No sql storage systems an architects view
•
3 likes•686 views

This is an attempt to compare different noSql stores from an architect's point of view.

Recommended
More Related Content
Similar to No sql storage systems an architects view
Similar to No sql storage systems an architects view (20)
Recently uploaded
Recently uploaded (20)
No sql storage systems an architects view
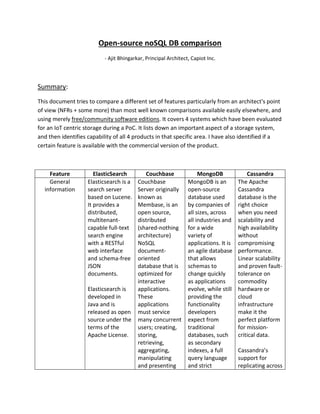
- 1. Open-source noSQL DB comparison - Ajit Bhingarkar, Principal Architect, Capiot Inc. Summary: This document tries to compare a different set of features particularly from an architect's point of view (NFRs + some more) than most well known comparisons available easily elsewhere, and using merely free/community software editions. It covers 4 systems which have been evaluated for an IoT centric storage during a PoC. It lists down an important aspect of a storage system, and then identifies capability of all 4 products in that specific area. I have also identified if a certain feature is available with the commercial version of the product. Feature ElasticSearch Couchbase MongoDB Cassandra General information Elasticsearch is a search server based on Lucene. It provides a distributed, multitenant- capable full-text search engine with a RESTful web interface and schema-free JSON documents. Elasticsearch is developed in Java and is released as open source under the terms of the Apache License. Couchbase Server originally known as Membase, is an open source, distributed (shared-nothing architecture) NoSQL document- oriented database that is optimized for interactive applications. These applications must service many concurrent users; creating, storing, retrieving, aggregating, manipulating and presenting MongoDB is an open-source database used by companies of all sizes, across all industries and for a wide variety of applications. It is an agile database that allows schemas to change quickly as applications evolve, while still providing the functionality developers expect from traditional databases, such as secondary indexes, a full query language and strict The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault- tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission- critical data. Cassandra’s support for replicating across
- 2. data. In support of these kinds of application needs, Couchbase is designed to provide easy-to- scale key-value or document access with low latency and high sustained throughput. It is designed to be clustered from a single machine to very large scale deployments. consistency. MongoDB is built for scalability, performance and high availability, scaling from single server deployments to large, complex multi-site architectures. By leveraging in- memory computing, MongoDB provides high performance for both reads and writes. MongoDB’s native replication and automated failover enable enterprise-grade reliability and operational flexibility. multiple data- centers is best- in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages. Cassandra’s data model offers the convenience of column indexes with the performance of log-structured updates, strong support for denormalization and materialized views, and powerful built-in caching. License and version Free edition (Apache), with commercial plug- ins Version: 1.7.2 Apache 2.0 Commercial editions come with several features and support. Source code available only in EE. Version: 4.0.0.RC Community edition is free, Enterprise edition is subscription based. Version: 3.0.6 Community edition is free. Enterprise edition is subscription based, and there are significant gaps. Version: 2.0.14 Storage JSON JSON BSON (binary Data is stored in
- 3. encoded JSON) column families, in an immutable SSTable, which is sort of a map of maps. In order to work with json document, a json has to be mapped as an map. Written In Java Erlang C++ Java REST Interface Monitoring capabilities Through paid plug-in, none with free version. May be third party plug-ins are available. REST and CLI based monitoring is available for node as well as for a bucket. Console shows several logs as well. Tools are provided, and a web console too is provided running on port 1000. Special tools like cloud manager or in-premises cluster manager, are available with Enterprise edition only. Through JMX and a tool called node tool. Commercial version has OpsCenter. Reporting capabilities or Dashboards Kibana, free dashboard. No special tools which are out of the box. There are some custom projects, and one using ElasticSearch and its Kibana dashboard for reporting and BI. Nothing out of the box, but several third party tools are available to build a dashboard. Building a custom one seemed easy using JSONStudio. MMS is not free. Nothing out of the box, but several third party tools are available to build a dashboard. JasperSoft, Pentaho, and even MicroSoft Excel (with ODBC drivers) can be used for BI, reporting. Commercial
