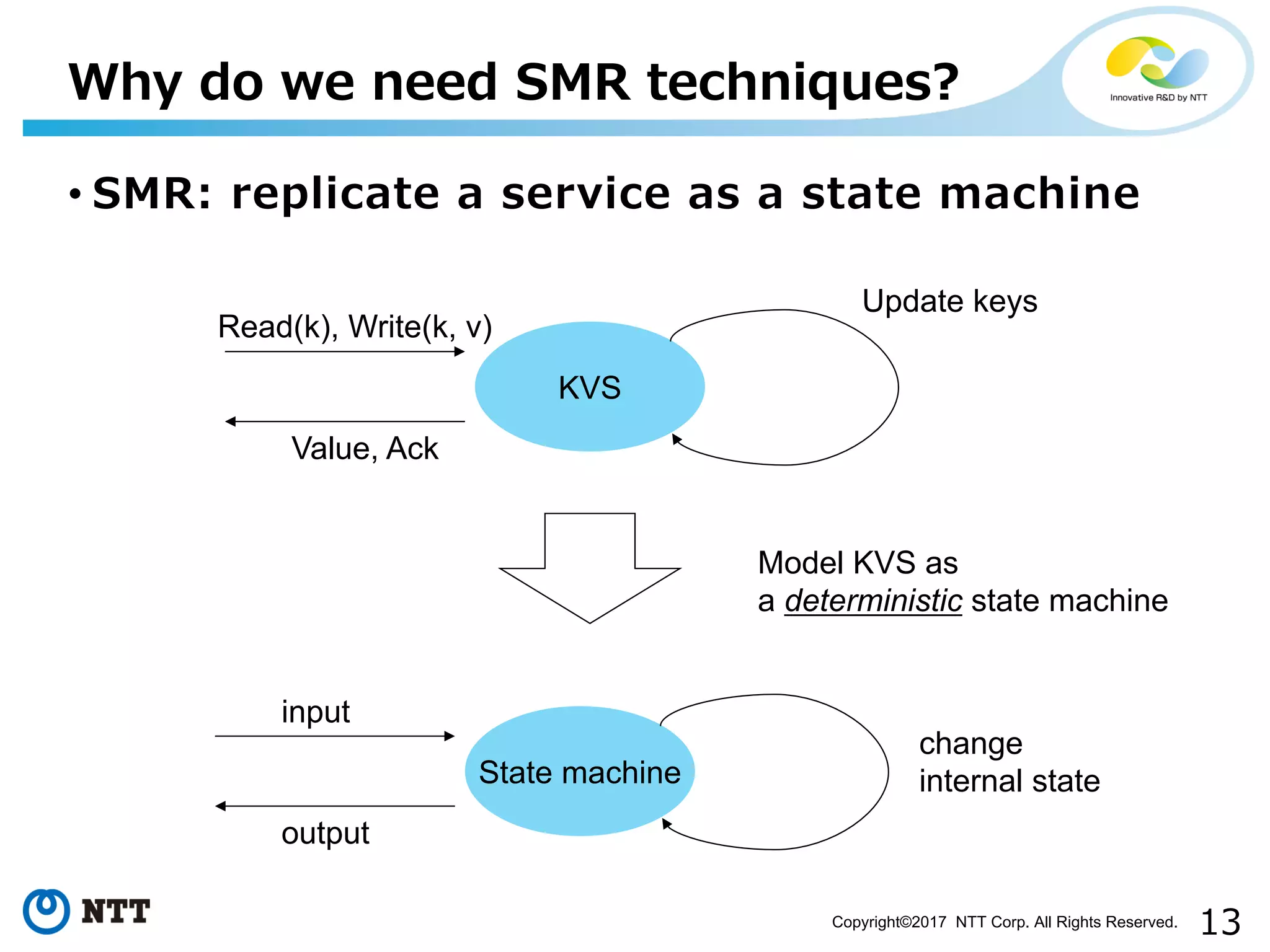
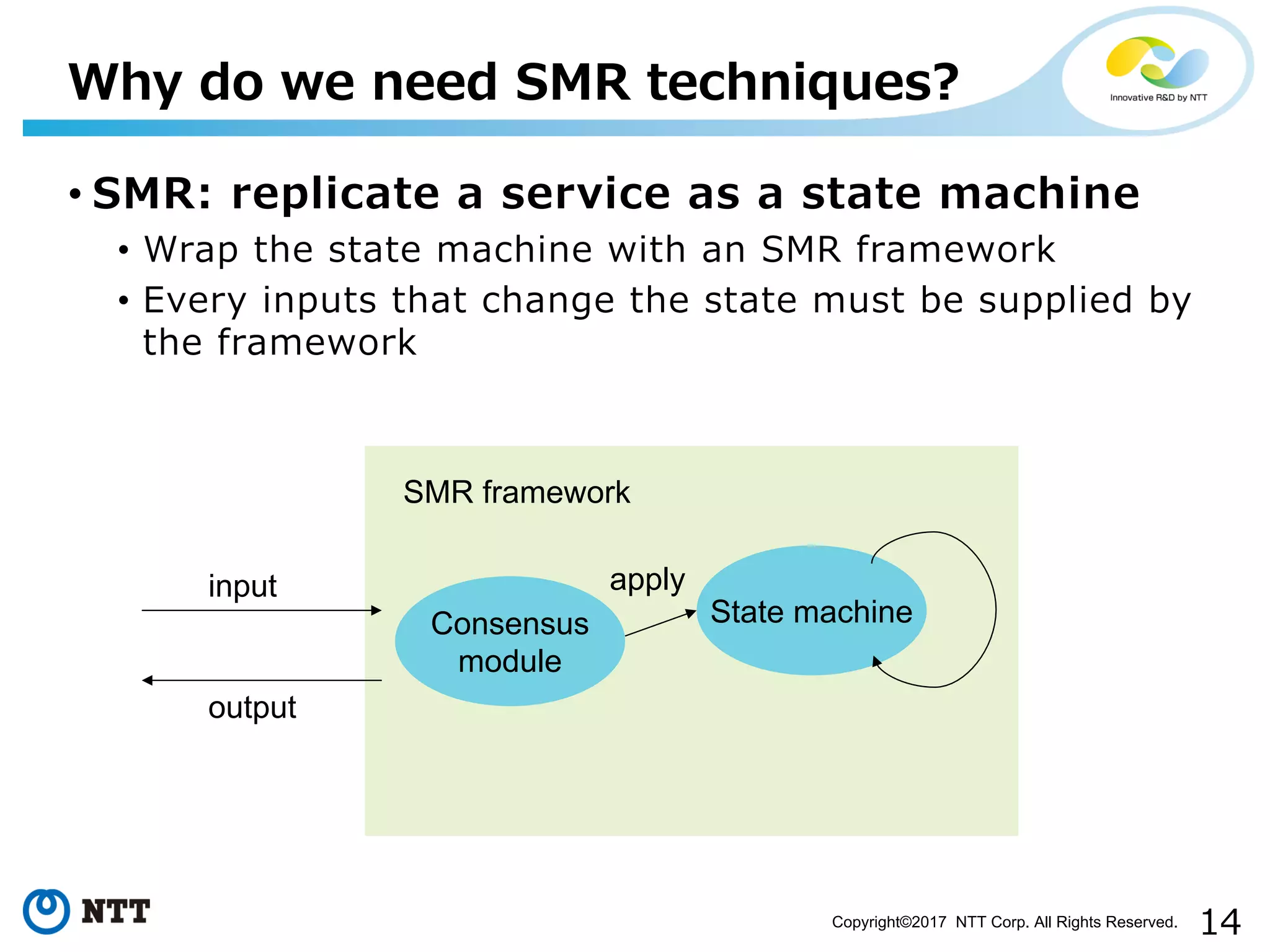
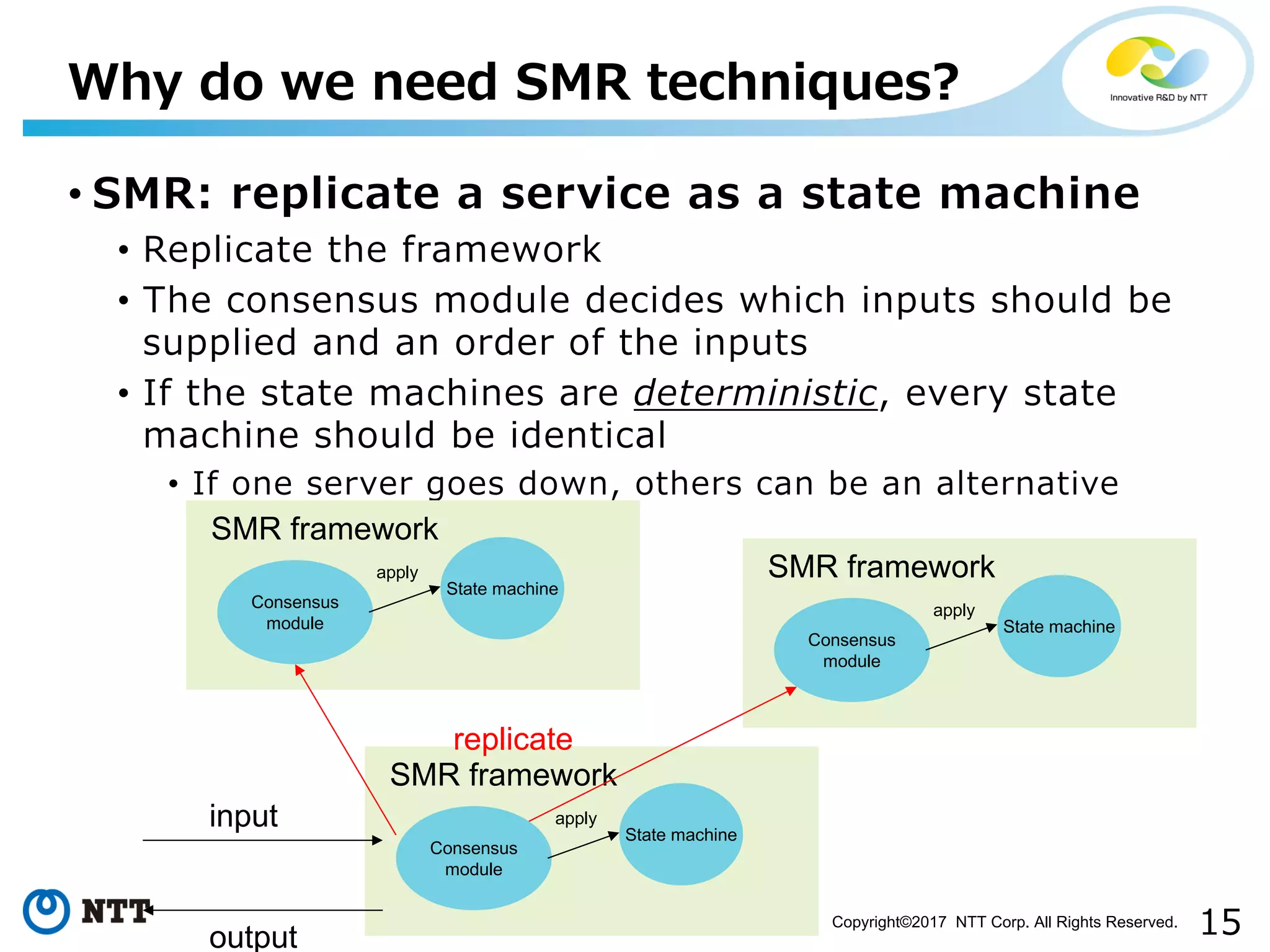
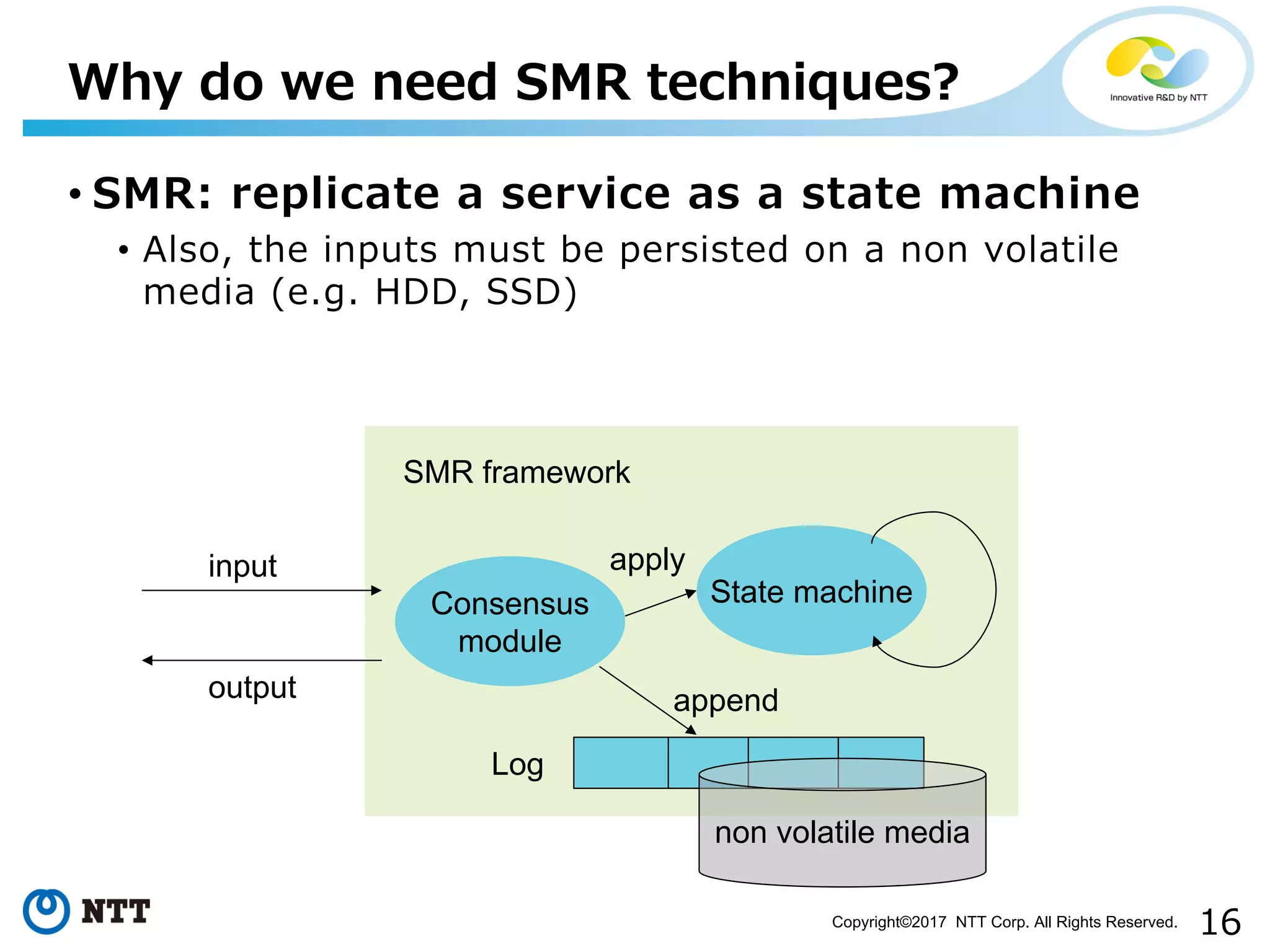
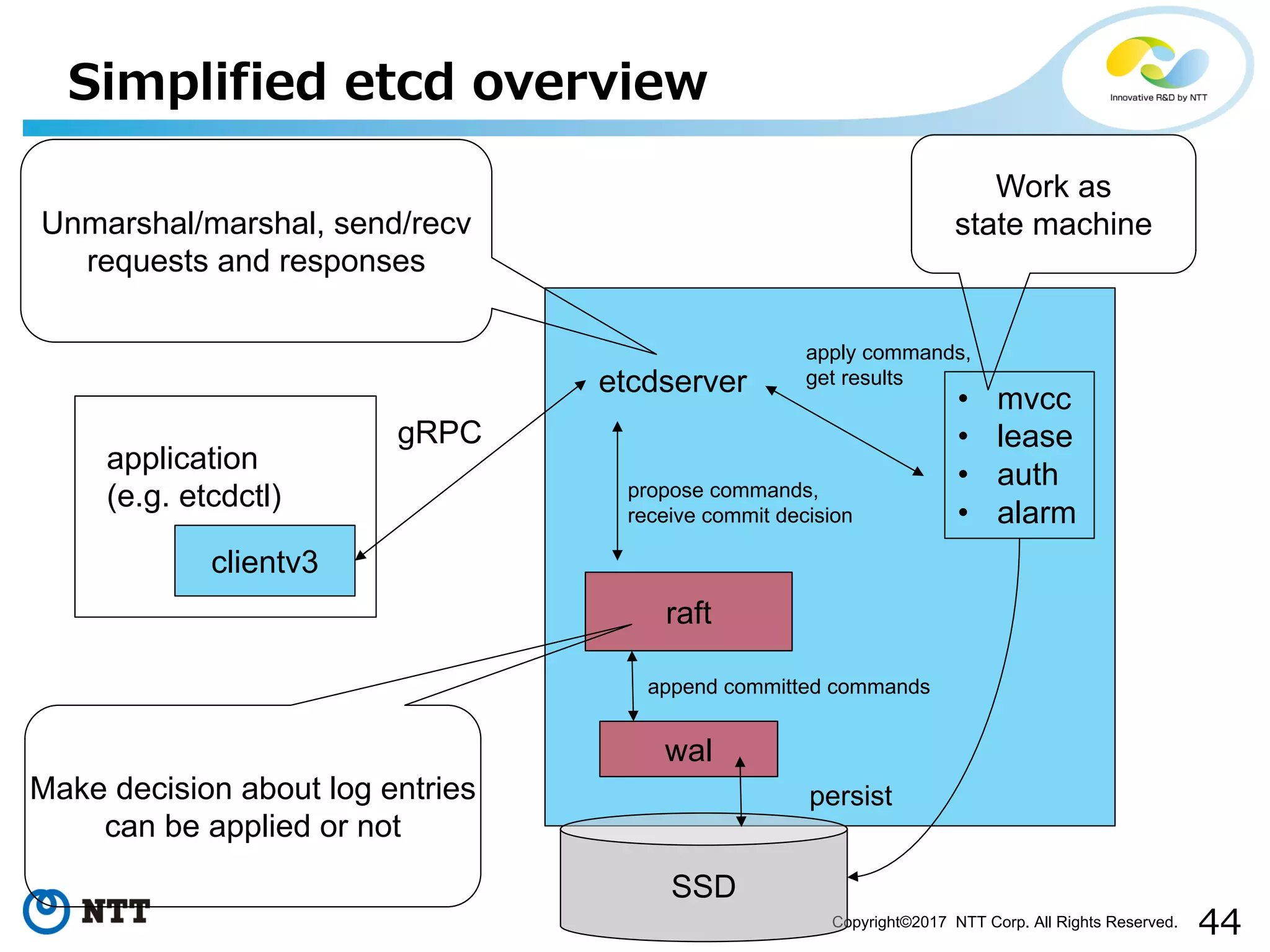
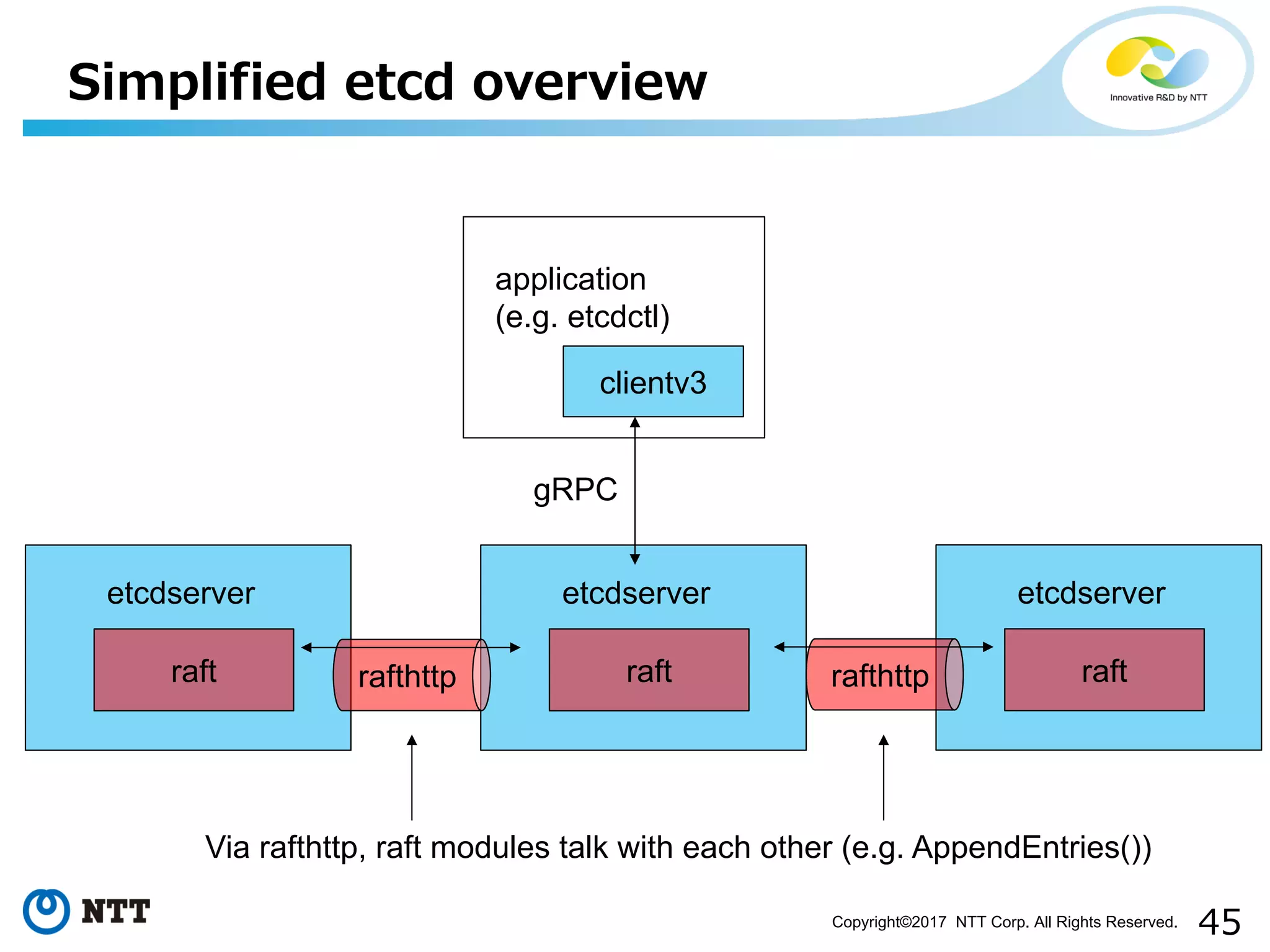
