Cray XT Porting, Scaling, and Optimization Best Practices
Mit cilk
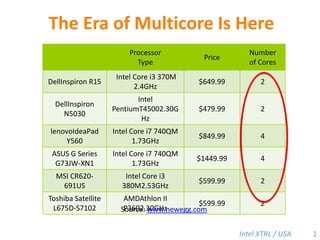
1. The Era of Multicore Is Here 1 Source: www.newegg.com
2. Memory Network … ¢ ¢ ¢ P P P Chip Multiprocessor (CMP) Multicore Architecture* 2 *The first non-embedded multicore microprocessor was the Power4 from IBM (2001).
3. Concurrency Platforms Aconcurrency platform,that provides linguistic support and handles load balancing, can ease the task of parallel programming. User Application Concurrency Platform Operating System 3
4. Using Memory Mapping to Support Cactus Stacks in Work-Stealing Runtime Systems Joint work with Silas Boyd-Wickizer, Zhiyi Huang, and Charles Leiserson I-Ting Angelina Lee Computer Science and Artificial Intelligence LaboratoryMassachusetts Institute of Technology March 22, Intel XTRL / USA
5. Using Memory Mapping to Support Cactus Stacks in Work-Stealing Runtime Systems Joint work with Silas Boyd-Wickizer, Zhiyi Huang, and Charles Leiserson I-Ting Angelina Lee Computer Science and Artificial Intelligence LaboratoryMassachusetts Institute of Technology March 22, Intel XTRL / USA
6. Three Desirable Criteria Interoperability with serial code, including binaries Serial-ParallelReciprocity GoodPerformance BoundedStack Space Reasonable space usage compared to serial execution Ample parallelism linear speedup 6
7. Various Strategies Cilk++ TBB Cilk Plus 7 The Cactus-Stack Problem: how to satisfy all three criteriasimultaneously.
19. The Cactus-Stack Problem Well … you didn’t say you want any performance guarantee, did you? ⌃ # SP Reciprocity Space Usage 19
20. The Cactus-Stack Problem Gee … I can get that just by running serially. ⌃ # SP Reciprocity Space Usage 20
21. The Cactus-Stack Problem Interoperability with serial code, including binaries Serial-ParallelReciprocity GoodPerformance BoundedStack Space Reasonable space usage compared to serial execution Ample parallelism linear speedup 21
22. Legacy Linear Stack An execution of a serial Algol-like language can be viewed as a serial walk of an invocation tree. C B A D E A A A A A A B C C C C B D E E D invocation tree views of stack 22
23. Legacy Linear Stack Rule for pointers: A parent can pass pointers to its stack variables down to its children, but not the other way around. C B A D E A A A A A A B C C C C B D E E D invocation tree views of stack 23
24. Legacy Linear Stack — 1960* Rule for pointers: A parent can pass pointers to its stack variables down to its children, but not the other way around. C B A D E A A A A A A B C C C C B D E E D invocation tree views of stack 24 * Stack-based space management for recursive subroutines developed with compilers for Algol 60.
25. Cactus Stack — 1968* A cactus stack supports multiple views in parallel. C B A D E A A A A A A B C C C C B D E E D invocation tree views of stack 25 * Cactus stacks were supported directly in hardware by the Burroughs B6500 / B7500 computers.
26. Heap-Based Cactus Stack A heap-based cactus stack allocates frames off the heap. A Mesa (1979), Ada (1979), Cedar (1986)MultiLisp (1985), Mul-T (1989), Id (1991), pH (1995), and more use this strategy. heap C B E D 26
40. Heap-Based Cactus Stack A heap-based cactus stack allocates frames off the heap. MIT Cilk-5 (1998) and Intel Cilk++ (2009)use this strategy as well. A heap Good time and space bounds can be obtained … C B E D 28
41. Heap-Based Cactus Stack Heap linkage: call/return via frames in the heap. A Heap linkage parallel functions fail to interoperate with legacy serial code. heap C B E D 29