- 4. version has Admin UI as well as OpsCenter. APIs for integration Java API, JMX, Excellent REST interface Java, REST, node, Python Drivers: Java, Perl, Python, node, Scala, C++ Java, node, Go, Python, C#, Ruby etc. Commercial product offers more language bindings. Security None with free version; requires Shield which is paid. elasticsearch- jetty has been claimed to provide password based security, and role based access. Simple password based authentication is available. Advanced auth available with commercial edition. Password based and X509 based auth is available. Advanced security like LDAP integration with Enterprise Edition. Simple password based authentication is available. Enterprise level security is with commercial edition. Support for events (Alerts/Notificati ons) None, requires paid plug-in. Watcher (paid) is quite powerful. Alerts regarding basic system level monitoring are supported. Functional alerts like changes in documents etc. can be notified, but no alerts at this point in time. Not supported except for some basic system alerts. Through commercial editions (MMS) and MongoLab (for Cloud) alerts are available. Seems not to be there from initial reading. HA-Cluster mgmt, replication, XDCR (Cross data center replication) etc. Cluster mgmt can be done manually and also through elasticsearch- head plug-in Nicely done through UI. Master to master replication through replica- Automatic fail- over through leader election when master fails for 10 seconds. Peer to peer distributed cluster, with no single point of failure.
- 5. which allows for UI based cluster monitoring. Replication (async) is configurable, and creating cluster is automatic because of auto- discovery. XDCR: NA sets. Auto scaling. Asynchronous replication Automatic failover supported. XDCR supported. Asynchronous replication. Cluster mgmt UI is available too. DR easily supported. Highly available cluster, XDCR supported. DR easily supported. Access Control None with free version Simple user name/password based. Role based access control Password/role based. Commercial version offers extensive control mechanism. Query language Query DSL. REST API uses json like query parameters. N1QL No specific name. Queries are made on collection docs, and query parameters are like json. REST API too uses json like query parameters. JavaScript like queries can be executed using Mongo shell. CQL Transactions/Dur ability Not designed to be an ACID compliant system. Supports ACID transactions on a per-document level. Document level ACID compliance seems to be in place. Durable, eventual consistent. String consistency
- 6. Supports concurrent updates to an individual document, but not across multiple documents. For further concurrency, ES supports locking. You can use either CAS (Check and Set/Compare and Swap) for optimistic concurrency or use GetAndLock to actually lock a document for pessimistic concurrency scenarios. Further support for concurrent updates can come through usage of locks. Generally it is one write lock, and a shared access for multiple concurrent reads. through replication factor. Further support for concurrent updates can come through usage of locks. Connectors Spark, Hadoop, Storm, Hadoop, Kafka, ElasticSearch, Spark, also an SDK is provided ES, Spark, Hadoop, API is available. Miscellaneous Based on Apache Lucene. User friendly. Extends memcashed protocol. User friendly. Can handle high velocity data; however some folks have commented about operational complexity. Based on Dynamo (clustering) and BigTable (data model). Can handle very high incoming data velocity. Top time series data storage. Data model could be the key. UPSERT performance on a scale of 5 3.5 4 4 5 Query performance on a scale of 5 3.5 Friendly [An index per data type is a good idea.] 3.5 [Some limitations like joins across buckets] 4 Fast 4 Fast
- 7. References: 1. http://developer.couchbase.com/documentation/server/4.0/introduction/editions.html 2. http://mobz.github.io/elasticsearch-head/ 3. http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis 4. http://www.altoros.com/download_white_papers.html 5. http://jsonstudio.com/mongodb-reporting-5-minutes/ 6. http://codehardblog.azurewebsites.net/real-time-data-analytics-with-couchbase-and- elasticsearch/ 7. http://info.couchbase.com/Couchbase105-Dec3.html 8. http://www.couchbase.com/connect/agenda/enterprise-reporting-visualization-bi-etl- couchbase-n1ql-odbc-jdbc/ 9. http://foorious.com/blog/2014/09/cassandra-json/ 10. https://academy.datastax.com/demos/brief-introduction-apache-cassandra 11. http://bigdata-madesimple.com/a-deep-dive-into-nosql-a-complete-list-of-nosql- databases/