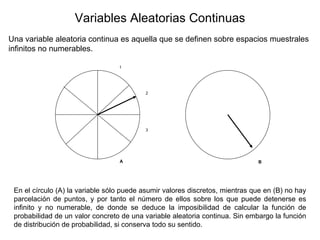
1. Variables Aleatorias Continuas Una variable aleatoria continua es aquella que se definen sobre espacios muestrales infinitos no numerables. En el círculo (A) la variable sólo puede asumir valores discretos, mientras que en (B) no hay parcelación de puntos, y por tanto el número de ellos sobre los que puede detenerse es infinito y no numerable, de donde se deduce la imposibilidad de calcular la función de probabilidad de un valor concreto de una variable aleatoria continua. Sin embargo la función de distribución de probabilidad, si conserva todo su sentido. A B 1 2 3
2. Comparemos las representaciones gráficas de una v.a. Discreta y una v.a. Continua Variables Aleatorias Continuas En las v.a. Discretas los valores de x i aparecen como un número de barras concretas, mientras que en las v.a. Continuas aparecen como una curva que abarca cierto rango de los valores del eje de abcisas y cubren un área igual a 1
3. Variables Aleatorias Continuas: Función de Densidad Las variables continuas poseen un número infinito de valores. Por tanto no hablamos de función de probabilidad, sino de Función de Densidad de Probabilidad (FDP) entorno a un valor (ejemplo de la edad). Una función de densidad asocia valores de la variable X con ordenadas o alturas de la curva en cada punto f(x). Se llama función de densidad de probabilidad de una v.a. continua X, a aquella que cumple las siguientes condiciones: a) La función sólo genera valores positivos b) El área o superficie total es la unidad
4. Variables Aleatorias Continuas: Función de Densidad Veamos un ejemplo de la gráfica obtenida mediante la función de densidad de probabilidad:
5. Variables Aleatorias Continuas: Función de Distribución La interpretación de la Función de Distribución de Probabilidad para v.a. Continuas es la misma que para las v.a. Discretas. Ahora bien, puesto que se trata de una variable continua, el sumatorio de la función de probabilidad de los valores de X iguales o menores que x i queda como la integral entre - y x i de la función de densidad de probabilidad: Dado que la Función de Densidad de Probabilidad define una gráfica continua, su integral definirá el área comprendida entre dicha función y el eje de abcisas . Debido a esto, se suele identificar la función de distribución de un valor x i dado como el área bajo la curva que queda a la izquierda de dicho punto , considerando, lógicamente, que el área comprendida entre - y + es la unidad.
6. Vemos representada el área bajo la curva que queda a la izquierda del punto x i (1,3). Teniendo en cuenta que el área total bajo la curva es 1, x i (1,3) vale: Variables Aleatorias Continuas: Función de Distribución
7. Si deseásemos calcular la probabilidad de obtener un valor entre 1 y 1,3, equivaldría, según la analogía que hemos explicado, a calcular el área señalada en la figura, que, calculada de forma análoga a como lo hacíamos en el caso de las variables aleatorias discretas, será: Variables Aleatorias Continuas: Función de Distribución
8. En la práctica el trabajo con v.a. continuas en las ciencias sociales consiste en hallar probabilidades, para alguno de estos tres casos: Variables Aleatorias Continuas a) Calcular la probabilidad de que la observación sea como mucho igual a un determinado valor, o probabilidad acumulada de ese valor. b) Calcular la probabilidad de que la observación sea igual o superior a un determinado valor. Que no es más que el complementario de la probabilidad acumulada. c) Calcular la probabilidad de que la observación hecha esté comprendida entre dos valores cualesquiera. Integrando del valor menor al mayor o restando la probabilidad acumulada del menor de la probabilidad acumulada del mayor.
9. Funciones de Probabilidad o de Densidad Importantes en Psicología En Psicología en la mayoría de los casos nos encontramos variables cuyas funciones de probabilidad o de densidad de probabilidad se ajustan a una fórmula concreta. Por ejemplo para v.a. discretas vimos dos tipos de funciones: binomial y poisson. Para el caso de v.a. continuas veremos que las distribuciones de probabilidad de mayor importancia son: Distribución Normal, χ 2 , t de Student y F de Snedecor. Sin embargo haremos especial énfasis a la distribución normal.
10. La Distribución Normal La Distribución Normal es muy importante en Estadística debido a dos razones principales: 1) Es la función de distribución de probabilidad que sirve como modelo a más variables de la Naturaleza. En el ámbito de la psicología, una gran cantidad de variables objeto de la disciplina sigue esta distribución cuando el número de observaciones es suficientemente elevado: la inteligencia, la estatura, la motivación de logro, la autoestima, etc. 2) Las medias de una serie de muestras de n observaciones extraídas al azar de una población, tienden a distribuirse normalmente a medida que n aumenta. Esta propiedad, muy importante, se denomina " Teorema del límite central ".