42. Various Strategies 30 The main constraint: once allocated, a frame’s location in virtual address cannot change.
48. OS Support for TLMMSurvey of My Other Work Direction for Future Work 31
49. The Cilk Programming Model The named childfunction may execute in parallel with the continuation of its parent. intfib(intn) { if(n < 2) { return n; } intx = spawn fib(n-1); inty = fib(n-2); sync; return (x + y); } Control cannot pass this point until all spawned children have returned. Cilk keywords grant permissionfor parallel execution. They do not commandparallel execution. 32
50. Cilk-M A work-stealing runtime system based on Cilk that solves the cactus-stack problem by thread-local memory mapping (TLMM). 33
51. Cilk-M Overview High virtual addr stack TLMM Thread-local memory mapped (TLMM) region: A virtual-address range in which each thread can map physical memory independently. heap uninitialized data (bss) shared Idea: Allocate the stacks for each worker in the TLMM region. initialized data code Low virtual addr 34
52. Basic Cilk-M Idea 0x7f000 A A A Workers achieve sharing by mapping the same physical memory at the same virtual address. x: 42 x: 42 x: 42 B C C y: &x y: &x E D y: &x P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 35
56. Cilk Depth 37 A C B Cilk depth (3) is not the same as spawn depth (2). E D G F Cilk depth is the max number of Cilk functions nested on the stack during a serial execution
71. OS Support for TLMMSurvey of My Other Work Direction for Future Work 42
72. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn call spawn spawn spawn call spawn spawn call P P P P 43
73. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn call spawn spawn spawn call spawn call spawn call call! P P P P 44
74. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn call spawn spawn spawn call spawn call spawn call spawn spawn! P P P P 45
75. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn call spawn spawn spawn call spawn call spawn call spawn call spawn call! spawn! spawn! spawn P P P P 46
76. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn spawn call spawn call spawn spawn spawn call call spawn call spawn return! spawn P P P P 47
77. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn spawn call call spawn spawn spawn call call spawn call spawn steal! spawn P P P P When a worker runs out of work, itstealsfrom the top of a randomvictim’s deque. 48
78. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn spawn call call spawn spawn spawn call call spawn spawn call spawn spawn! spawn P P P P When a worker runs out of work, itstealsfrom the top of a randomvictim’s deque. 49
79. Cilk-M’s Work-Stealing Scheduler Each worker maintains awork dequeof frames, and it manipulates the bottom of the deque like a stack [MKH90, BL94, FLR98]. spawn spawn call call spawn spawn spawn call call spawn spawn call spawn spawn P P P P Theorem [BL94]: With sufficient parallelism, workers steal infrequently linear speedup. 50
85. OS Support for TLMMSurvey of My Other Work Direction for Future Work 51
86. TLMM-Based Cactus Stacks 0x7f000 A x: 42 B Use standard linear stack in virtual memory. y: &x P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 52
87. TLMM-Based Cactus Stacks 0x7f000 A A A x: 42 x: 42 x: 42 B Map (not copy) the stolen prefixto the same virtual addresses. y: &x steal A P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 53
88. TLMM-Based Cactus Stacks 0x7f000 A A x: 42 x: 42 B Subsequent spawns and calls grow down-ward in the thief’s TLMM region. C y: &x y: &x P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 54
89. TLMM-Based Cactus Stacks 0x7f000 A A x: 42 x: 42 B Both workers see the same virtual address value for &x. C y: &x y: &x P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 55
90. TLMM-Based Cactus Stacks 0x7f000 A A x: 42 x: 42 B C Both workers see the same virtual address value for &x. y: &x D y: &x P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 56