Outlines how SMR replicates services through state machines and the need for persistence.
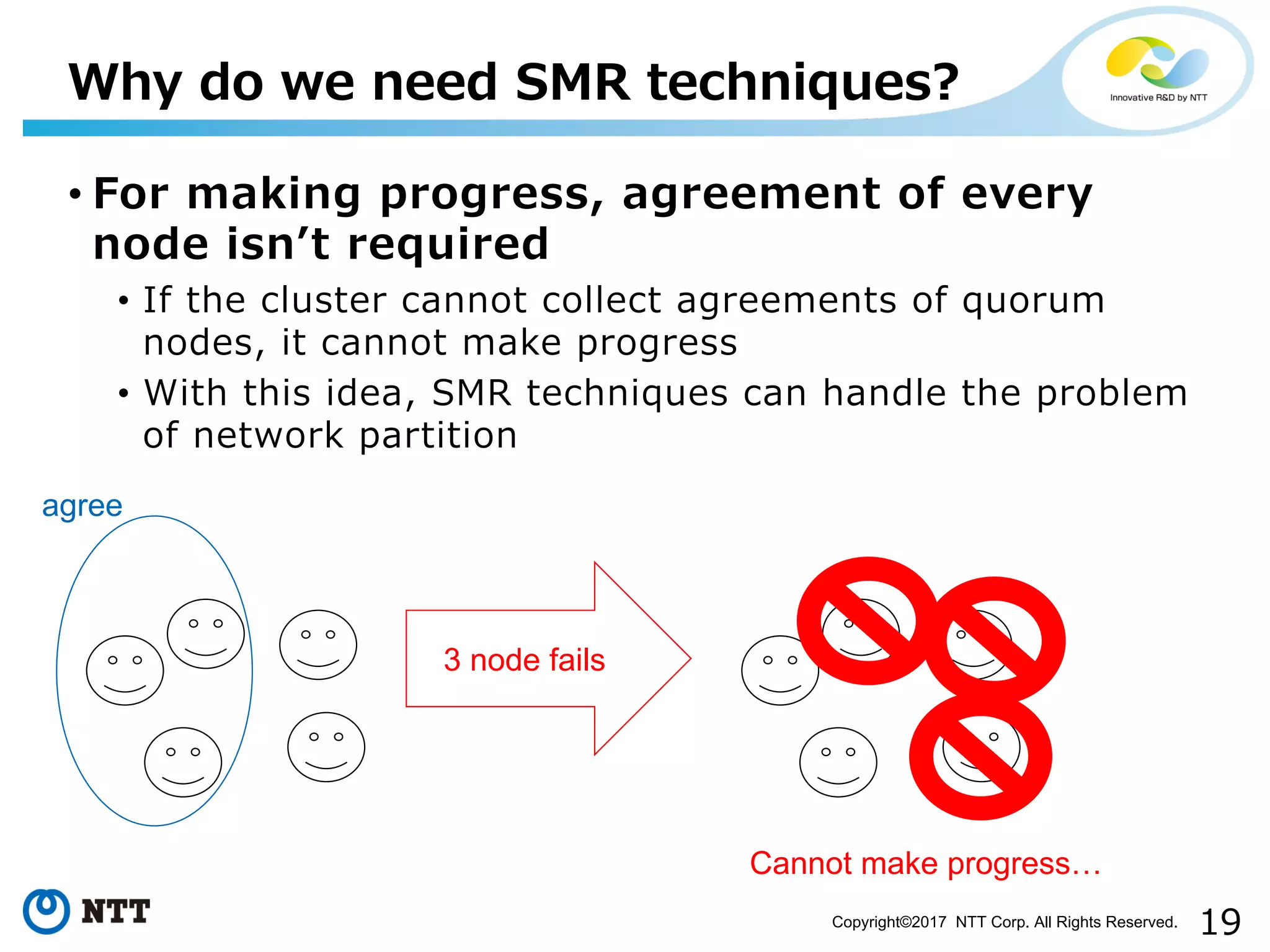
Importance of quorum for consensus in SMR systems and handling network partition problems.