11. La Distribución Normal En la gráfica podemos observar el porqué de su universalidad. En la mayor parte de las variables existe un valor central (la media) en torno al cual se concentran la mayor parte de las observaciones, y a medida que nos vamos alejando de este valor central, observamos que los valores observados son menos frecuentes. μ – σ μ μ + σ
12. Una variable aleatoria, se distribuye según el modelo normal, con parámetros μ y σ, N(μ,σ) si su función de densidad de probabilidad para todo valor de X viene dado por: π = 3.1416; e = 2.718 La Distribución Normal Esta propiedad es muy importante y nos permite generar las tablas de probabilidad de la curva normal. En efecto, puesto que la media de las puntuaciones típicas es 0 y su desviación típica 1, la función de densidad de probabilidad normal (que ahora se denomina "función de densidad de probabilidad normal estandarizada“ queda: En el exponente de la función podemos reconocer la fórmula de la tipificación y por tanto si definimos f(x) para variables tipificadas μ = 0 y σ = 1 la función de densidad de esta nueva variable sería N(0,1):
13. Las variables cuya distribución se ajusta al modelo normal adoptan una representación gráfica, cuyas características fundamentales son: 1.- Es simétrica con respecto a un valor central μ, y en ese valor coinciden la media, la mediana y la moda. 2.- Es asintótica con respecto al eje de abscisas; es decir por mucho que se extienda, nunca llega a tocar los ejes, y sólo en la altura de la curva llegaría a ser igual a 0. 3.- Hay toda una familia de curvas normales, dependiendo de los valores de μ y σ. De entre ellas, la más importante es aquella con μ = 0 y σ = 1 para la que se ha propuesto el nombre de distribución normal unitaria. 4.- Los puntos de inflexión se encuentran en los puntos correspondientes a la media ± una desviación típica ( μ ± σ ) 5.- Cualquier combinación lineal de variables aleatorias normales se ajusta también al modelo normal. Las variables que se ajustan a la distribución normal
15. El trabajo práctico fundamental con variables aleatorias normales, consiste en determinar probabilidades asociadas a valores, lo cual nos conduce a la integración de la función de densidad normal entre los valores de interés. Calculo de Probabilidades en la Distribución Normal Superficie acumulada hasta el valor z i de la variable aleatoria normal Z. Superficie o densidad por encima de un valor z i de la variable aleatoria Z 1.22 1.22
16. Superficie entre dos valores z i de la variable aleatoria normal Z. Calculo de Probabilidades en la Distribución Normal 0,2 1,22
17. Para evitar el tener que integrar cada vez que deseemos conocer las distintas áreas calculadas anteriormente, se han construido tablas con dichas probabilidades ya halladas. La Distribución Normal: tablas Distribución normal unitaria
18. Área bajo la curva Normal ¿Qué valor z i deja por debajo de sí al 84.13% de la distribución? Hablamos de un valor superior a la media dado que el porcentaje solicitado supera al 50%. Buscamos en la tabla z i > 0 el valor z que más se acerque al % acumulado. Este valor es z = 1 ,8621 ,8599 ,8577 ,8554 ,8531 ,8508 ,8485 ,8461 ,8438 ,8413 1,0 . . . . . . . . . . . . . . . . . . . . . . ,5359 ,5319 ,5279 ,5239 ,5199 ,5160 ,5120 ,5080 ,5040 ,5000 0,0 9 8 7 6 5 4 3 2 1 0 z
19.
20. Regla de tipificación Según esta regla, la función de distribución de probabilidad asociada a un valor de una variable normal X, con media μ y varianza σ 2 es igual a la de la tipificada de ese valor en la distribución normal unitaria. Es decir: Z 0,67 = 0,44 : Indica que en la distribución normal unitaria el valor 0,44 tiene una probabilidad acumulada, o área izquierda, igual a 0,67. Cualquier valor con subíndice menor de 0,50 será negativo, mientras que el valor 0 tendría un subíndice de 0,50, puesto que el valor 0 es tanto la media como la mediana de la distribución. donde entonces formamos la variable Si
21.
