Downloaded 11 times







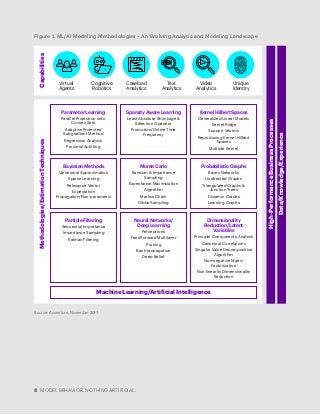


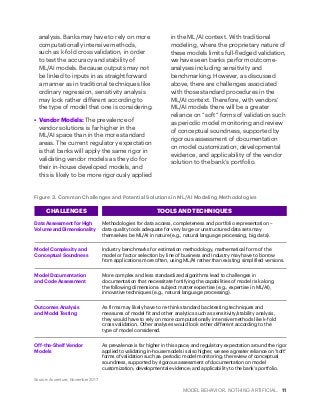
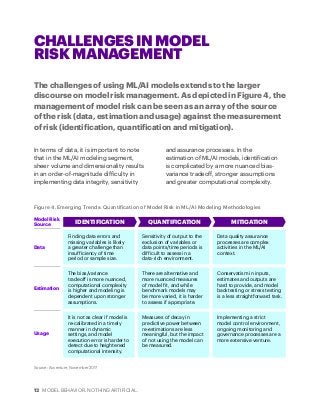









Machine learning and artificial intelligence are poised to make a big impact in financial services. Employing some of the techniques discussed in this Accenture paper, financial services companies can significantly benefit from ML/AI solutions through enhanced sophistication and increased efficiency in their day-to-day business operations.















