Introduction of Raft as a consensus mechanism for SMR, emphasizing its understandability.
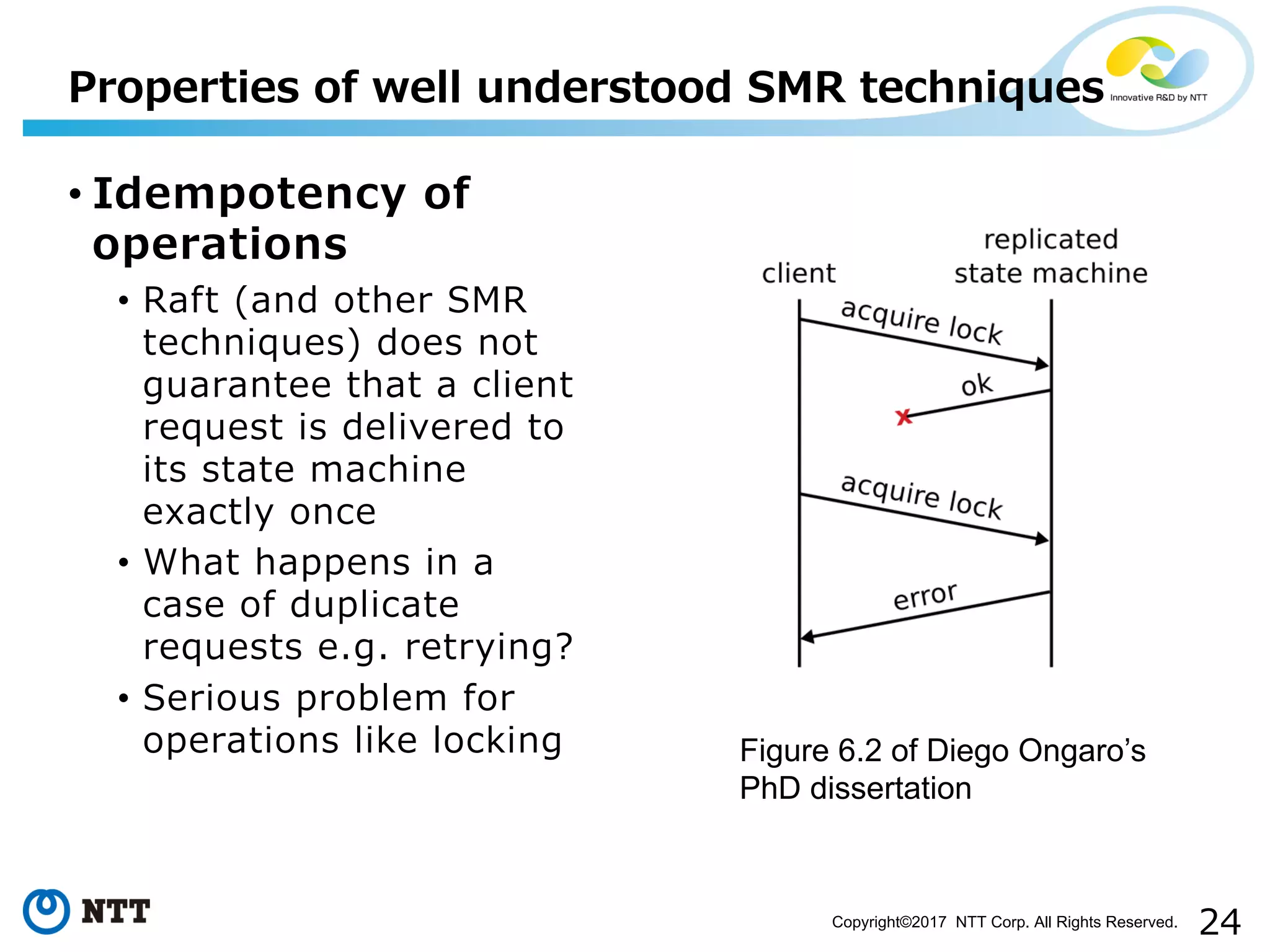
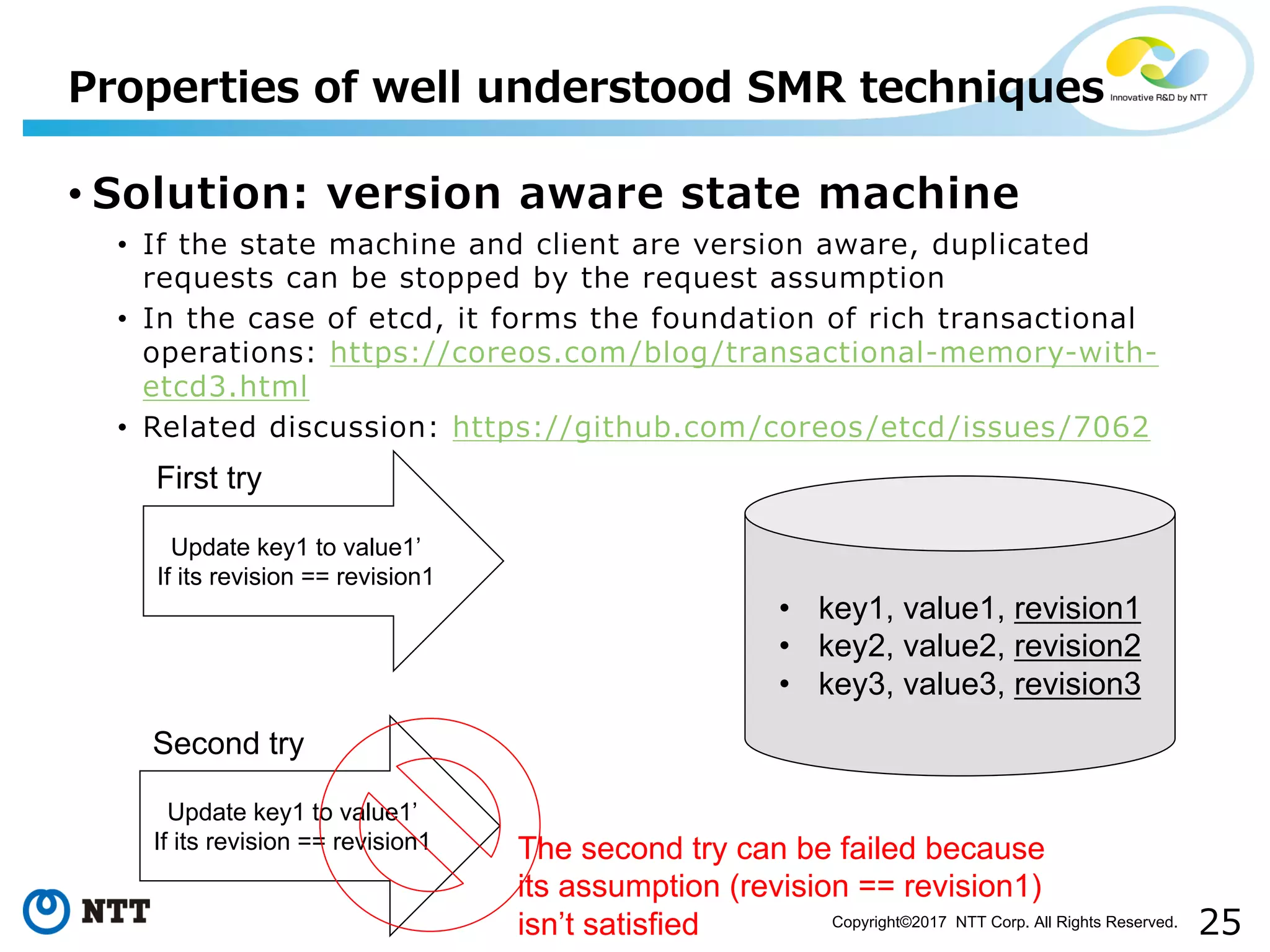
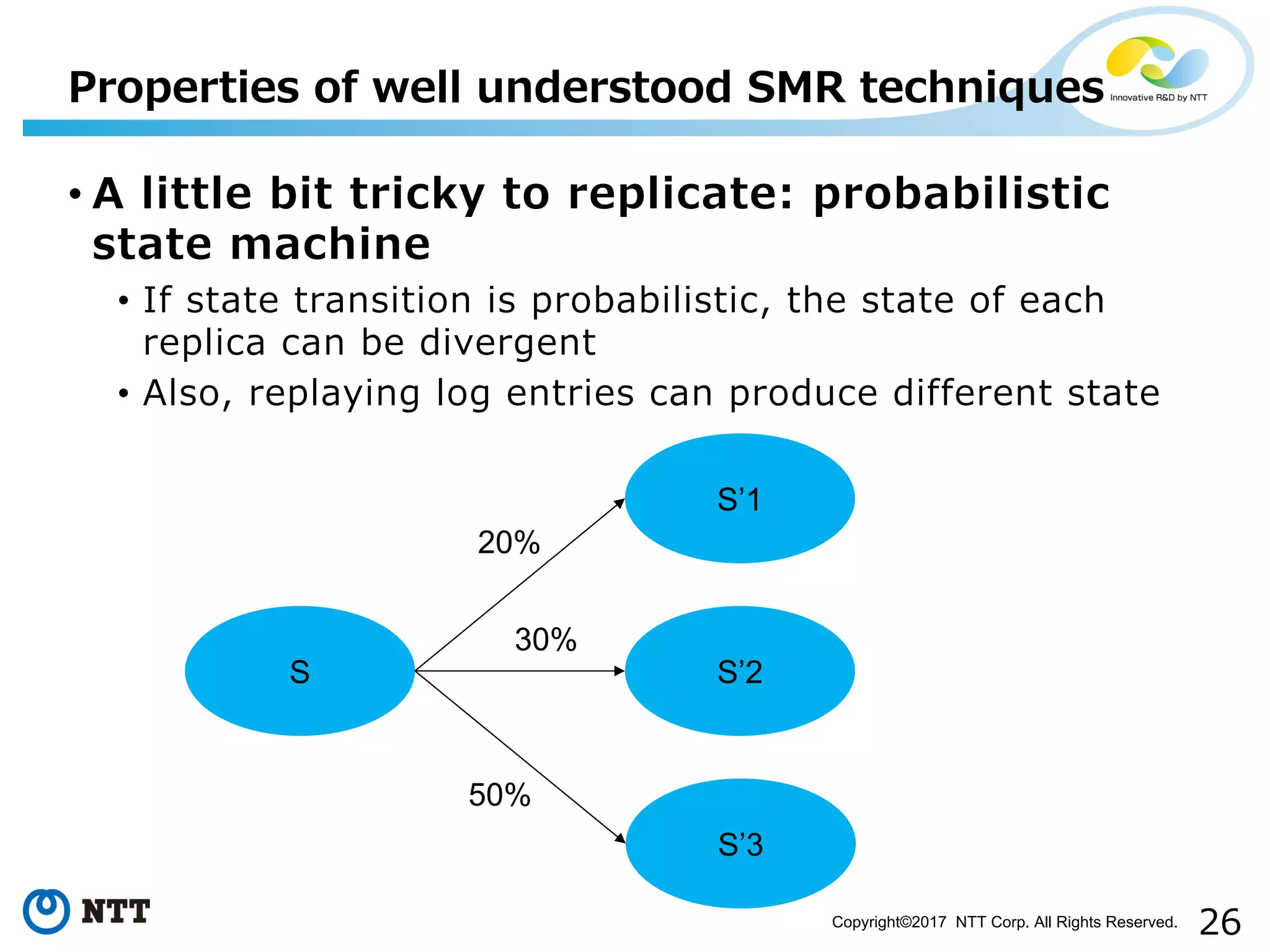
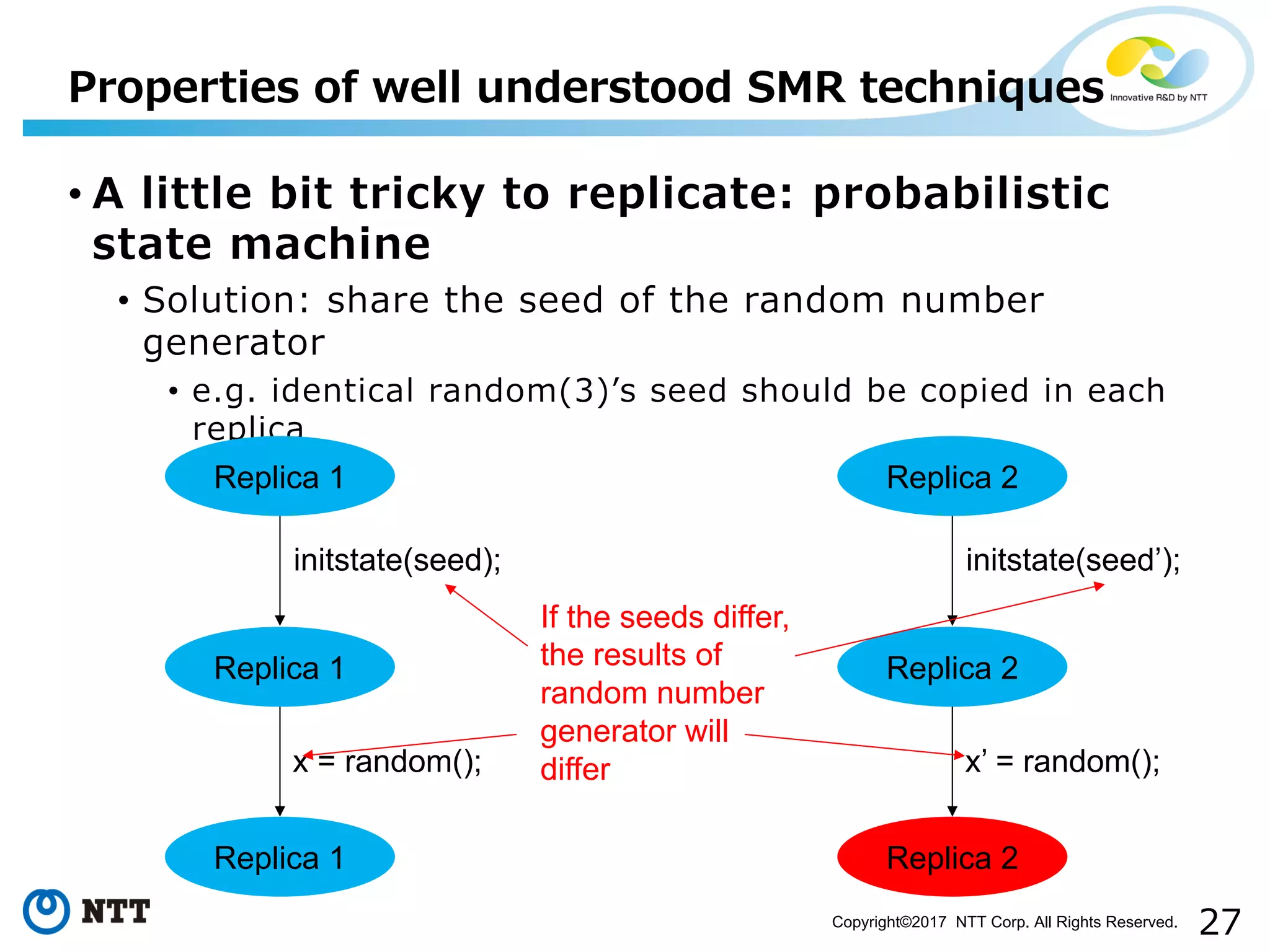
