1. ESCUELA SUPERIOR POLITECNICA DE CHIMBORAZO
FACULTAD DE INFORMATICA Y ELECTRONICA
ESCUELA DE ELECTRONICA EN CONTROL
NOMBRE: Jorge Luis AldazToala
MINIMANUAL DE R-commander CON PRUEBA DE HIPOTISIS
R es un software para el análisis estadístico de datos considerado como uno de los más
interesantes. Apoyan esta opinión la vasta variedad de métodos estadísticos que cubre, las
capacidades gráficas que ofrece y, también muy importante, el hecho de ser un software libre,
es decir, gratuito.
El mayor inconveniente que podría presentar frente al software más utilizado en nuestro
medio es el hecho de funcionar mediante comandos, lo que para algunos usuarios puede
resultar engorroso. Para solventar esta dificultad existe un paquete llamado R
Commander que permite utilizar R sin tener que escribir los comandos, es decir, con la sola
utilización del ratón.
EL ENTORNO R-COMMANDER
R-Commander es una Interfaz Gráfica de Usuario (GUI en inglés), creada por John Fox, que
permite acceder a muchas capacidades del entorno estadístico R sin que el usuario tenga que
conocer el lenguaje de comandos propio de este entorno. Al arrancar R-Commander, se nos
presentan dos ventanas.
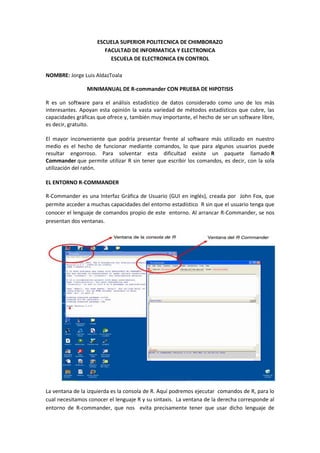
La ventana de la izquierda es la consola de R. Aquí podremos ejecutar comandos de R, para lo
cual necesitamos conocer el lenguaje R y su sintaxis. La ventana de la derecha corresponde al
entorno de R-commander, que nos evita precisamente tener que usar dicho lenguaje de
2. comandos, al menos para las tareas que se encuentran implementadas dentro de dicho
entorno.
No obstante, R-Commander no pretende ocultar el lenguaje R. Si observamos de cerca la
ventana de R-Commander, vemos que se divide en tres subventanas: script, output y
messages. Cada vez que, a través de los menús de R-commander accedamos a las capacidades
de R (gráficos, procedimientos estadísticos, modelos, etc.), en la ventana script se mostrará el
comando R que ejecuta la tarea que hayamos solicitado, y en la ventana output se mostrará el
resultado de dicho comando. De este modo, aunque el usuario no conozca el lenguaje de
comandos de R, simplemente observando lo que va apareciendo en la ventana script se irá
familiarizando.
El acceso a las funciones implementadas en R-commander es muy simple y se realiza
utilizando el ratón para seleccionar, dentro del menú situado en la primera línea de la
ventana, la opción a la que queramos acceder. Las opciones son:
− File: para abrir ficheros con instrucciones a ejecutar, o para guardar datos, resultados,
sintaxis, etc.
− Edit: las típicas opciones para cortar, pegar, borrar, etc.
− Data: Utilidades para la gestión de datos (creación de datos, importación desde otros
programas, recodificación de variables, etc.)
− Statistics: ejecución de procedimientos propiamente estadísticos
− Graphs: gráficos
− Models: definición y uso de modelos específicos para el análisis de datos.
− Distribution: probabilidades, cuantiles y gráficos de las distribuciones de probabilidad más
habituales (Normal, t de Student, F de Fisher, binomial, etc.)
3. − Tools: carga de librerías y definición del entorno.
− Help: ayuda sobre R-commander (en inglés).
PRUEBAS DE HIPÓTESIS
Otra manera de hacer inferencia es haciendo una afirmación acerca del valor que el parámetro
de la población bajo estudio puede tomar. Esta afirmación puede estar basada en alguna
creencia o experiencia pasada que será contrastada con la evidencia que nosotros obtengamos
a través de la información contenida en la muestra. Esto es a lo que llamamos Prueba de
Hipótesis
INTERVALOS DE CONFIANZA Y CONTRASTE DE HIPÓTESIS
INTERVALOS DE CONFIANZA
Para poder realizar el cálculo de los intervalos de confianza, así como de los contrastes de
hipótesis referentes a las distribuciones de probabilidad para representar el comportamiento
estadístico de poblaciones, se supone que la muestra de datos recogida es representativa del
comportamiento de la población, y una de las formas más usuales de garantizar esa
representatividad es mediante muestras aleatorias simples.
Consideremos el siguiente enunciado:
Un ingeniero industrial ha diseñado una máquina que envasa bolsas de cebollas de dos kilos.
Sin embargo, debido a diversas razones, como los diferentes pesos de las cebollas, problemas
en el llenado, etc. es consciente de que el peso final de la bolsa de cebollas no será
exactamente de dos kilos, sino que se producirán variaciones aleatorias con respecto a esta
cantidad. Para comprobar si la máquina está bien calibrada, toma una muestra de 45 bolsas
llenas de cebollas y contabiliza su peso. Con esta información, ¾tiene razones el ingeniero para
pensar que la máquina está mal calibrada? (Utilícese un nivel de significación del 5 %).
4. Fijémonos que nos piden claramente que confirmemos una afirmación: la máquina está mal
calibrada.
Eso obliga a plasmar dicha afirmación en la hipótesis alternativa, que es la única a la que
podemos asignar la carga del nivel de confianza. Por lo tanto, si notamos µ al peso medio de
las bolsas, tenemos que queremos contrastar H0 : µ = 2 frente a H1 : µ = 2 6 .
Dado que el tamaño muestral es generoso (45, superior a 30), no necesitamos la hipótesis de
normalidad de los datos. Dicho esto, vemos que se trata de un contraste sobre la media de una
distribución normal, contraste bilateral.
RESOLUCIÓN DEL PROBLEMA MEDIANTE R COMMANDER
Debemos importar los datos desde el chero cebollas.txt para manejar la variable en cuestión.
A continuación elegimos la opción del menú
ESTADÍSTICOS → MEDIAS → TEST T PARA UNA MUESTRA.
Esta opción abrirá la ventana que aparece en la figura anterior ,fijémonos con detalle en ella:
Nos pide en primer lugar que elijamos una (sólo una) variable, que debe ser aquella cuya
media estemos analizando.
Nos pide que indiquemos cuál es la hipótesis alternativa. En nuestro caso hemos elegido la
opción de un test bilateral.
Nos pide que especifiquemos el valor del valor hipotético con el que estamos comparando la
media, en nuestro caso, 2.
Nos pide, por último, que especifiquemos un nivel de confianza. En realidad este nivel de
confianza no lo es para el contraste, que se resolverá a través del p-valor, sino para el intervalo
de confianza asociado al problema. El enunciado no dice nada, por lo que ponemos la opción
habitual del 95 %.
One Sample t-test
data: Datos$Datos
t = -1.8415, df = 44, p-value = 0.0723
alternative hypothesis: true mean is not equal to 2
95 percent confidence interval:
1.994974 2.000227
sample estimates:
mean of x
1.9976