Downloaded 30 times

























![Высшая школа экономики, Москва, 2013
Direct 3D/X vs OpenGL
void init_graphics(void)
{
// create the vertices using the CUSTOMVERTEX struct
CUSTOMVERTEX vertices[] =
{
{ -3.0f, 3.0f, -3.0f, D3DCOLOR_XRGB(0, 0, 255), },
{ 3.0f, 3.0f, -3.0f, D3DCOLOR_XRGB(0, 255, 0), },
{ -3.0f, -3.0f, -3.0f, D3DCOLOR_XRGB(255, 0, 0), },
{ 3.0f, -3.0f, -3.0f, D3DCOLOR_XRGB(0, 255, 255), },
{ -3.0f, 3.0f, 3.0f, D3DCOLOR_XRGB(0, 0, 255), },
{ 3.0f, 3.0f, 3.0f, D3DCOLOR_XRGB(255, 0, 0), },
{ -3.0f, -3.0f, 3.0f, D3DCOLOR_XRGB(0, 255, 0), },
{ 3.0f, -3.0f, 3.0f, D3DCOLOR_XRGB(0, 255, 255), },
};
// create a vertex buffer interface called v_buffer
d3ddev->CreateVertexBuffer(8*sizeof(CUSTOMVERTEX),
0,
CUSTOMFVF,
D3DPOOL_MANAGED,
&v_buffer,
NULL);
….
// select the vertex and index buffers to use
d3ddev->SetStreamSource(0, v_buffer, 0, sizeof(CUSTOMVERTEX));
d3ddev->SetIndices(i_buffer);
// draw the cube
d3ddev->DrawIndexedPrimitive(D3DPT_TRIANGLELIST, 0, 0, 8, 0, 12);
void display(){
// Clear screen and Z-buffer glClear(GL_COLOR_BUFFER_BIT|
GL_DEPTH_BUFFER_BIT);
// Reset transformations
glLoadIdentity();
// Other Transformations
// glTranslatef( 0.1, 0.0, 0.0 );
// Not included
// glRotatef( 180, 0.0, 1.0, 0.0 ); // Not included
// Rotate when user changes rotate_x and rotate_y
glRotatef( rotate_x, 1.0, 0.0, 0.0 );
glRotatef( rotate_y, 0.0, 1.0, 0.0 );
// Other Transformations
// glScalef( 2.0, 2.0, 0.0 ); // Not included