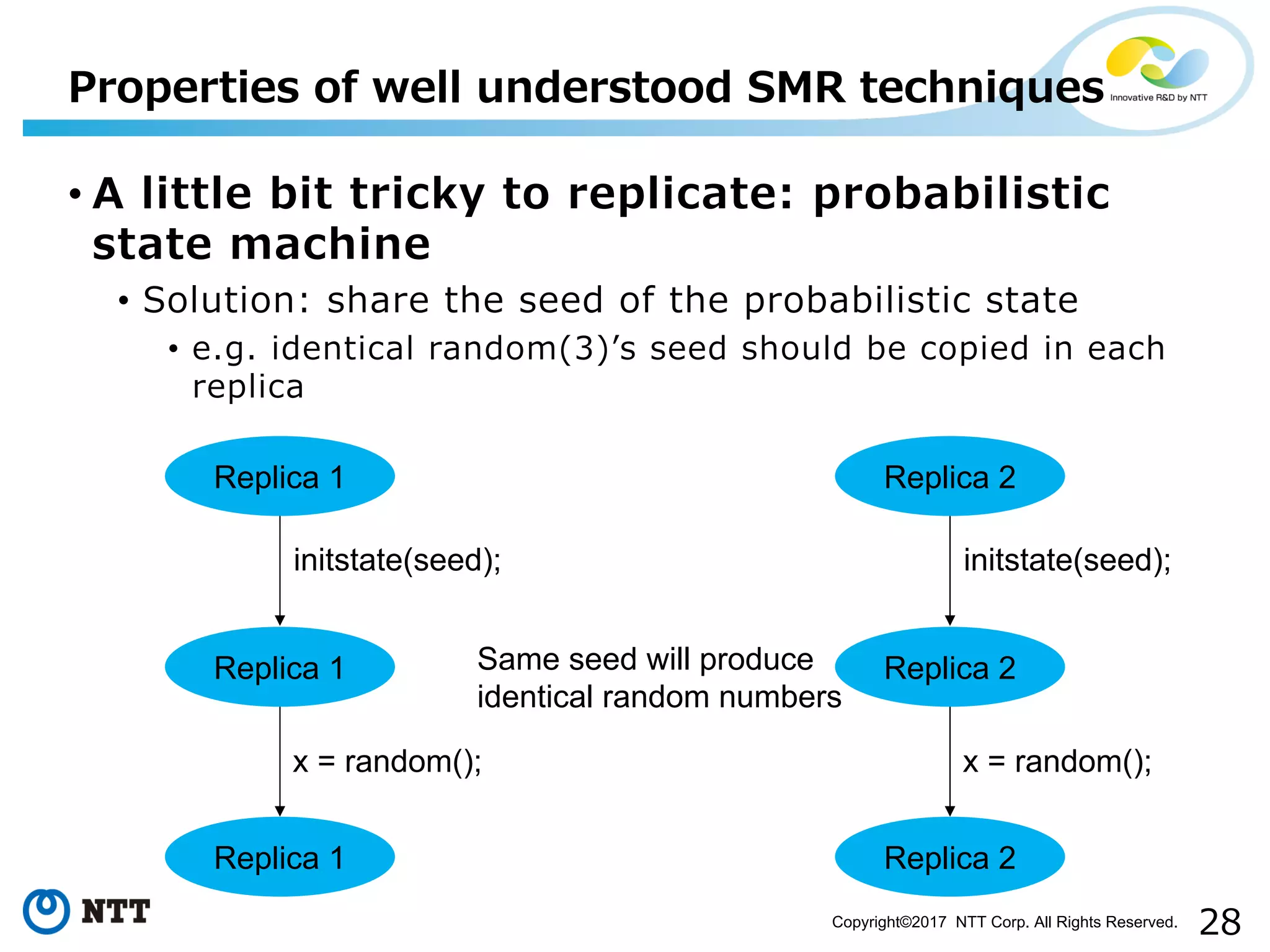
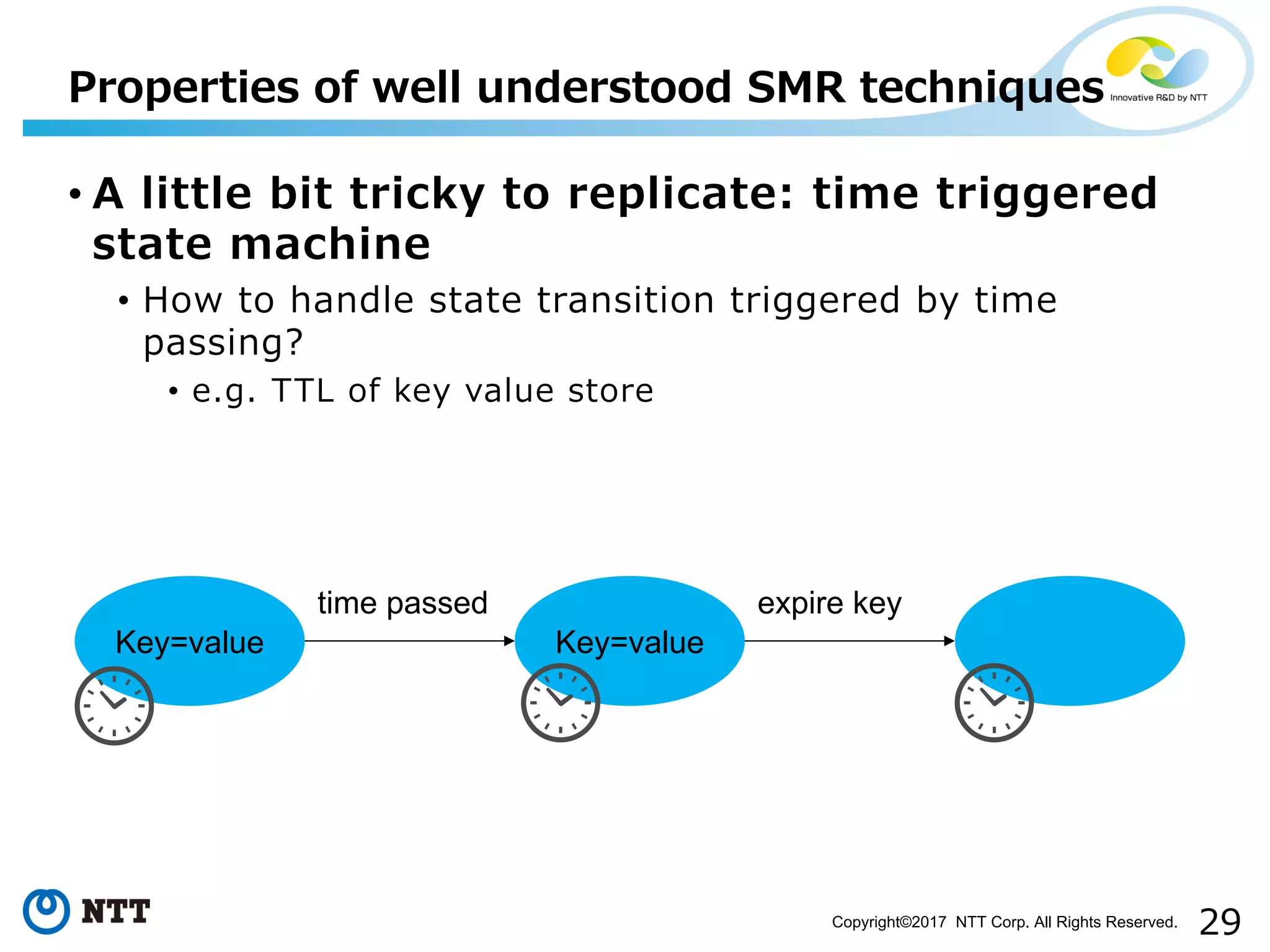
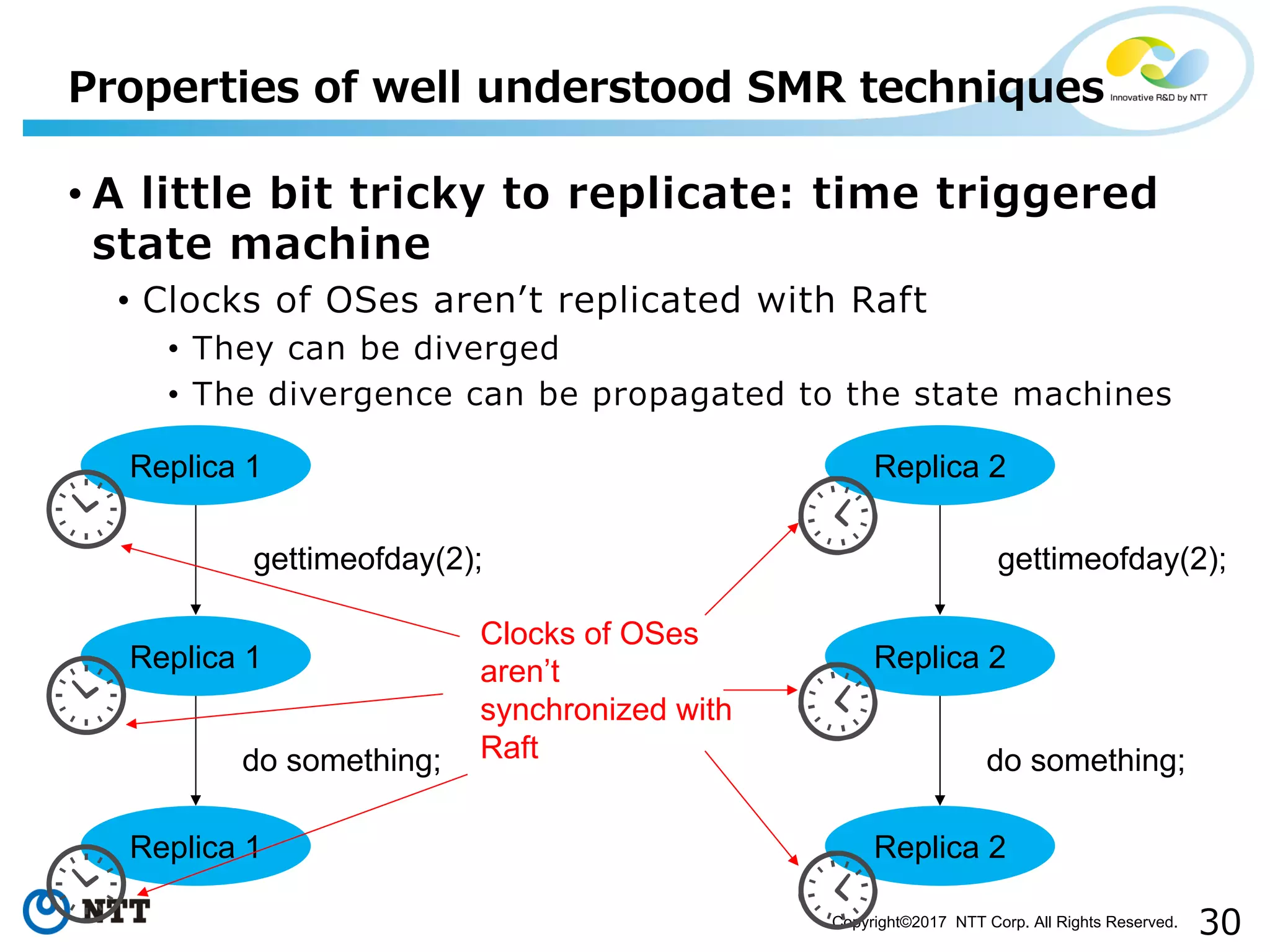
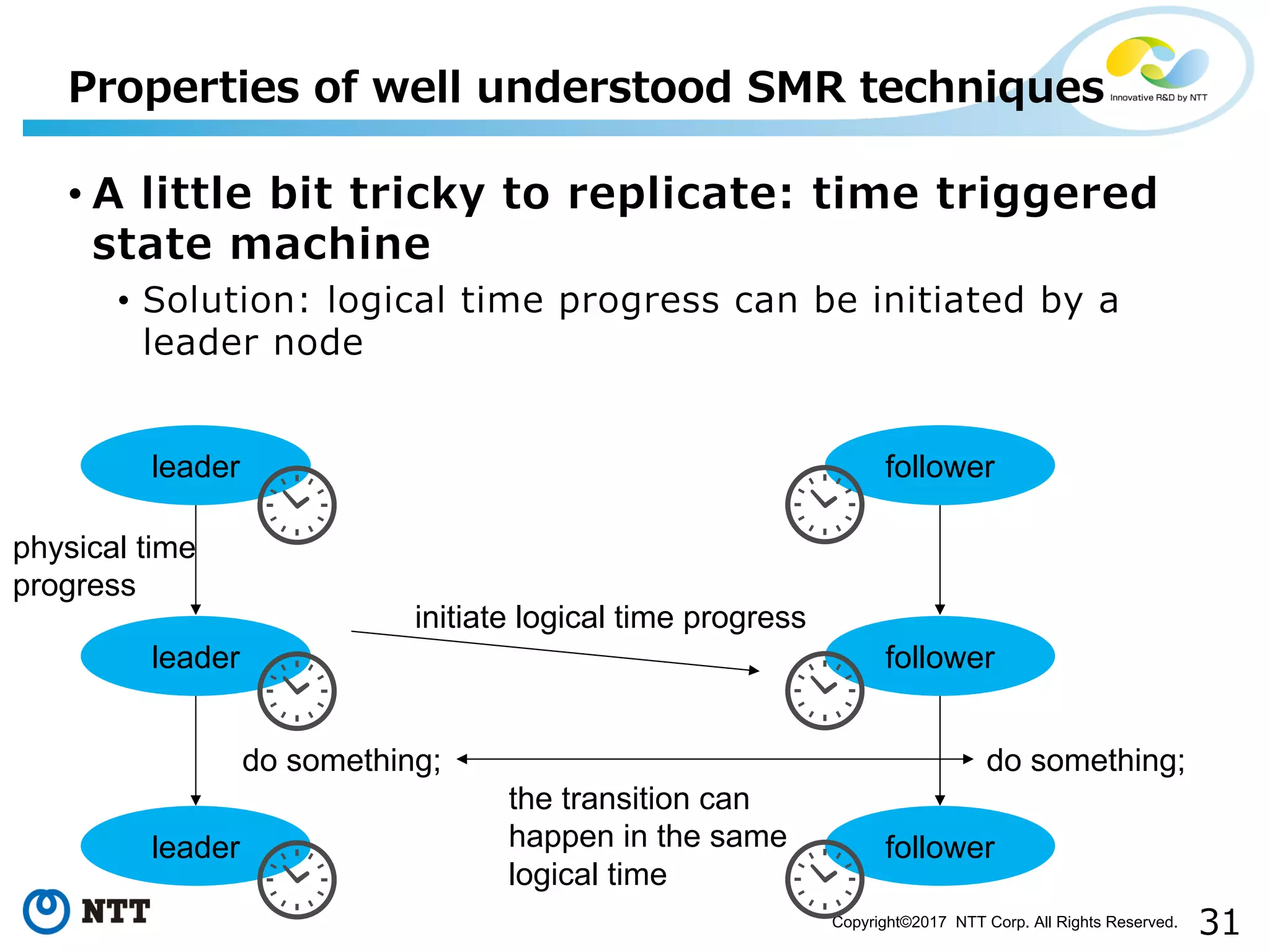
Discussion on challenges like idempotency, probabilistic, time-triggered actions, and non-determinism.