91. TLMM-Based Cactus Stacks 0x7f000 A A A A x: 42 x: 42 x: 42 x: 42 B C C C Map (not copy) the stolen prefixto the same virtual addresses. y: &x y: &x y: &x D y: &x steal C P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 57
92. TLMM-Based Cactus Stacks 0x7f000 A A A x: 42 x: 42 x: 42 B C C Subsequent spawns and calls grow down-ward in the thief’s TLMM region. y: &x y: &x D E y: &x z: &x P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 58
93. TLMM-Based Cactus Stacks 0x7f000 A A A x: 42 x: 42 x: 42 B C C All workers see the same virtual address value for &x. y: &x y: &x E D y: &x z: &x P3 P1 P2 A C B Unreasonable simplification: Assume that we can map with arbitrary granularity. E D 59
98. Handling Page Granularity 0x7f000 A A A A page size B 0x7e000 C C C D 0x7d000 A steal C C B P3 P1 P2 E D 64
99. Handling Page Granularity 0x7f000 A A A page size B 0x7e000 C C Advance the stack pointer again additional fragmentation. D 0x7d000 A steal C C B P3 P1 P2 E D 65
100. Handling Page Granularity 0x7f000 A A A page size B 0x7e000 C C Advance the stack pointer again additional fragmentation. D 0x7d000 E A C B P3 P1 P2 E D 66
101. Handling Page Granularity 0x7f000 A A A page size B 0x7e000 C C Space-reclaiming heuristic: reset the stack pointer upon successful sync. D 0x7d000 E A C B P3 P1 P2 E D 67
107. OS Support for TLMMSurvey of My Other Work Direction for Future Work 68
108. Space Bound with a Heap-Based Cactus Stack Theorem [BL94].Let S1 be the stack space required by a serial execution of a program. The stack space per worker of a P-worker execution using a heap-based cactus stack is at mostSP/P ≤ S1. Proof. The work-stealing algorithm maintains the busy-leaves property: Every active leaf frame has a worker executing on it.■ P = 4 S1 P P P P 69
109. Cilk-M Space Bound Claim.Let S1 be the stack space required by a serial execution of a program. Let D be the Cilk depth. The stack space per worker of a P-worker execution using a TLMM cactus stackis at mostSP/P ≤ S1+D. Proof. The work-stealing algorithm maintains the busy-leaves property: Every active leaf frame has a worker executing on it.■ P = 4 S1 P P P P 70
111. Performance Bound with aHeap-Based Cactus Stack Definition.TP— execution time on P processors T1— work T∞— spanT1 / T∞ — parallelism Theorem [BL94]. A work-stealing scheduler can achieve expected running time TP=T1 / P + O(T∞) on P processors. Corollary. If the computation exhibits sufficient parallelism(P ≪T1 / T∞ ), this bound guarantees near-perfect linear speedup (T1 / Tp ≈ P). 72
112. Cilk-M Performance Bound Definition.TP— execution time on P processors T1— work T∞— spanT1 / T∞ — parallelismD — Cilk depth Claim. A work-stealing scheduler can achieve expected running time Tp= T1 / P + CT∞ onP processors, where C = O(S1+D) . Corollary. If the computation exhibits sufficient parallelism(P ≪T1 / (S1+D)T∞), this bound guarantees near-perfect linear speedup (T1 / Tp ≈ P). 73
131. When a thread A attempts to acquire a mutual-exclusion lock L, it may be blocked if another thread B already owns L.
132. Rather than spin-waiting on L itself, A adds itself to a queue associated with L and spins on a local variable LA, thereby reducing coherence traffic.
133. When B releases L, it resets LA, which wakes A up for another attempt to acquire the lock.
134. If A allocates LA on its stack using TLMM, LA may not be visible to B!78
146. The JCilk Language Joint work with John Danaher and Charles Leiserson Parallel Constructs from Cilk: spawn & sync Java Core Functionalities 81
147. The JCilk Language Joint work with John Danaher and Charles Leiserson Exception Handling Parallel Constructs from Cilk: spawn & sync Java Core Functionalities 82
148.
149. JCilk’s exception semantics include an implicit abort mechanism, which allows speculative parallelism to be expressed succinctly in JCilk.
150. Other researchers [I91, TY00, BM00] pursued new linguistic mechanisms.Exception Handling in a Concurrent Context 83
151. The JCilk System JCilkRuntime System JCilk Compiler JCilk to Java + goto Jgo compiler: GCJ + goto support JVM source Fib.jcilk Fib.jgo Fib.class 84
152.
