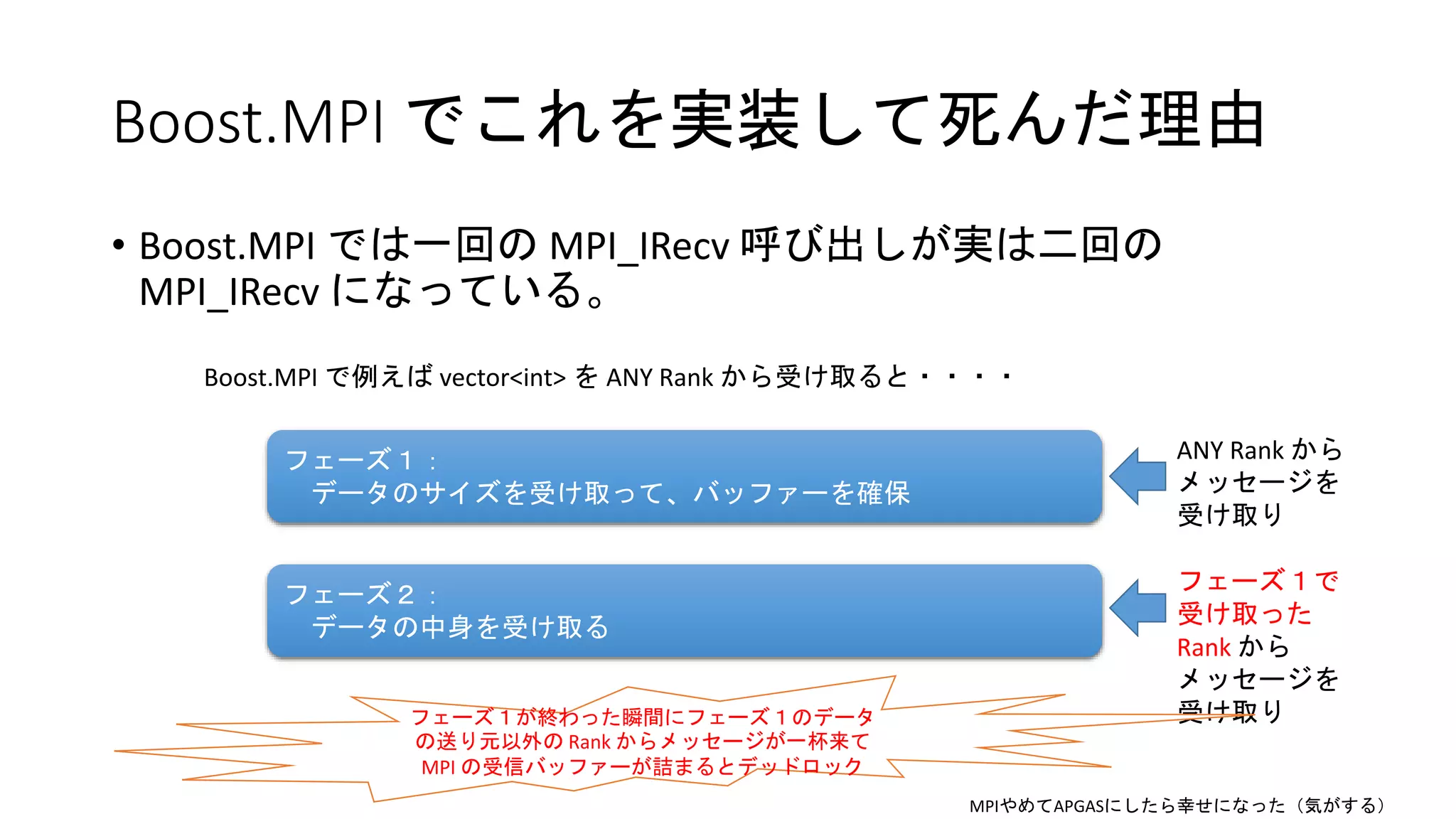
1ノードに収まりきらない巨大なグラフ上でいろいろなヒューリスティックを駆使するアルゴリズムを作ると、MPI ではすぐつらくなる理由を解説。 「Boost.MPI は POD 以外も送れるので、それを使えばなんとかなるよね?」と言われても、やはり使えないと思ってしまう理由を解説。 急いで作ったので練っては居ないが問題は理解して貰えるのではないかと思う。


























![[DDBJ Challenge 2016] 遺伝研スーパーコンピュータのビッグデータ解析環境](https://cdn.slidesharecdn.com/ss_thumbnails/ddbj-challenge2016ishikawa-160713074628-thumbnail.jpg?width=640&height=640&fit=bounds)