Introduction to etcd, its importance as a KVS, especially in Kubernetes deployments.
Discussion focuses on the performance requirements of distributed systems using etcd and Raft.
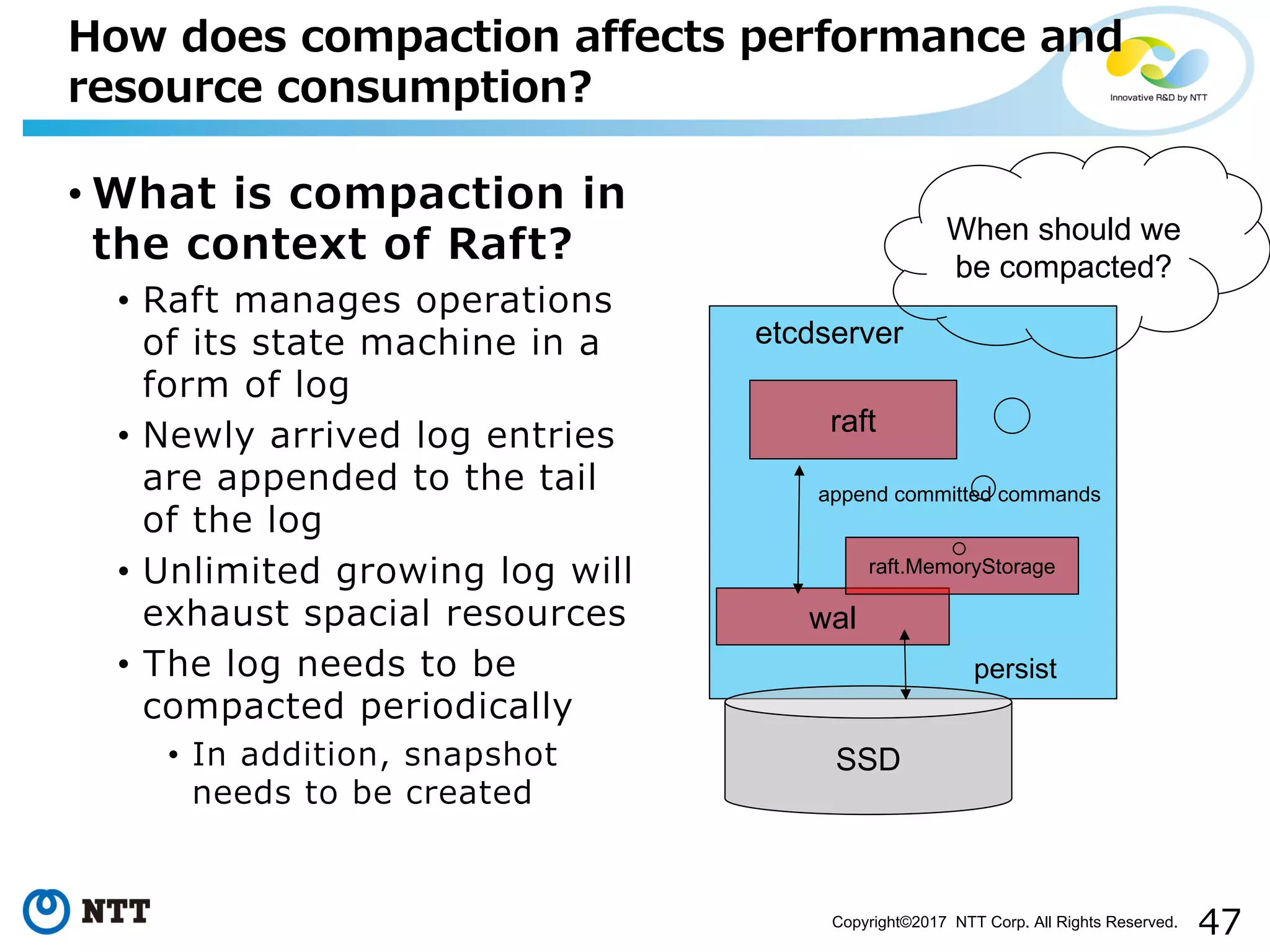