153. JCilk’s abort mechanism extends Java’s existing exception mechanism in a naturally way to propagate an abort, allowing the programmer to clean-up.What We Discovered 85
166. the owner thread vs. other threadsApplications exhibit asymmetric synchronization patterns. 89
167.
168. Some applications can benefit from a software implementation [DHY03] that uses interrupt.
169. A light-weight hardware mechanism can piggyback on the cache coherence protocol. Location-Based Memory Fences 90 Joint work with EdyaLadan-Mozes and DmitriyVyukov
173. Transactional Memory Rset: w,xWset: w,x Memory atomic {//A x++; } Rset: xWset:x A atomic {//B w = x; } Rset: xWset:w B Transactional Memory (TM) [HM93] provides a transactional interface for accessing memory. 92
174. Transactional Memory Rset: w,xWset: w,x Memory atomic {//A x++; } Rset: xWset:x A atomic {//B w = x; } Rset: xWset:w B TM guarantees that transactions are serializable[P79]. 93
175. Nested Transactions Rset: w,x,y,zWset: w,x,y,z atomic {//A int a = x;... atomic { //B w++; } intb = y; z = x + y; } Memory Rset: xWset: A Rset:wWset: w B Closed-nesting:propagate the changes to A. 94
176. Nested Transactions Rset: w,x,y,zWset: w,x,y,z atomic {//A int a = x;... atomic { //B w++; } intb = y; z = x + y; } Memory Rset: xWset: A Rset:wWset: w B Open-nesting:commit the changes globally. 95
177. Nested Transactions All memories are treated equally – there is only one level of abstraction. 96
178.
179. In OAT, the programmer writes code with transactional modules, and the OAT system uses the concept ofownership types [BLS03] to ensure data encapsulation within a module.
180. The OAT system guarantees abstract serializabilityas long as the program conforms to a set of well-defined constraints on how the modules share data. 97
184. Parallelism Abstraction Aconcurrency platform provides a layer of parallelism abstraction to help load balancing and task scheduling. User Application Concurrency Platform Operating System 99
185.
186. Hyperobject [FHLL09]: a linguistic mechanism that supports coordinated local views of the same nonlocal object.
187. Transactional Memory [HM93]: memory accesses dynamically enclosed by an atomic block appear to occur atomically.100 Can a concurrency platform as well mitigate the complexity of synchronization by providing the right memory abstractions?
197. Quadratic Stack Growth [Robison08] P : parallel P Assume one linear stack per worker : serial P S S : spawn P S : call P S Depth = d S . . . S . . . . . . P S S S . . . P P P Repeat dtimes . . . S S S S S S 105
198. Quadratic Stack Growth [Robison08] P The green worker repeatedly blocks, then steals, using Θ(d2)stack space. Assume one linear stack per worker P S P S P S Depth = d S . . . S . . . . . . P S S S . . . P P P Repeat dtimes . . . S S S S S S 106
199. Performance Comparison AMD 4 quad-core 2GHz Opteron, 64KB private L1, 512K private L2, 2MB shared L3 Cilk-M running time / Cilk-5 running time Time Bound:Tp= T1 / P + CT∞ , where C = O(S1+D) 107
202. GCC/Linux C Subroutine Linkage args to A The legacy linear stack obtains efficiency by overlapping frames. A’s return address A’s parent’s base ptr frame forA bp sp A’s local variables linkage region args to B B’s return address B’s local variables A’s base pointer frame forB A args to B’s callees C B E D 110
203. Handling Page Granularity 0x7f000 A A page size B 0x7e000 The thief advances its stack pointer past the next page boundary, reserving space for thelinkage regionfor the next callee. 0x7d000 A steal A C B P3 P1 P2 E D 111
204. Handling Page Granularity 0x7f000 A A page size B 0x7e000 The thief advances its stack pointer past the next page boundary, reserving space for thelinkage regionfor the next callee. C D 0x7d000 A C B P3 P1 P2 E D 112
205. Handling Page Granularity 0x7f000 A A A page size B 0x7e000 The thief advances its stack pointer past the next page boundary, reserving space for thelinkage regionfor the next callee. C C D 0x7d000 A steal C C B P3 P1 P2 E D 113