glBegin(GL_POLYGON);
glColor3f( 1.0, 0.0, 0.0 ); glVertex3f( 0.5, -0.5, -0.5 ); // P1 is red
glColor3f( 0.0, 1.0, 0.0 ); glVertex3f( 0.5, 0.5, -0.5 ); // P2 is green
glColor3f( 0.0, 0.0, 1.0 ); glVertex3f( -0.5, 0.5, -0.5 ); // P3 is blue
glColor3f( 1.0, 0.0, 1.0 ); glVertex3f( -0.5, -0.5, -0.5 ); // P4 is purple
glEnd();
int main(int argc, char* argv[]){
// Initialize GLUT and process user parameters
glutInit(&argc,argv);
// Request double buffered true color window with Z-buffer
glutInitDisplayMode(GLUT_DOUBLE | GLUT_RGB | GLUT_DEPTH);
// Create window
glutCreateWindow("Awesome Cube");
// Enable Z-buffer depth test
glEnable(GL_DEPTH_TEST);
// Callback functions
glutDisplayFunc(display); glutSpecialFunc(specialKeys);
// Pass control to GLUT for events
glutMainLoop();
// Return to OS
return 0;
}](https://image.slidesharecdn.com/random-131006154159-phpapp01/75/08-32-2048.jpg)







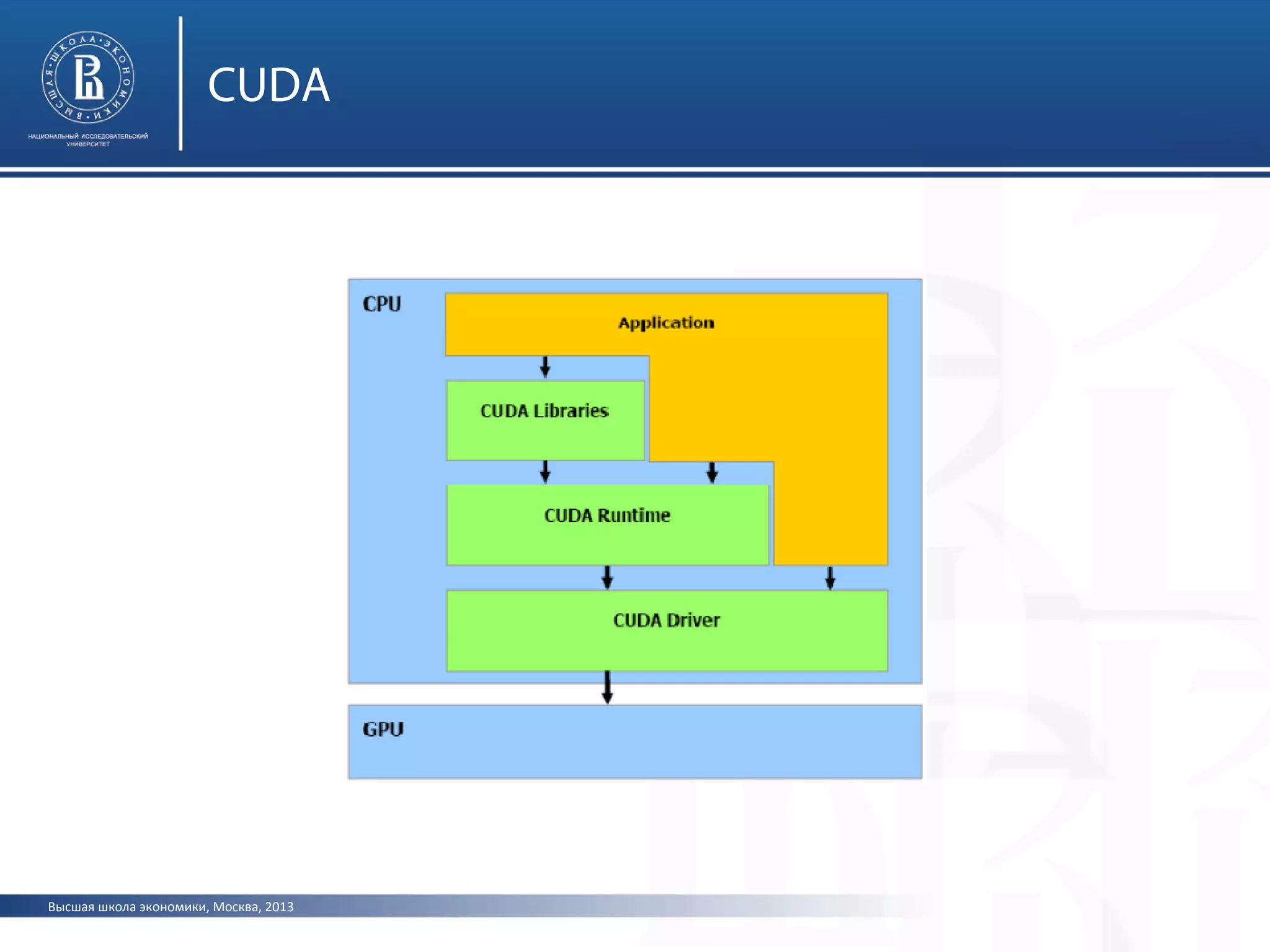







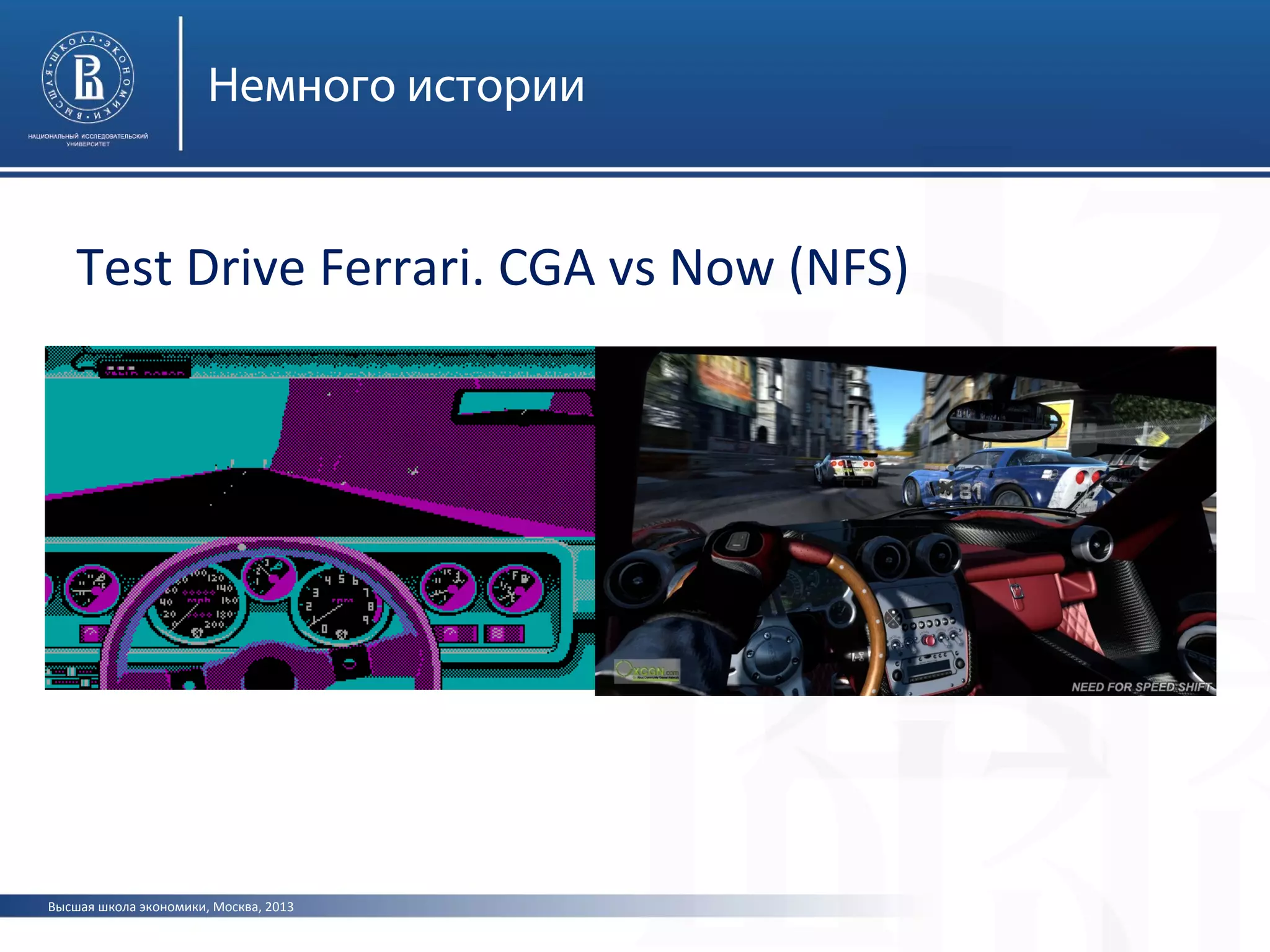
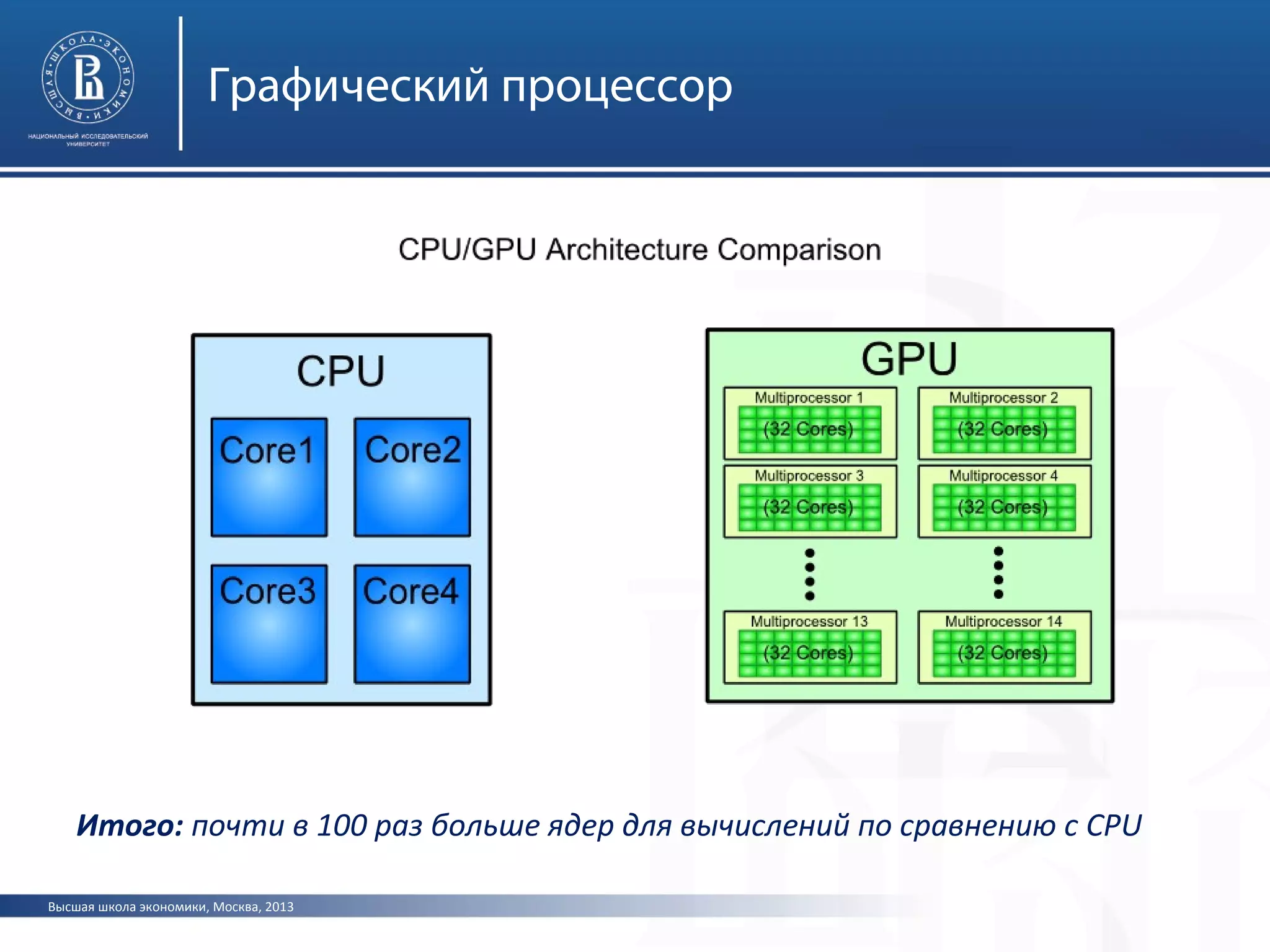
Документ представляет лекцию о видеоадаптерах, видеокартах и ускорителях, охватывающую их историю, устройство и принципы работы. Особое внимание уделяется графическим процессорам, параллельным вычислениям с использованием CUDA и API для графической обработки, таких как OpenGL и Direct3D. Лекция также обсуждает современные достижения в области видеокарт и их применение в вычислительных кластерах.



