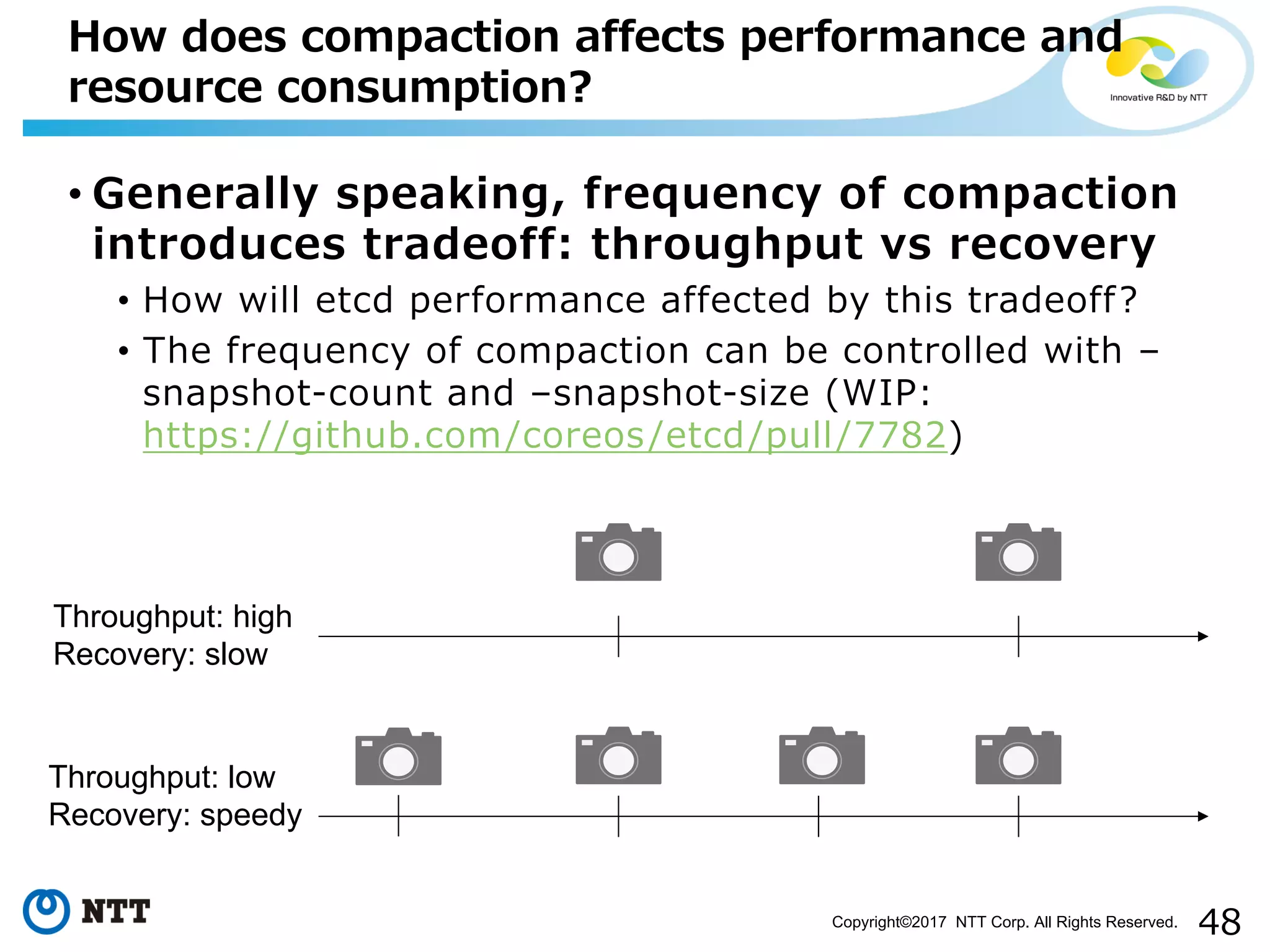
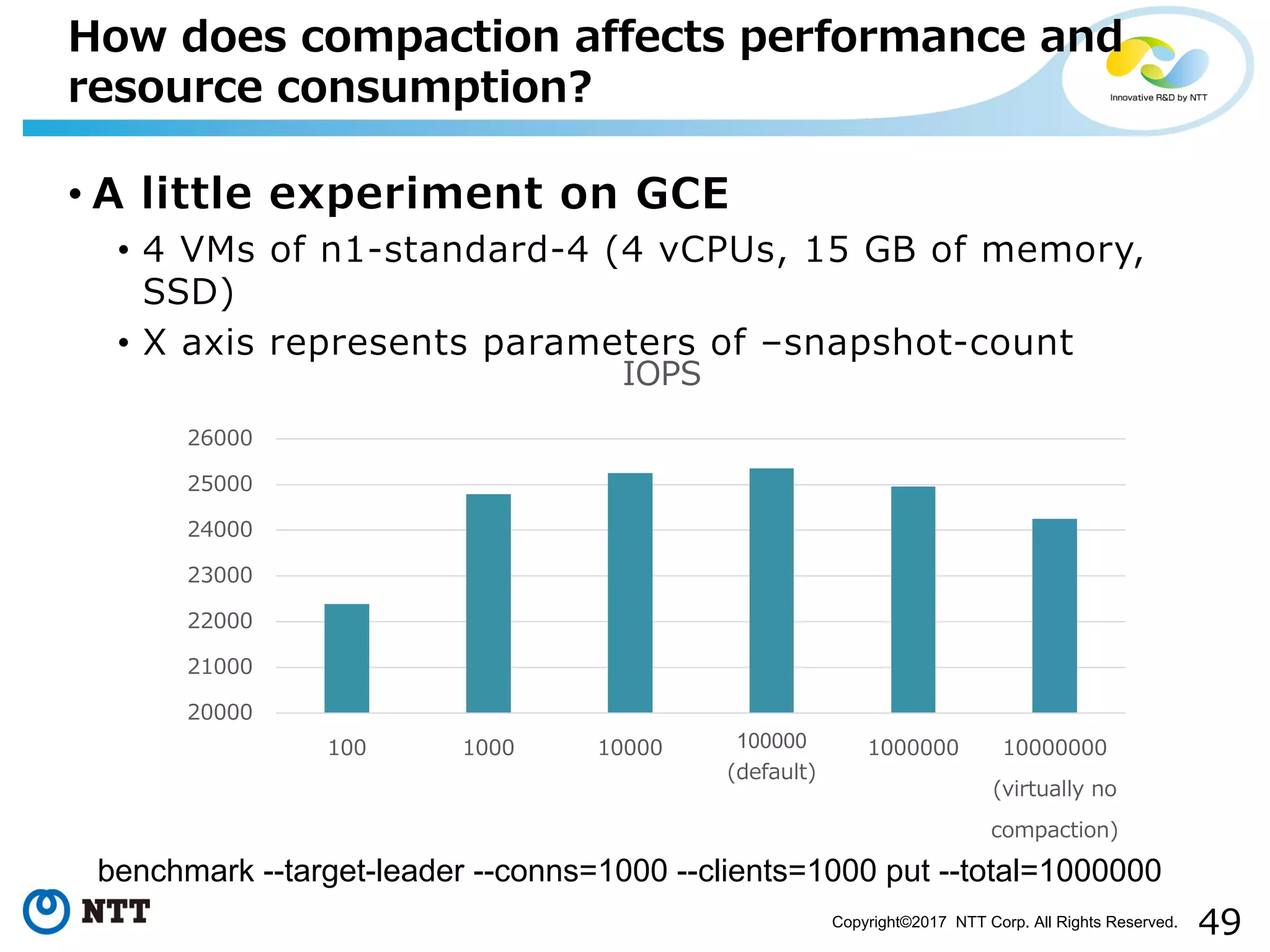
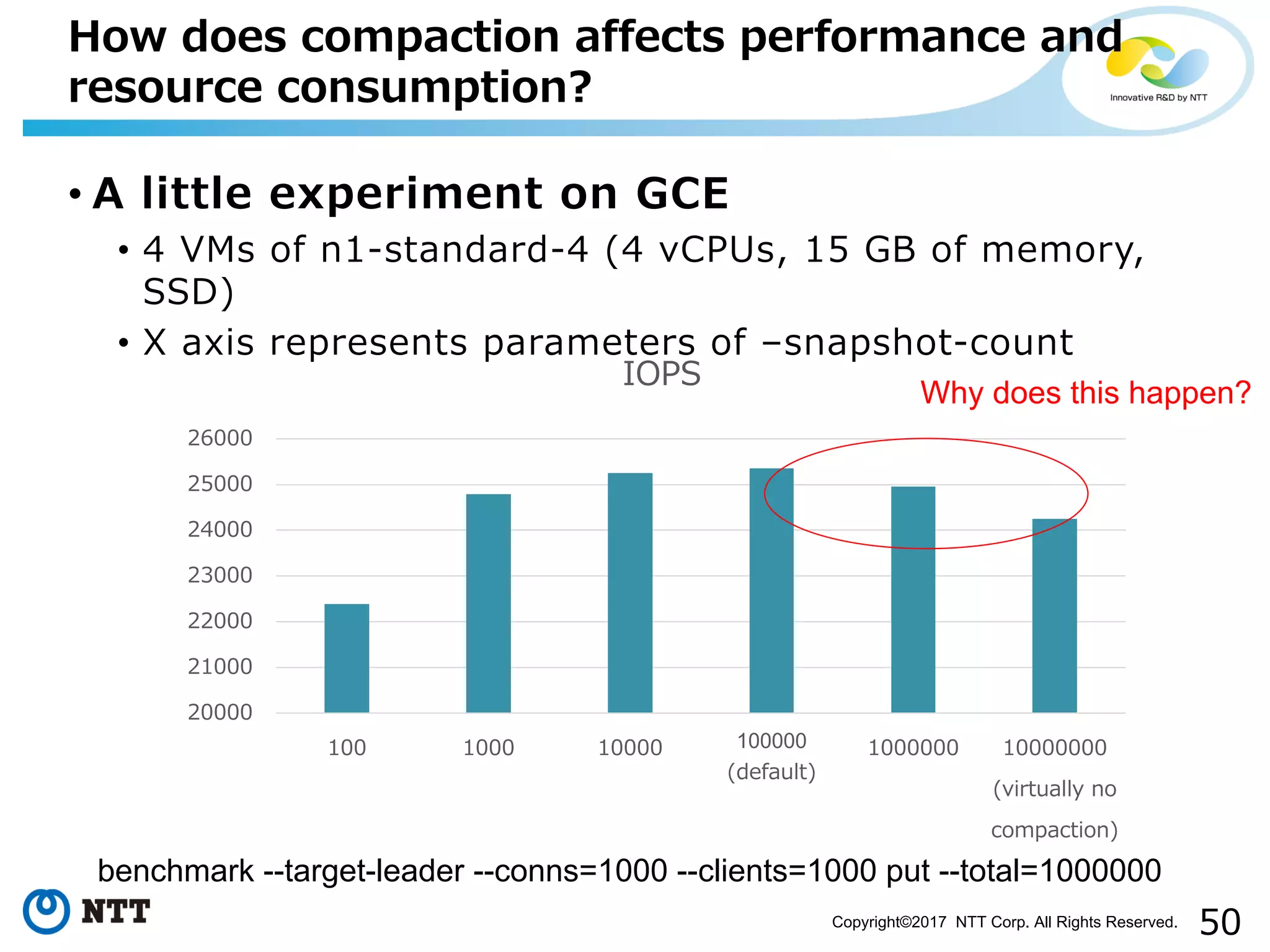
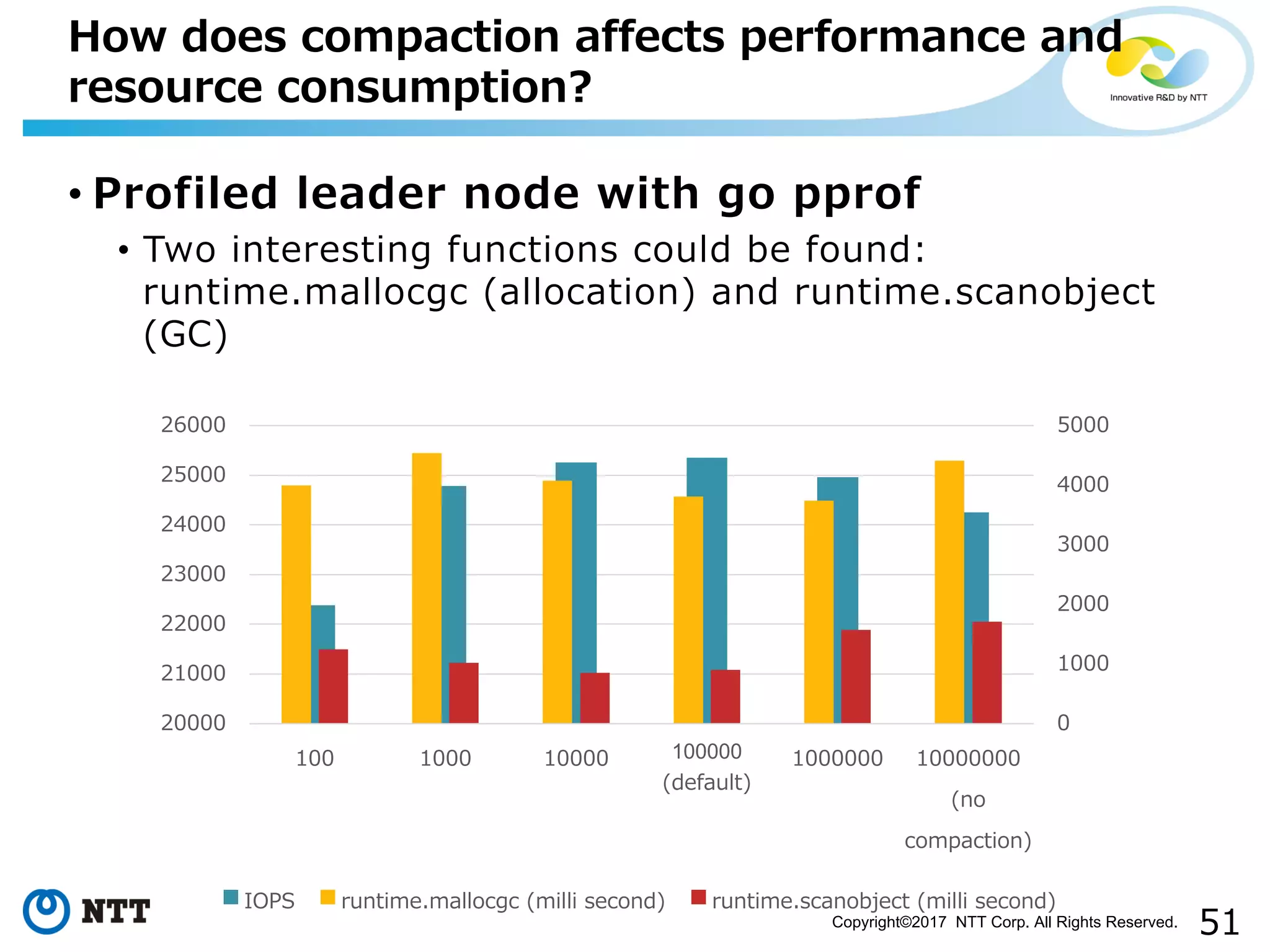
Examines how log management through compaction impacts resource consumption and performance.
