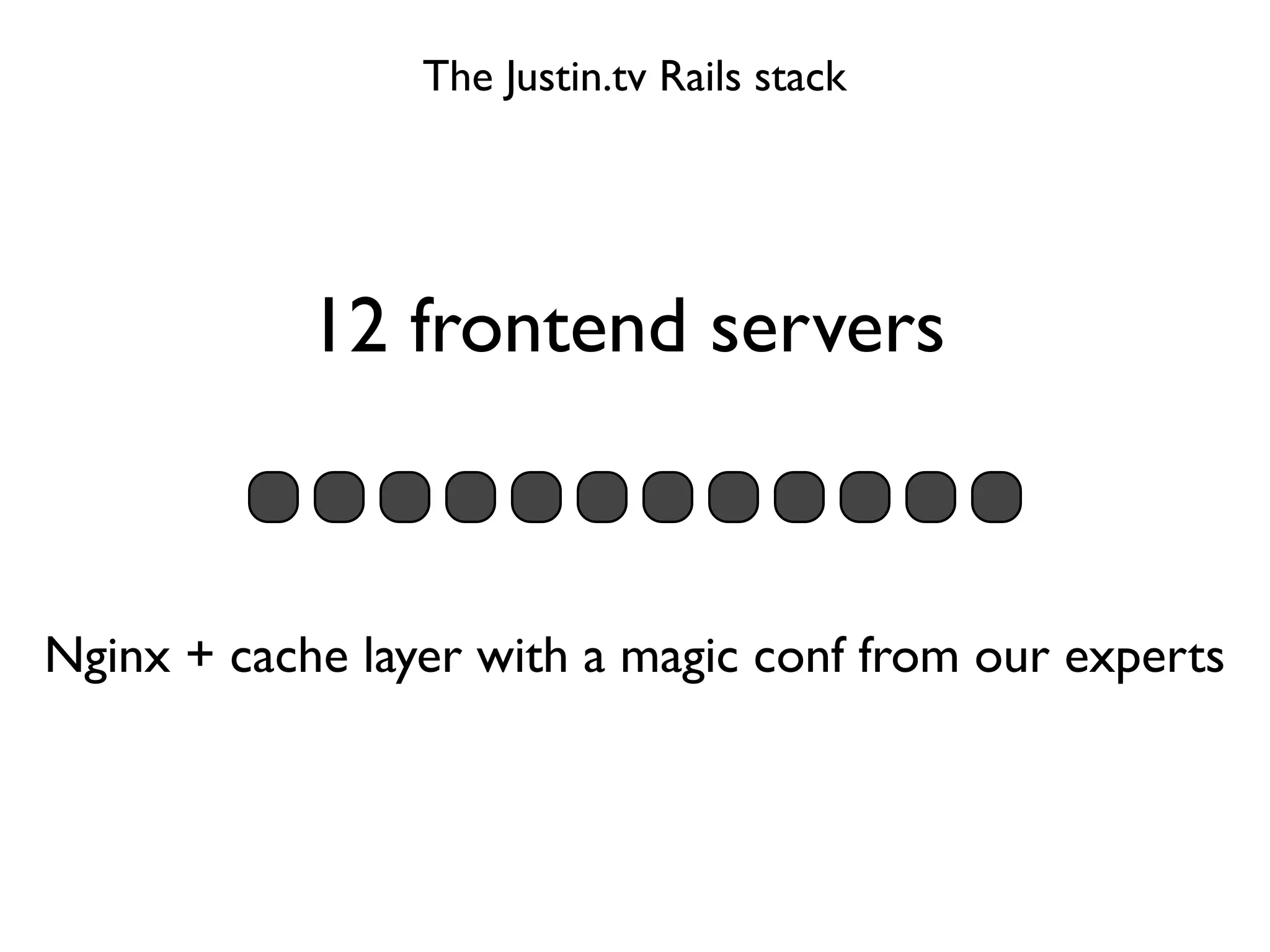
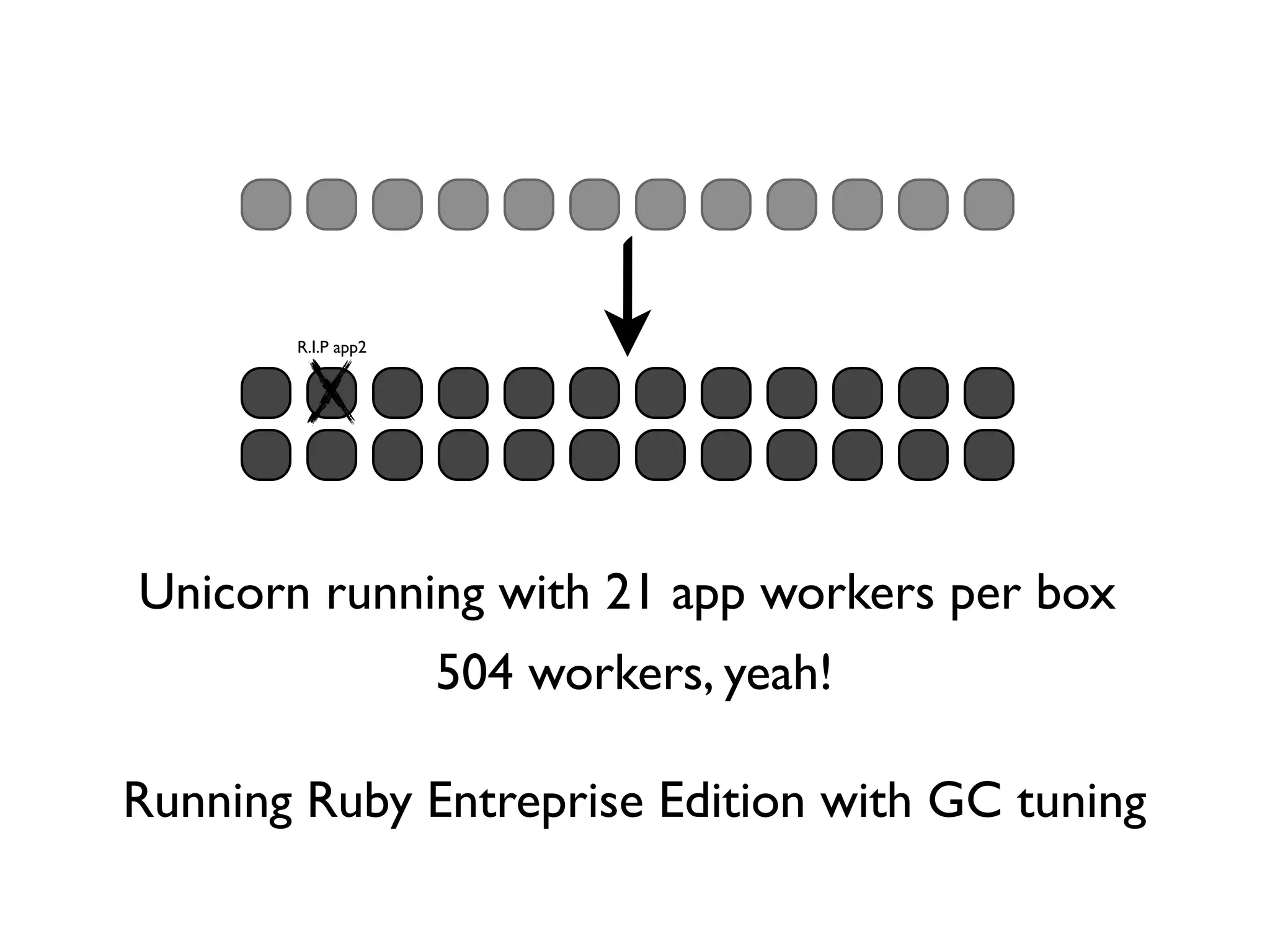
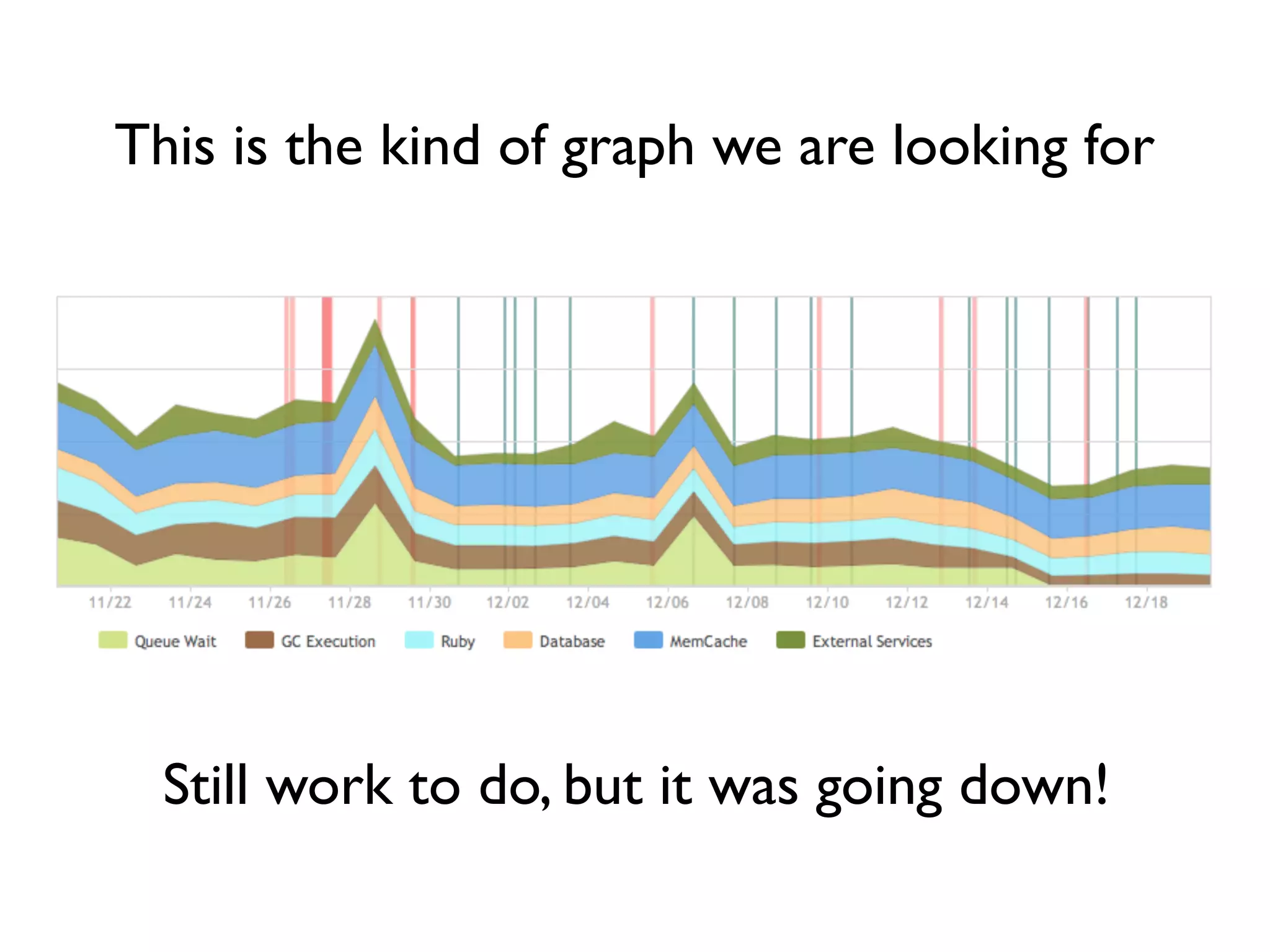
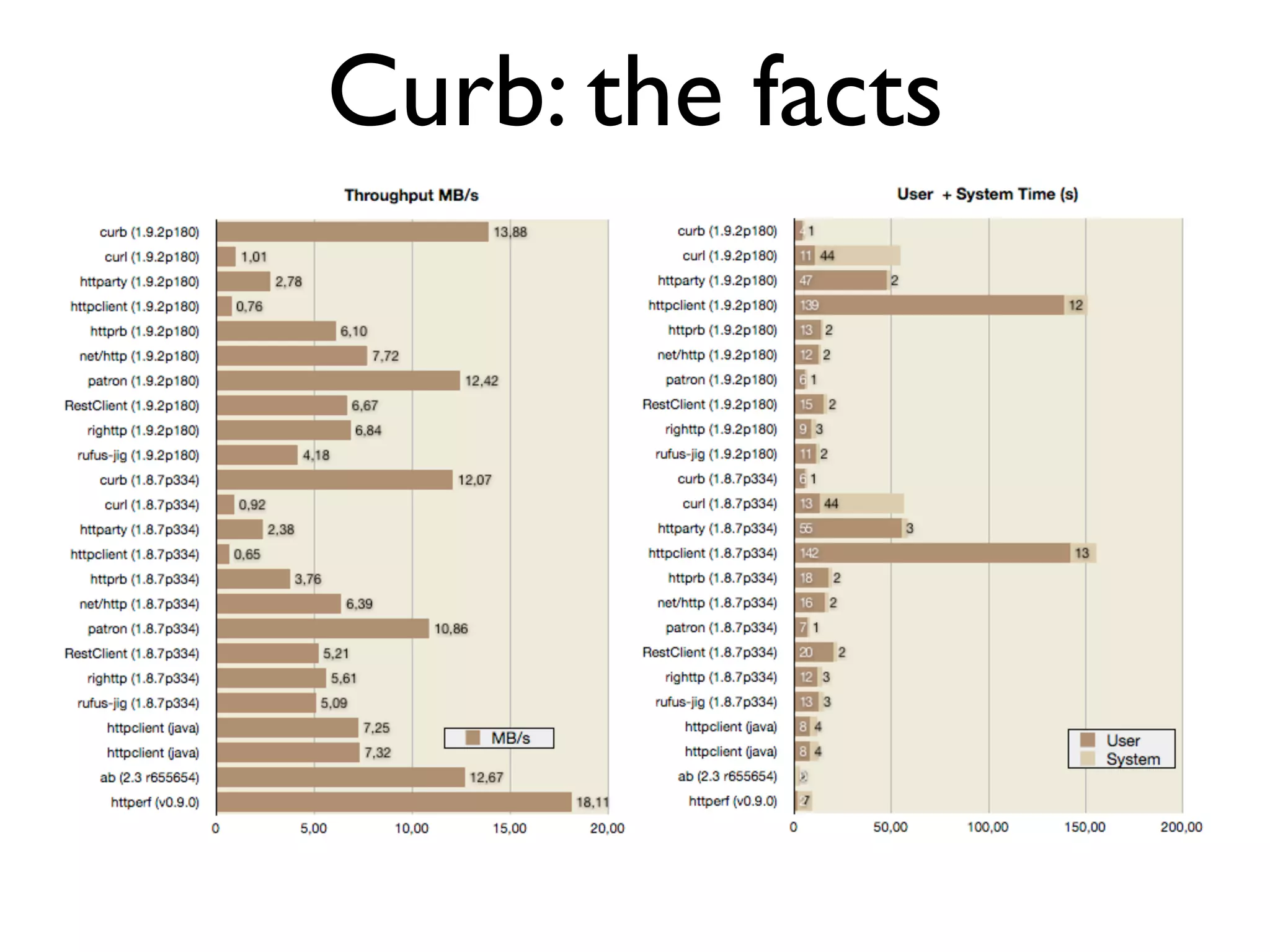
Guillaume Luccisano details strategies to enhance Rails stack performance at Justin.tv, revealing that Rails 3 is slower than Rails 2 and identifying key issues such as slow SQL queries, external dependencies, and garbage collection. Performance improvements were achieved through SQL optimization, the introduction of C libraries for faster processing, upgrades to Memcached, and better garbage collection tuning, ultimately reducing response times from 250ms to 80ms. The document also emphasizes the importance of monitoring tools and offers insights into further optimizations and strategies for ongoing performance improvements.














































![Clean up your before_filters
We created a speed_up! method
to skip all before_filters on critical actions
speed_up! :only => [‘critical’, ‘action’]](https://image.slidesharecdn.com/railsperformanceatjustintvguillaumeluccisano-110701014143-phpapp01/75/Rails-performance-at-Justin-tv-Guillaume-Luccisano-54-2048.jpg)























![[212] large scale backend service develpment](https://cdn.slidesharecdn.com/ss_thumbnails/221largescalebackendservicedevelpment-150915001346-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)








![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


