本文探讨了云计算的基本概念及其与分布式计算的关系,强调云计算的核心在软件架构而非硬件。文档详细介绍了Hadoop的发展历史、MapReduce算法及其在各行业的应用案例,如中華電信和Yahoo等。最后,提到了未来的数据分析与消费者行为分析等应用展望。












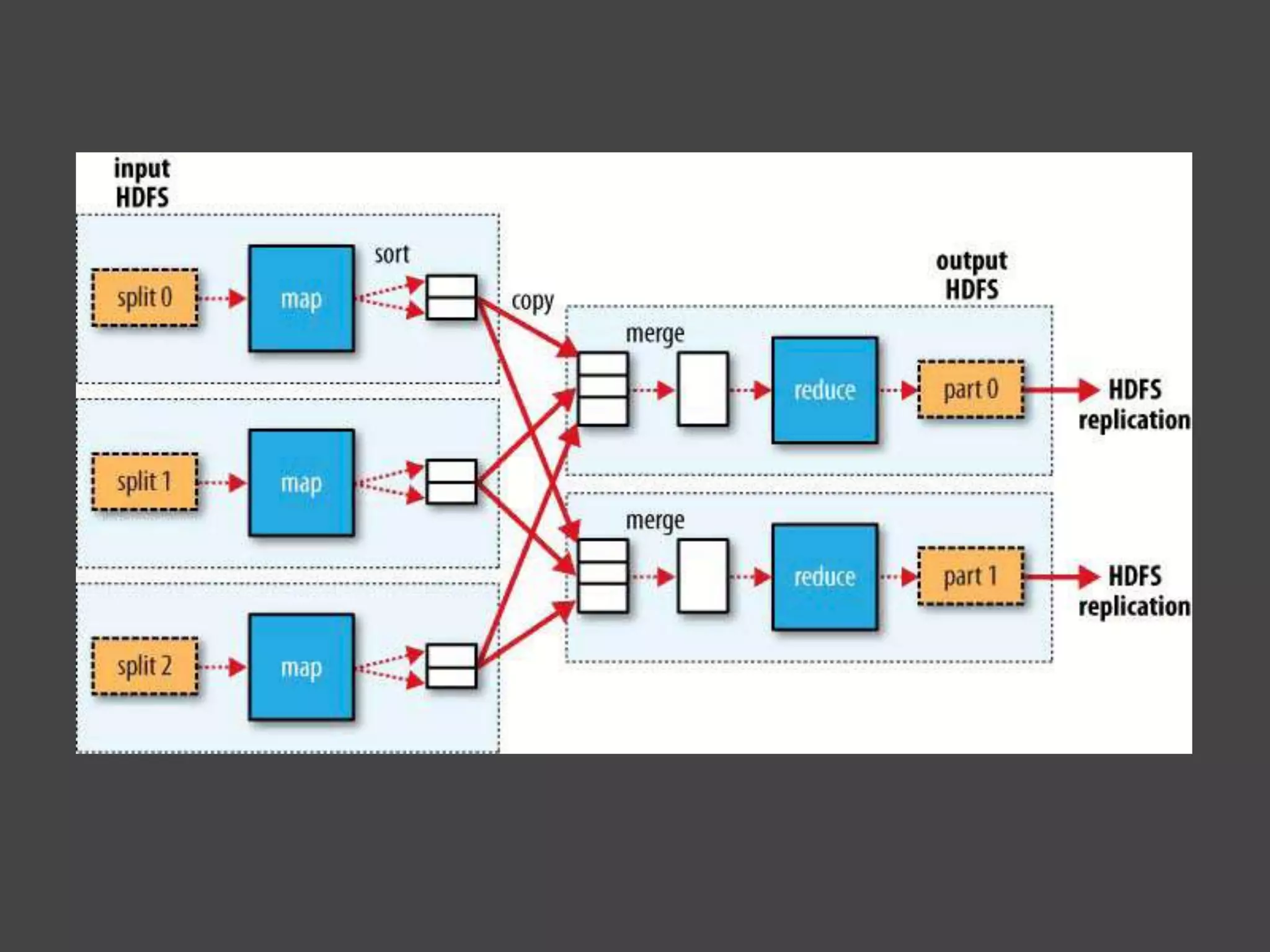
![MapReduce
是一種分散運算的程式架構
要把微程式研究所內的每個同學分數加一分並
且把他的平均值計算出來
f(x) = x+1;
map: map (f[x] , [1,2,3,4,5]) -> [ 2,3,4,5,6];
可平行運算
reduce: (2+3+4+5+6) / 5 = 4;
核心運算不能平行](https://image.slidesharecdn.com/hadoop-110713113355-phpapp01/75/Hadoop-13-2048.jpg)





















![[@NaukriEngineering] Messaging Queues](https://cdn.slidesharecdn.com/ss_thumbnails/queueprocessing-161111064335-thumbnail.jpg?width=640&height=640&fit=bounds)























