













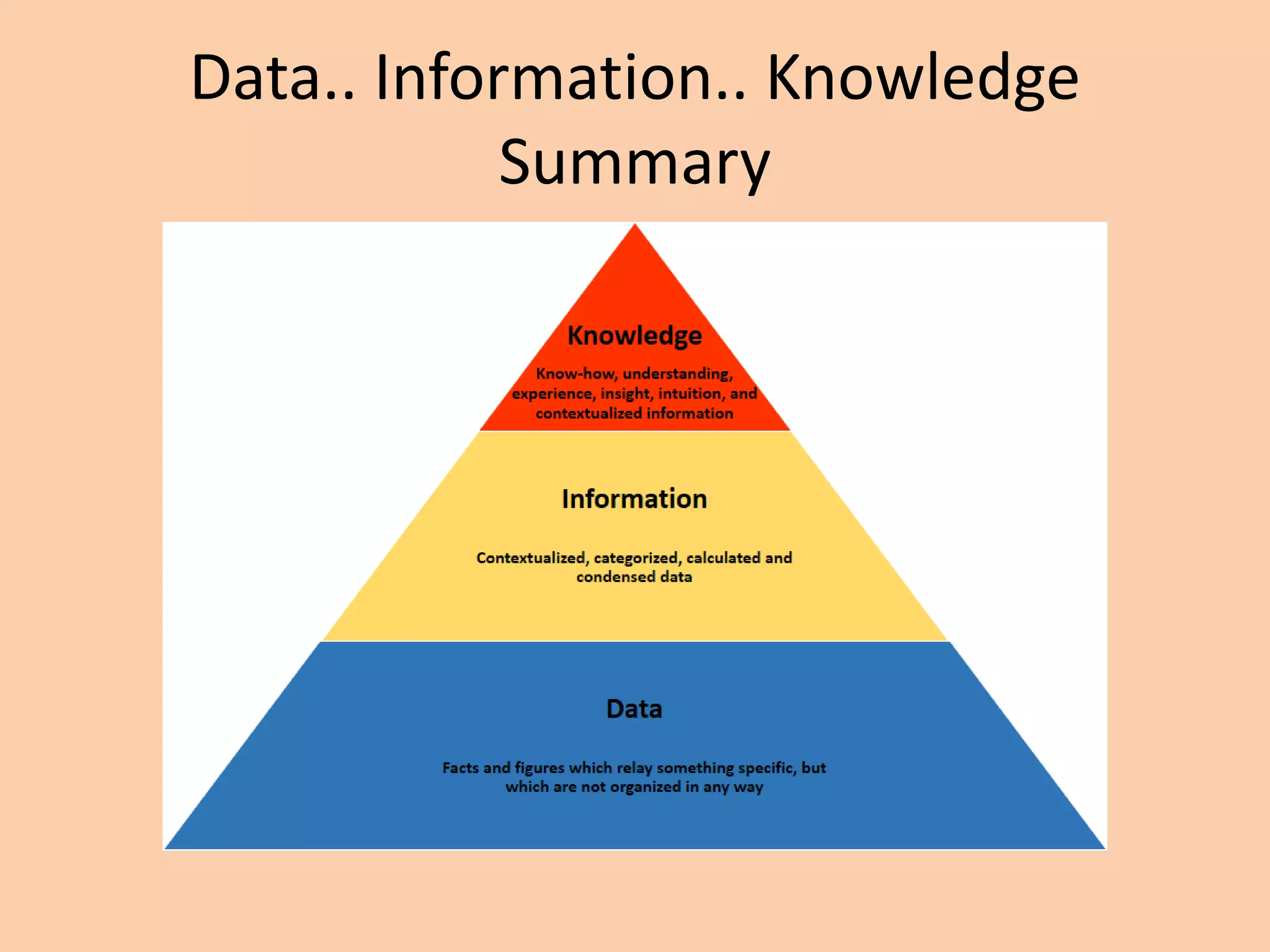



The document explains the concepts of data, information, and knowledge, highlighting how data is the raw facts and figures that require structure to become useful information, which is then transformed into knowledge through understanding and experience. It differentiates between various types of data such as qualitative, quantitative, categorical, discrete, and continuous, and emphasizes the importance of structured data for machine processing. Additionally, it provides definitions and relationships between data, information, and knowledge, underscoring their significance in various contexts.



































