22. Para una probabilidad o probabilidades acumuladas dadas, encontrar el valor de la variable X. Una variable X se distribuye N(50,8) y deseamos obtener los valores de esta variable para los cuales se cumplen las siguientes condiciones: a ) Aquel para el que la probabilidad de observar un valor como máximo igual a él es 0.1736. Se trata de obtener el valor que deja un área a su izquierda igual a 0.1736. Por la regla de la tipificación y acudiendo a la tabla, comprobamos que se trata del valor cuya típica sea igual a -0.94. Basta con tipificar ese valor con respecto a la media y la desviación típica de la distribución 42,48
23. Para una probabilidad o probabilidades acumuladas dadas, encontrar el valor de la variable X. b ) Aquel para el que la probabilidad de observar un valor como mínimo igual a él sea 0.9207. Se trata de obtener el valor que deja un área a su derecha igual a 0.9207. Como la tabla asocia a cada valor su área izquierda (acumulada), la probabilidad buscada será 0.0793 (1 – 0.9207). 38,72
24. Calculo de Probabilidades en la Distribución Normal c ) Aquellos dos valores que acoten el 50% central del área. Se trata de obtener aquellas dos puntuaciones que, tal y como aparece en la figura, dejen a su izquierda y derecha, respectivamente áreas iguales a 0.25 (0.50/2). Según la tabla Z, esas puntuaciones tendrán como típicas los valores -0.67 y 0.67. 44,64 55,36
25. Problema Sabiendo que la variable X se distribuye N(100,20), y extrayendo una observación al azar, determina las probabilidades de que esa observación sea: h) Tenga una p. diferencial mayor o igual de 18 g) Probabilidad de que una observación se separe de la media en más de una desv. típica f) Comprendida entre 112 y 130 e) Comprendida entre 85 y 89 d) Mayor de 63 c) Mayor de 130 b) Menor de 125 a) Menor o igual a 90
26. Distribución Normal ejercicios ¿Qué porcentaje de observaciones queda por debajo de la puntuación directa X=23, teniendo una distribución N(30, 4)? ¿Qué porcentaje de observaciones queda por encima de la puntuación directa X=54, teniendo una distribución N(48, 5)? ¿Qué porcentaje de observaciones queda por encima de la puntuación directa X= 9, y simultáneamente, por debajo de la puntuación directa X= 31, teniendo una distribución N(25, 8)? ¿Qué puntuación directa deja por debajo de sí el 64% de las observaciones teniendo una distribución N(30, 5)? ¿Qué puntuación directa deja por encima de sí el 61% de las observaciones teniendo una distribución N(40, 6)? Calculemos dos puntuaciones directas X 1 y X 2 tales que la primera deje por debajo de sí un 10% de las observaciones y la otra deje por encima el otro 10% teniendo una distribución N(40, 7)? La población de tallados en el servicio militar se distribuye en altura N(1,69; 0,01) y en peso N(68,2; 1,80). Suponiendo que ambas variables son independientes en dicha población. Si seleccionamos un sujeto al azar, ¿cuál es la probabilidad de que su altura y su peso sean superiores a 1,71 y 70 respectivamente?
27. Distribución Normal ejercicios En un examen valorado sobre 10 puntos las calificaciones de un grupo de 250 estudiantes se distribuyen aproximadamente normal con media 5,6 y varianza 2,25. a) ¿cuántos sujetos no pasan del 6? b) ¿cuántos aprueban? Tras administrar la escala de locus de control de James a una muestra de personas depresivas y a otra de sanas, encontramos que las puntuaciones de los primeros se distribuyen aproximadamente normal con media 90 y dt. 12, mientras que las de los segundos se distribuyen también aproximadamente normal, pero con media 100 y dt. 14: 1. Calcula el porcentaje de depresivos, que supera la media de los normales. 2. Calcula la probabilidad de que un sujeto normal supere al 90% de los depresivos. 3. Calcula la puntuación que en la muestra de depresivos deja por debajo la misma proporción de observaciones que la puntuación 80 deja en los normales.
28. 1.- Calcula el porcentaje de depresivos, que supera la media de los normales 2.- Calcula la probabilidad de que un sujeto normal supere al 90% de los depresivos 3.- Calcula la puntuación que en la muestra de depresivos deja por debajo la misma proporción de observaciones que la puntuación 80 deja en los normales Depresivos N(90,12); Normales N(100,14),
29. Distribución Muestral de un Estadístico La estadística inferencial intenta extraer conclusiones de lo particular a lo general, de la muestra a la población, de los estadísticos a los parámetros. Esto se basa en la variabilidad mostrada por un estadístico de una muestra a otra. Es decir en cómo se comporta un estadístico de una muestra a otra. La Estadística Inferencial pretende deducir consecuencias acerca de la población. A partir de los datos obtenidos mediante muestras, es decir, dadas las frecuencias observadas de una variable habrá que inferir el modelo probabilístico que ha generado los datos (Peña, 1986).