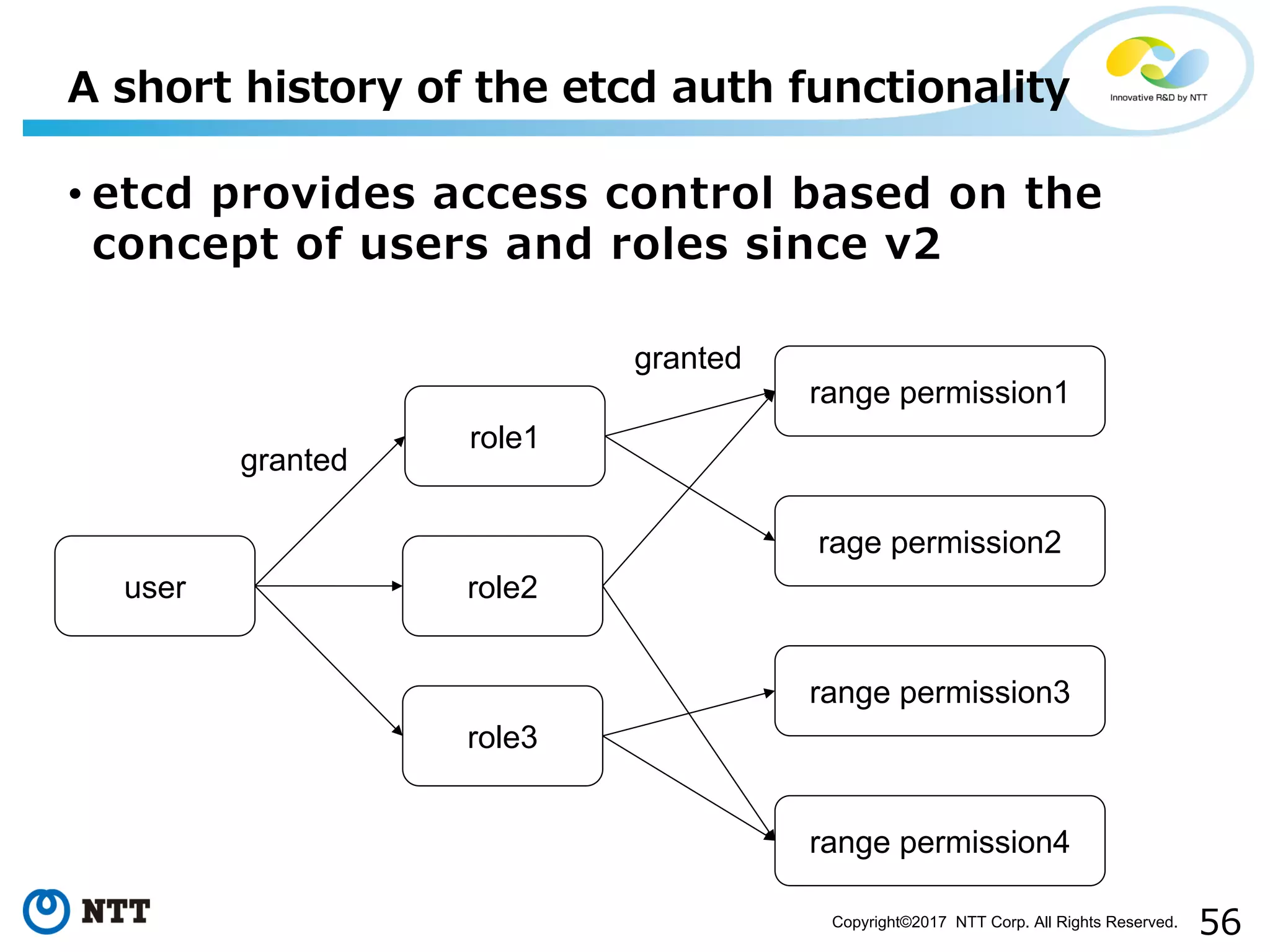
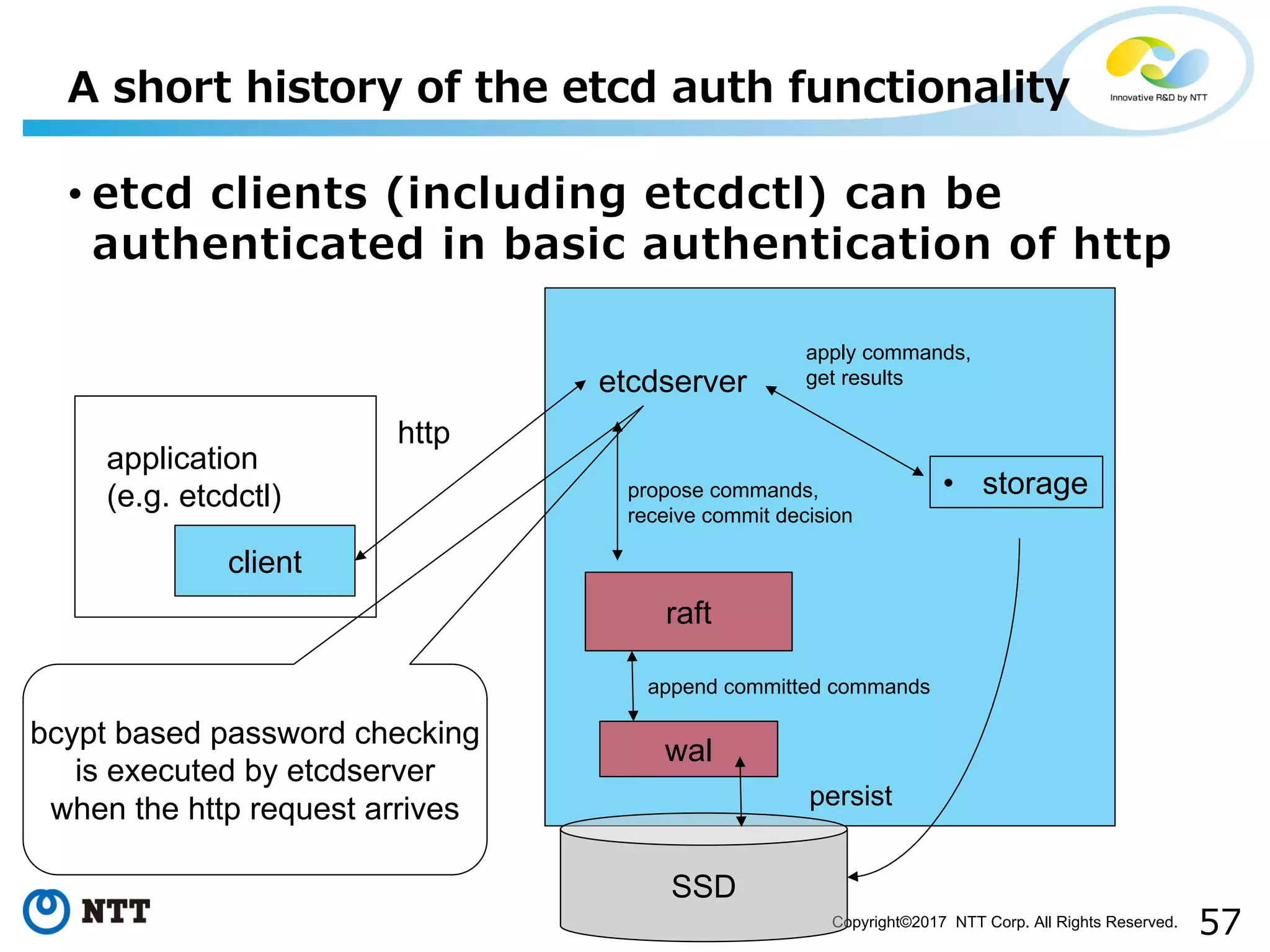
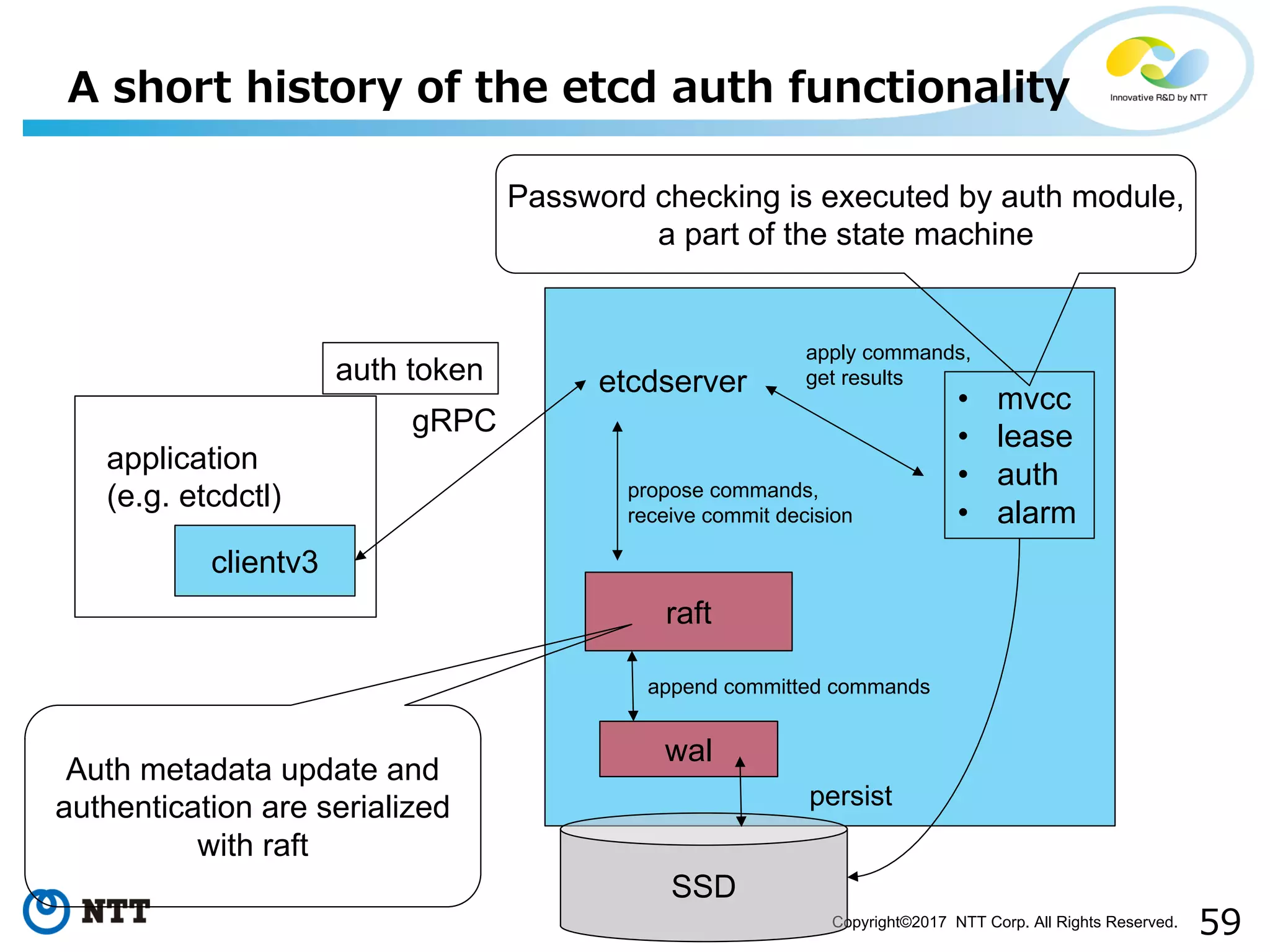
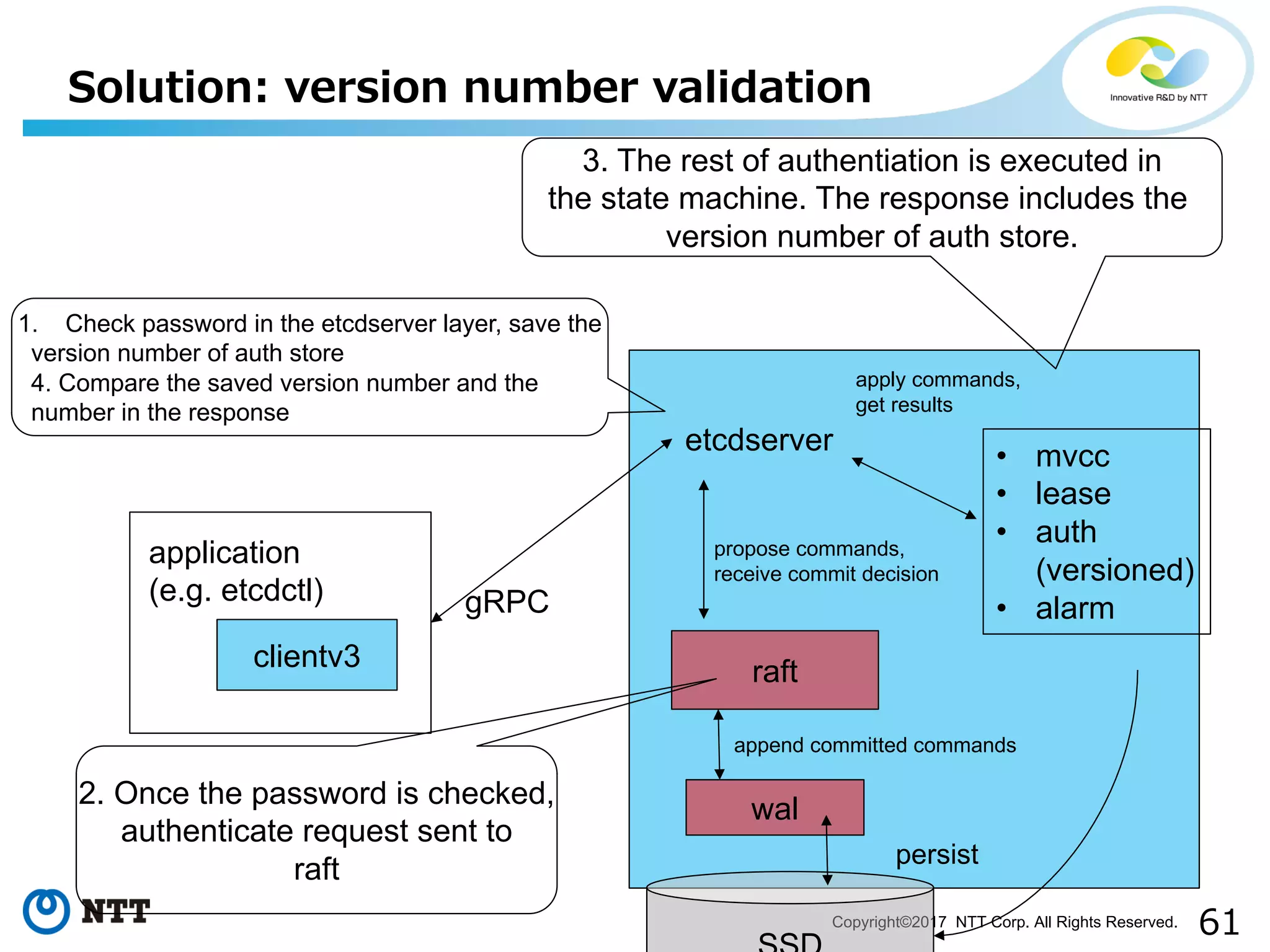
Improvements to etcd authentication process and reducing delays in state machine execution.