206. Handling Page Granularity 0x7f000 A A A page size B 0x7e000 The thief advances its stack pointer past the next page boundary, reserving space for thelinkage regionfor the next callee. C C D 0x7d000 E A C B P3 P1 P2 E D 114
207. Key Invocation Invariants Arguments are passed via stack pointer with positive offset. Local variables are referenced via base pointer with negative offset. Live registers are flushed onto the stack immediately before each spawn. Live registers are flushed onto the stack before returning back to runtime if sync fails. When resuming a stolen function after a spawn or sync, live registers are restored from the stack. When returning from a spawn, the return value is flushed from its register onto the stack. The frame size is fixed before any spawn statements. 115
208. GCC/Linux C Subroutine Linkage Legacy linear stacks enable efficient passing of arguments from caller to callee. args to A A’s return address A’s parent’s base ptr frame forA sp bp A’s local variables args to A’s callees A C B E D 116
209. GCC/Linux C Subroutine Linkage linkage region FrameAaccesses its arguments through positive offset indexed from its base pointer. args to A A’s return address A’s parent’s base ptr frame forA sp bp A’s local variables args to A’s callees A C B E D 117
210. GCC/Linux C Subroutine Linkage args to A A’s return address A’s parent’s base ptr frame forA sp bp A’s local variables FrameAaccesses its local variables through negative offset indexed from its base pointer. args to A’s callees A C B E D 118
211. GCC/Linux C Subroutine Linkage Before invoking B, A places the arguments for Binto the reserved linkage region it will share with B, which A indexes using positive offset off its stack pointer. args to A A’s return address A’s parent’s base ptr frame forA sp bp A’s local variables linkage region args to B args to A’s callees A C B E D 119
212. GCC/Linux C Subroutine Linkage args to A Athen makes the call to B, which saves the return address for Band transfers control to B. A’s return address A’s parent’s base ptr frame forA sp bp A’s local variables args to B B’s return address A C B E D 120
213. GCC/Linux C Subroutine Linkage args to A Upon entering, Bsaves A’s base pointer and sets the base pointer to where the stack pointer is. A’s return address A’s parent’s base ptr frame forA bp sp A’s local variables args to B B’s return address bp A’s base pointer A C B E D 121
214. GCC/Linux C Subroutine Linkage args to A B advances the stack pointer to allocate space for local variables and linkage region. A’s return address A’s parent’s base ptr frame forA bp sp A’s local variables args to B B’s return address B’s local variables A’s base pointer frame forB A args to B’s callees C B E D 122
215. GCC/Linux C Subroutine Linkage args to A The legacy linear stack obtains efficiency by overlapping frames. A’s return address A’s parent’s base ptr frame forA bp sp A’s local variables args to B B’s return address B’s local variables A’s base pointer frame forB A args to B’s callees C B E D 123
216. Legacy Linear Stack High Addr An execution of a serial Algol-like language can be viewed as a serial walk of an invocation tree. A A B C C B D E E D Low Addr invocation tree 124
217. Legacy Linear Stack High Addr Rule for pointers: A parent can pass pointers to its stack variables down to its children, but a child cannot pass a pointer to its stack variable up to its parent. … A A C C B x: 42 E E D Low Addr invocation tree y: &x 125
218. Legacy Linear Stack High Addr Rule for pointers: A parent can pass pointers to its stack variables down to its children, but a child cannot pass a pointer to its stack variable up to its parent. A A C C B ✗ y: &z E E D Low Addr invocation tree z: 42 126
219. The Queens Problem Given n> 0, search for oneway to arrange n queens on an n-by-n chessboard so that none attacks another. legal configuration illegal configuration 127