30. Distribución muestral de un estadístico Parámetros: μ , σ , π 1. Valor Muestral 2. Calculable a partir de los datos muestrales 3. Variable Aleatoria 1. Valor Poblacional 2. Desconocido 3. Constante ¿Por qué un estadístico es una variable aleatoria? Población Muestra Estadísticos:
31. Distribución muestral de un estadístico Muestra 1 Muestra 2 Muestra 3 Muestra n Si extraigo n muestras de tamaño n y calculo un estadístico ¿será el valor de estadístico el mismo siempre? Esperamos que no sea el mismo valor. Luego el estadístico es una variable, su valor cambia de una muestra a otra. Es una variable aleatoria ya que a la hora de extraer los elementos de n desde la población tienen la misma probabilidad de ser extraídos. (extracción aleatoria y con reposición) Población
32. Distribución Muestral de un Estadístico … Luego si un estadístico es una variable aleatoria, tendrá como tal asignada su función de probabilidad o densidad de probabilidad. Pues bien el término distribución muestral de un estadístico hace referencia a esta distribución de probabilidad. Una distribución muestral es una distribución teórica que asigna una probabilidad concreta a cada uno de los valores que puede tomar un estadístico en todas las muestras del mismo tamaño que es posible extraer de una determinada población. Se puede definir como la función de distribución de probabilidad de un estadístico calculado a partir de una muestra de tamaño n.
33. Distribución muestral de un estadístico Las distribuciones muestrales son tan importantes que si no existieran no habría contraste de hipótesis. Supongamos que tenemos una población N=5 puntuaciones X i {1, 2, 3, 4, 5}. Si de esta población seleccionamos aleatoriamente y con reposición muestras de tamaño n=2 tendremos N n = 5 2 = 25 muestras posibles todas equiprobables (1/25). Si ahora calculamos en cada una de esas muestras el estadístico media llegaremos a este resultado...
35. Distribución muestral de un estadístico Una distribución muestral de un estadístico, en cuanto función de probabilidad nos proporciona la probabilidad asociada a cada uno de los valores que ese estadístico puede tomar en las diferentes muestras de tamaño n que es posible extraer de una población Con esta distribución de frecuencias podemos Calcular la media y desviación típica de la distribución. Si en vez de tener una población N=5 tenemos N=200 y extraemos muestras no de n=2 sino de n=20 y calculamos la media de cada muestra, tendremos la función de distribución de probabilidad de las medias obtenidas a partir de muestras de tamaño 20 de la población propuesta. A esta función de distribución de las medias se la denomina “ DISTRIBUCIÓN MUESTRAL DE LA MEDIA ".
36. Distribución muestral de un estadístico De la misma forma que calculamos la media de cada muestra y obtuvimos en consecuencia la distribución muestral de la media, podríamos haber calculado cualquier otro estadístico para obtener su distribución muestral. Podríamos obtener la distribución muestral de la proporción, la distribución muestral del coeficiente de asimetría, etc. y cada uno de ellos tendría su propia media y desviación típica teóricas. A la desviación típica de la distribución muestral se le denomina “ Error Típico ". Así, el " error típico de la media " será la desviación típica de la distribución muestral de la media.
37. Distribución muestral de la media Si partimos de una muestra aleatoria distribuída N( μ , σ ) y extraemos muestras aleatorias simples de tamaño n y calculamos en cada muestra la media de los n valores.. .. Entonces los valores de esas medias constituyen una variable aleatoria que se distribuye El Teorema Central de Límite permite obviar el supuesto de normalidad si la muestra es grande. Si la variable de partida no es normal, la distribución de medias se distribuye N( μ , σ /√n) si n es moderadamente grande ( ≥ 30)
38. Distribución muestral de la media Ejemplo: Supongamos que la estatura de los varones españoles se distribuye N(172,9). Si extraemos una muestra aleatoria de 20 varones, calculemos las probabilidades de que su media: a) menor de 168; b) mayor de 170; c) comprendida entre 173 y 175. Dadas las condiciones de la media aritmetica de una muestra aleatoria simple de n=20 se distribuye N(172, 9 √20) en consecuencia, la expresion Se distribuye N(0,1)
40. Distribución muestral de la media La edad media de los operarios de una fábrica siderometalúrgica es de 50 años, con una desviación típica de 8. Sabiendo que esa variable se distribuye normalmente, encuentra la distribución muestral de la media para n=10 y n=30. 48.5 47.0 45.6 50 51.5 53 54.4 47.5 44.9 47.5 50 52.5 55 57.6
41. Distribución muestral de la media Razonamiento: Aunque no sabemos cómo se distribuye la variable peso de los recién nacidos, como la muestra es suficientemente grande (n=100), el Teorema Central del Límite nos permite deducir con bastante aproximación la distribución muestral de la media. Si E(X) = 3.5 kg y σ(X) = 0.2 kg. Entonces…