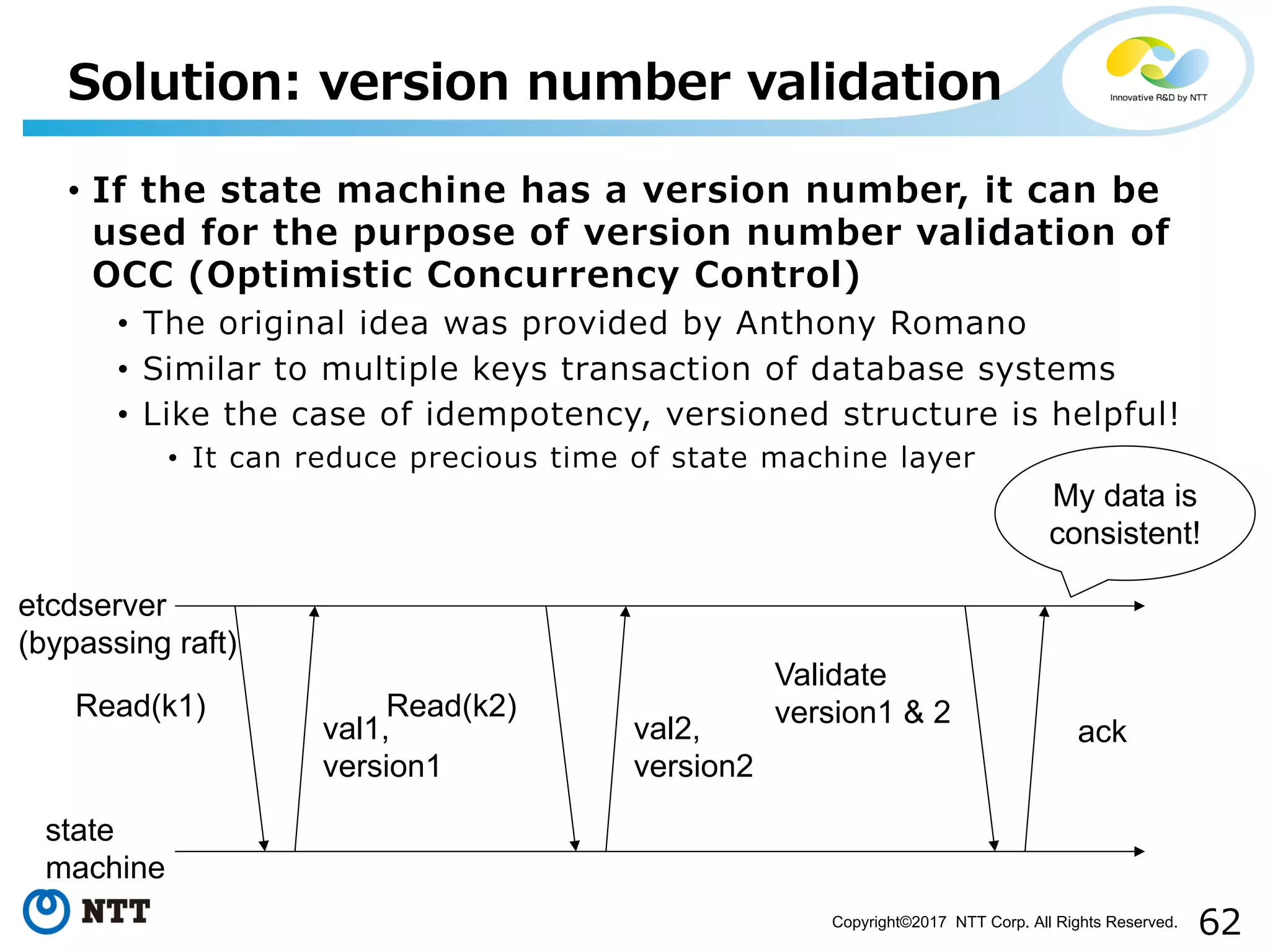
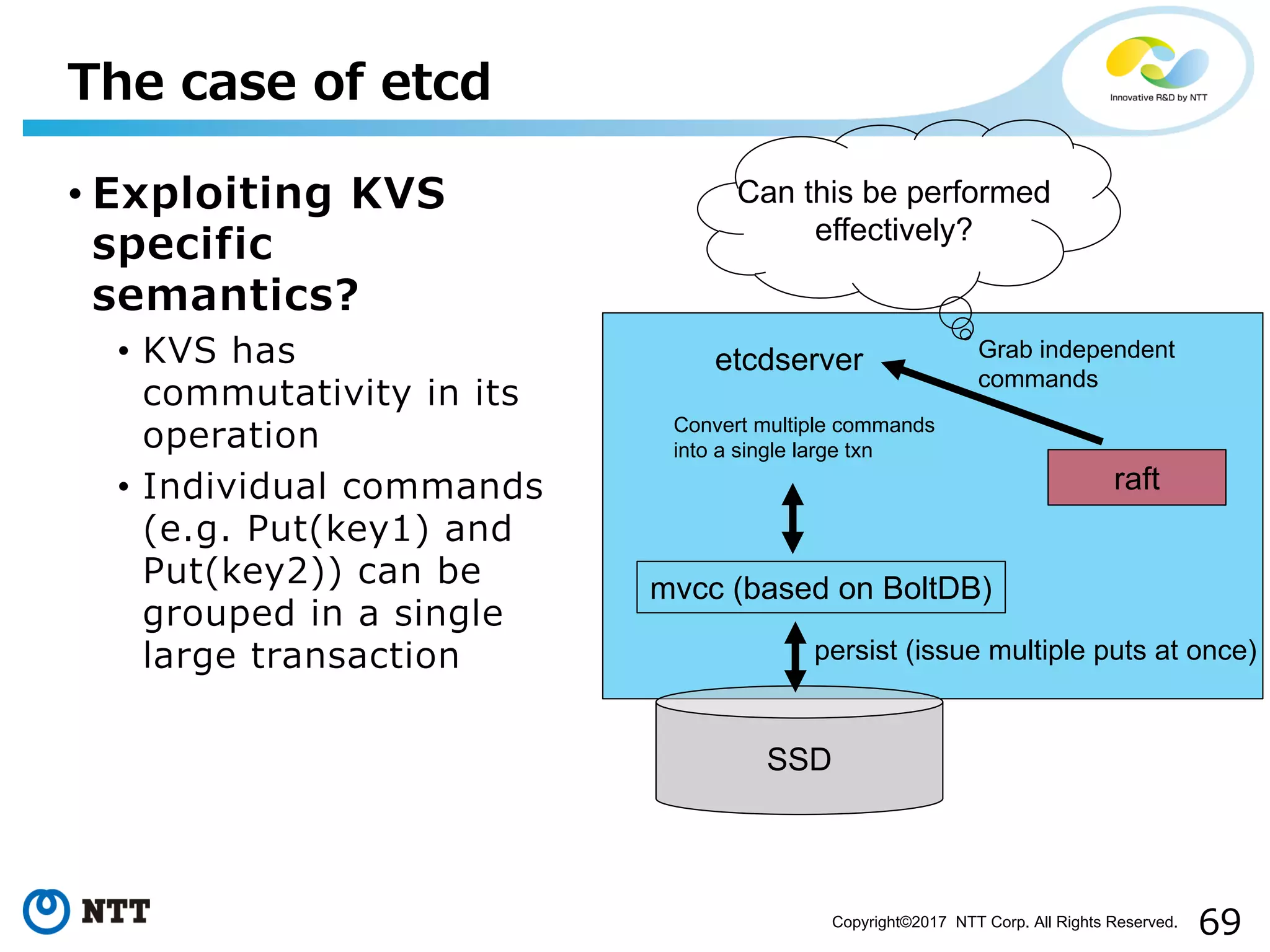
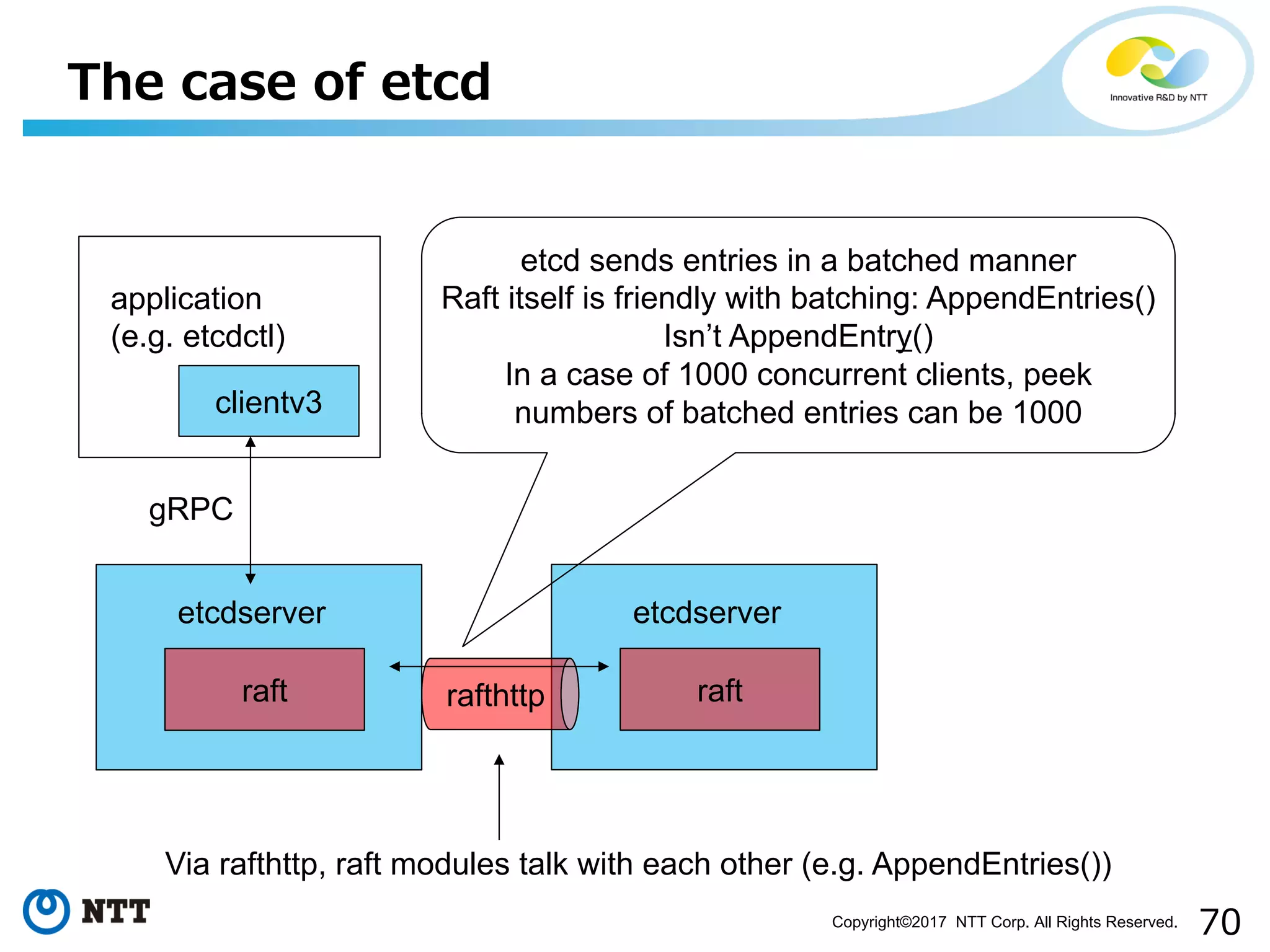
Topics on techniques for improving throughput in state machines and optimization techniques specific to etcd.
Wrap-up of Raft's role in distributed systems, challenges, and opportunities for future work.
Expressing gratitude and providing contact details for further questions.
Includes references and materials relevant to Raft, SMR, and etcd for further reading.



































