220. Exploring the Search Tree for Queens start r0,c1 r0,c2 r0,c3 r0,c0 r1,c3 r1,c3 r1,c2 r1,c1 r1,c0 r1,c3 r1,c2 r1,c1 r1,c0 r1,c3 r1,c2 r1,c1 r1,c0 r1,c2 r1,c1 r1,c0 r2,c0 r2,c0 r2,c0 r2,c0 . . . . . . Serial strategy: Depth-first search with backtracking. The search tree size grows exponentially as n increases. 128
221. Exploring the Search Tree for Queens start r0,c1 r0,c2 r0,c3 r0,c0 r1,c3 r1,c3 r1,c2 r1,c1 r1,c0 r1,c3 r1,c2 r1,c1 r1,c0 r1,c3 r1,c2 r1,c1 r1,c0 r1,c2 r1,c1 r1,c0 r2,c0 r2,c0 r2,c0 r2,c0 . . . . . . Parallel strategy: spawn searches in parallel. Speculative computation – some work may be wasted. 129
222. Exploring the Search Tree for Queens start r0,c1 r0,c2 r0,c3 r0,c0 r1,c3 r1,c3 r1,c2 r1,c1 r1,c0 r1,c3 r1,c2 r1,c1 r1,c0 r1,c3 r1,c2 r1,c1 r1,c0 r1,c2 r1,c1 r1,c0 r2,c0 r2,c0 r2,c0 r2,c0 . . . . . . Parallel strategy: spawn searches in parallel. Abort other parallel searches once a solution is found. 130
224. 132 Parallelize Your Code using Cilk++ class SAT_Solver { public: int solve( … ); … private: … }; Convert the entire code base to Cilk++ language. 2. Structure the project so that Cilk++ code calls C++ code, but not conversely. Allow C++ functions to call Cilk++ functions, but convert entire subtree to use Cilk++. a. Use C++ wrapper functionsb. Use “extern C++” c. Limited call back to C++ code
225. 133 Parallelize Your Code using TBB class SAT_Solver { public: int solve( … ); … private: … }; Convert the entire project to Cilk++ language. 2. Structure the project so that Cilk++ code calls C++ code, but not conversely. Allow C++ functions to call Cilk++ functions, but convert entire subtree to use Cilk++. a. Use C++ wrapper functionsb. Use “extern C++” c. Limited call back to C++ code Your program may end up using a lot more stack space or fail to get good speedup.
226. Memory Network … ¢ ¢ ¢ P P P Chip Multiprocessor (CMP) Multicore Architecture — 2001* 134 *The first non-embedded multicore microprocessor was the Power4 from IBM (2001).
227. The Era of Multicore IS Here 135 # of CPUS # of Cores Source: www.newegg.com Single core processor is becoming obsolete.
228. My Sister Is Buying a New Laptop … 136 Source: www.apple.com The era of multicore IS here!
Editor's Notes
A concurrency platform is asoftware abstraction layer that manages the processors' resources, schedulesthe computation over the available processors, and provides an interfacefor the programmer to specify parallel computations.
It turns out that, there seems to be a fundamental tradeoff between the three criteria.We and other practitioners have considered various strategies, and all of them fail to satisfy one of the three criteria, except for the TLMM cactus stacks, which is the strategy we employed in this work.
I am sure everyone know what a linear stack is.An execution of a serial language can be viewed as a serial walk of an invocation tree.On the left, we have an invocation tree, where A calls B and C, and C calls D and E.On the right is the corresponding views of stack for each function when it is active.throughout the rest of the talk, I will use the convention that the stack grows downwardNote that, when a function is active, it can always see its ancestors’ frames in the stack
But parallel functions fail to interoperate with legacy serial code, because a legacy serial could would allocate its frame off the linear stack, and it does not understand the heap linkage, where the call / return is performed via frames in the heap.
It turns out that, there seems to be a fundamental tradeoff between the three criteria.We and other practitioners have considered various strategies, and all of them fail to satisfy one of the three criteria, except for the TLMM cactus stacks, which is the strategy we employed in this work.We don’t have time to go into all the strategy but I will go into a little more details on one strategy to illustrate the challenge in satisfying all three criteria.You are welcome to ask me about the other strategies after the talk, if you are interested.
