Downloaded 48 times









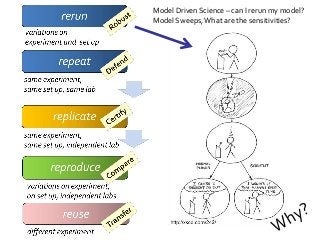
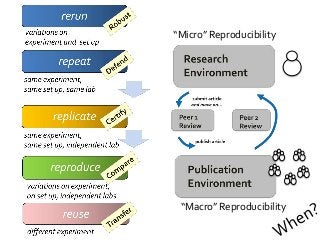
![Repeat, Replicate, Robust
Why the differences?
Reproduce
[CTitus Brown]
https://2016-oslo-repeatability.readthedocs.org/en/latest/repeatability-discussion.html](https://image.slidesharecdn.com/whatisreproducibility-goble-clean-160406120003/85/What-is-reproducibility-goble-clean-14-320.jpg?cb=1459944348)



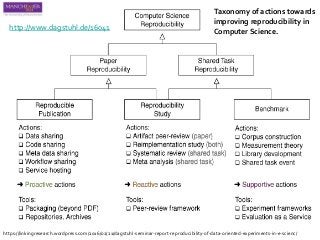






![Levels of Computational Reproducibility
Coverage: how
much of an
experiment is
reproducible
OriginalExperimentSimilarExperimentDifferentExperiment
Portability
Depth: how much of an experiment is available
Binaries +
Data
Source Code /
Workflow
+ Data
Binaries +
Data +
Dependencies
Source Code /
Workflow
+ Data +
Dependencies
Virtual Machine
Binaries +
Data +
Dependencies
Virtual Machine
Source Code /
Workflow
+ Data +
Dependencies
Figures +
Data
[Freire, 2014]
Minimum:
data and source
code available
under terms
that permit
inspection and
execution.](https://image.slidesharecdn.com/whatisreproducibility-goble-clean-160406120003/85/What-is-reproducibility-goble-clean-31-320.jpg?cb=1459944348)
![Repeatable Environments
*https://2016-oslo-repeatability.readthedocs.org/en/latest/overview-and-agenda.html
[C.Titus Brown*]
Metadata Objects : Reproducible Reporting, Exchange
Checklist
ProvenanceTracking
Versioning
Dependencies
container](https://image.slidesharecdn.com/whatisreproducibility-goble-clean-160406120003/85/What-is-reproducibility-goble-clean-32-320.jpg?cb=1459944348)
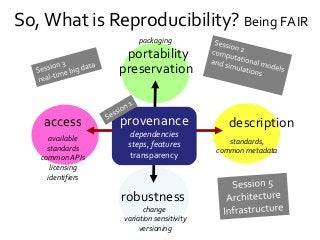



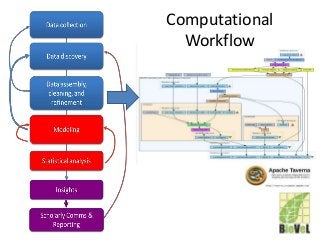
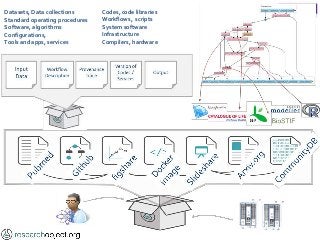
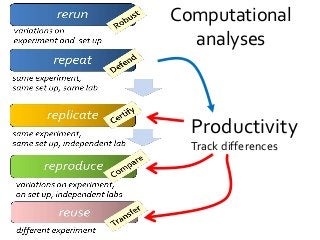
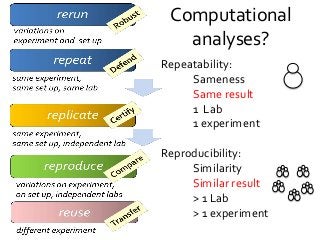
What is Reproducibility? “When I use a word," Humpty Dumpty said in rather a scornful tone, "it means just what I choose it to mean - neither more nor less.”[1]. Its the same with Reproducible. Reusable. Repeatable. Recomputable. Replicable. Rerunnable. Regeneratable. Reviewable. Its R* mayhem. Or pride [2]. Does it matter? At least it does for computational science. Different shades of "reproducible" matter in the publishing workflow, depending on whether you are testing for robustness (rerun), defence (repeat), certification (replicate), comparison (reproduce) or transferring between researchers (reuse). Different forms of "R" make different demands on the completeness, depth and portability of research [3]. If we view computational tools (software, scripts) as instruments - “data scopes” rather than “telescopes” or “microscopes” – then we need to be clear when we talk about reproducible computational experiments about whether we are rerunning with the same set up on the same (preserved) instrument (say a Virtual Machine), or reproducing the instrument to replicate the experiment (say a description of an algorithm recoded) or repairing the instrument so we can reuse it for some other experiment (say replacing a defunct web service or a deprecated library). Confused? In this talk I will discuss the R* brouhaha and its practical consequences for computational data driven science. [1] Lewis Carroll, Through the Looking-Glass (1872) [2] David De Roure, More Rs than Pirates http://www.scilogs.com/eresearch/more-rs-than-pirates/ [3] Juliana Freire, Philippe Bonnet, Dennis Shasha, Computational reproducibility: state-of-the-art, challenges, and database research opportunities SIGMOD '12 Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data: 593-596, ACM New York, NY, USA, doi>10.1145/2213836.2213908






























