The Cilk work-stealing scheduler then executes the prog in the way that respects the logical parallelism specified by the programmer while guaranteeing that programs take full advantage of the processors available at runtime.
Thread-local memory mapped (TLMM) region: A virtual-address range in which each thread can map physical memory independently.One main constraint that we are operating under, is that once a frame has been allocated, its location in virtual memory cannot be changed,We can get around this, if every thread has its own local view of virtual address range
Because the stacks are allocated in TLMM region, we can map the region such that part of the stack is shared. For example, worker one has the stack view of ..A frame for a given function refers to the same physical memory in all stacks and is mapped to the same virtual address.
Time bound guarantee linear speed up if there is sufficient parallelismSpace bound: each worker does not use more than S1
Note that this is running on 16 cores
across all app, each worker uses no more than 2 times more compared to the serial stack usage
Use a standard linear stack in virtual memory
Upon a steal, map the physical memory corresponding to the stolen prefixto the same virtual addresses in the thief as in the victim
Subsequent spawns and calls grow down-ward in the thief’s independently mapped TLMM region.
Both the victim and the thief see the same virtual address value for the reference to A’s local variable x
Subsequent spawns and calls grow down-ward in the thief’s independently mapped TLMM region.
ORALLY: P3 Steal C … techinucally it first stole A and fail to make progress on it, then it steals C
Subsequent spawns and calls grow down-ward in the thief’s independently mapped TLMM region.
Of course, our assumption is not so reasonable --- we can’t really map at arbitrary granularity. Instead, we have to map at page granularity.
Advancing the stack pointer avoids overwriting other frames on the page, at the cost of fragmentation.
The thief then resumes the stolen frame and executes normally in its own TLMM region.
Once again, the stack pointer must be advanced, which causes additional fragmentation.
only the worker who executes it would perform the mmap ... need to synchronize among all workers to perform the mmap as well.
multiple threads’ local overlaps w/ diff pages.
Each thread uses a unique root page directory …When a thread maps in the shared region … need to synchronize, but the synchronization is done only once per shared entry in the root page directory
Tazuneki and Yoshida \\cite{TazunekiYo00} and Issarny \\cite{Issarny91}have investigated the semantics of concurrent exception-handling,taking different approaches from our work. In particular, theseresearchers pursue new linguistic mechanisms for concurrentexceptions, rather than extending them faithfully from a serial baselanguage as does \\jcilk. The treatment of multiple exceptions thrownsimultaneously is another point of divergence.
The JCilk system consists of two components: the runtime system and the compiler.
Critically there is a duality between the actions of the threadsModern processors typically employ TSO(Total-Store-Order) and PO(Processor-Ordering) That is, Reads are not reordered with other readsWriter are not reordered with older readsWrites are not reordered with other writes; andReads may be reordered with older writes if they have different target location
Traditional memory barriers are PC-based – the processor inevitably stalls upon execution
The lock word associated with a monitor can be biased towards one thread.The bias-holding thread can update the lock word using regular ld-update-store.A unbiased lock word must be updated using CAS.Dekker is used to synchronize between the bias-holding thread and revoker thread when revoker attempts to update the bias.network package processing applications --- each thread handles a group of source addresses and maintain its own data structureOccasionally, a processing thread needs to update another thread’s data structure If collection is in-progress the barrier halts the thread until the collection completes. The prevents the thread from mutating the heap concurrently with the collector. The JNI reentry barrier is commonly implemented with a CAS or a Dekker-like "ST;MEMBAR;LD" sequence to mark the thread as a mutator (the ST) and check for a collection in-progress (the LD)JNI occur frequently but collections are relatively infrequent.
The TM system enforces atomicity by tracking the memory locations that each transaction accesses, detecting conflicts, and possibly aborting and retrying transactions.
TM guarantees that transactions are serializable [Papadimitriou79]. That is, transactions affect globalmemory as if they were executed one at a time in some order, even ifin reality, several executed concurrently.
A decade ago, much multithreaded software was still written with POSIX orJava threads, where the programmer handled the task decomposition andscheduling explicitly. By providing a parallelism abstraction, aconcurrency platform frees the programmer from worrying about loadbalancing and task scheduling.
TLMM cactus stack: each worker gets its own linear local view of the tree-structured call stack.hyperobject [FHLL09]: a linguistic mechanism that supports coordinated local views of the same nonlocal object.transactional memory [HM93]: memory accesses dynamically enclosed by an atomic block appear to occur atomically.I believe, a concurrency platform can as well mitigate the complexity of synchronization by providing the appropriate memory abstractions.A memory abstraction isan abstraction layer between the program execution and the memory thatprovides a different ``view'' of a memory location depending on theexecution context in which the memory access is made.What other memory abstraction can we do?
Assume we use one linear stack per worker. Here, we are using the term worker interchangeably with the term persistant thread – think of Java thread or POSIX thread.This is a beautiful observation made by Arch Robison, who is the main architect of Intel TBB, which is another concurrency platform.The observation is that, using the strategy of one linear stack per worker, some computation may incur quadratic stack growth compared to its serial execution.An example of such computation is as follows. Here, I am showing you an invocation tree. The frame marked as P is a parallel function, which may have multiple extant children executing in parallel. The frame marked as S is a serial function. I haven’t told you the details of how a work-stealing scheduler operates, but for the purpose of this example, all you need to know is that the execution of the computation typically goes depth-first and left to right. Once a P function spawns the left branch (marked as red), however, the right branch now becomes available for execution. In order to guarantee the good time bound, one must allow a worker thread to randomly choose a readily available function to execute.
Then we can run into the following scenario: I am using different colors to denote the worker who invoked a given function.One main constraint that we are ope rating under, is that once a frame has been allocated, its location in virtual memory cannot be changed,So the green worker cannot pop off the stack-allocated frames, because the purple worker may have pointers to variables allocated on those frames
Note that this is running on 16 cores
This worst case occurs when every Cilk function on a stack that realizes the Cilk depth D is stolen.
Show space consumption, mention couple tricks we did to recycle stack space
The compact linear-stack representation ispossible only because in a serial language, a function has at most oneextant child function at any time.
Of course, our assumption is not so reasonable --- we can’t really map at arbitrary granularity. Instead, we have to map at page granularity.
Of course, our assumption is not so reasonable --- we can’t really map at arbitrary granularity. Instead, we have to map at page granularity.
Of course, our assumption is not so reasonable --- we can’t really map at arbitrary granularity. Instead, we have to map at page granularity.
Of course, our assumption is not so reasonable --- we can’t really map at arbitrary granularity. Instead, we have to map at page granularity.
static for P1 and P2.mention fragmentation part of stack no visibleissue of fragmentationwant to use backward compatible linkagecombine this page and the next page. Insert the linkage block in there.animate just P3
mention memory args only when regs are not enoughoverlapping of the frames
mention memory args only when regs are not enoughoverlapping of the framesSAY: can access via stack pointer if the frame size is known statically
mention memory args only when regs are not enoughoverlapping of the frames
mention memory args only when regs are not enoughoverlapping of the frames
CORRECT this text A then transfer control to B
The compact linear-stack representation ispossible only because in a serial language, a function has at most oneextant child function at any time.
On the left, I am showing you an invocation tree … Suchserial languages admit simple array-based stack for allocating functionactivation frames. To allocate an activation frame when a function iscalled, the stack pointer is advanced, and when the function returns, theoriginal stack pointer is restored. This style of execution is spaceefficient, because all the children of a given function can use and reusethe same region of the stack.
x: 42 on Apass &x, stored as y in C & E.make widerThe other way around … should be symmetricIn A, have x:42, pass that down to C.
static threading / OpenMP / Streaming / fork-join parallel programming / message passing / GPU , which is not commonly used for multicore architecture with shared memoryis a software abstraction layer that manages the processors' resources, schedulesthe computation over the available processors, and provides an interfacefor the programmer to specify parallel computations.