Downloaded 939 times










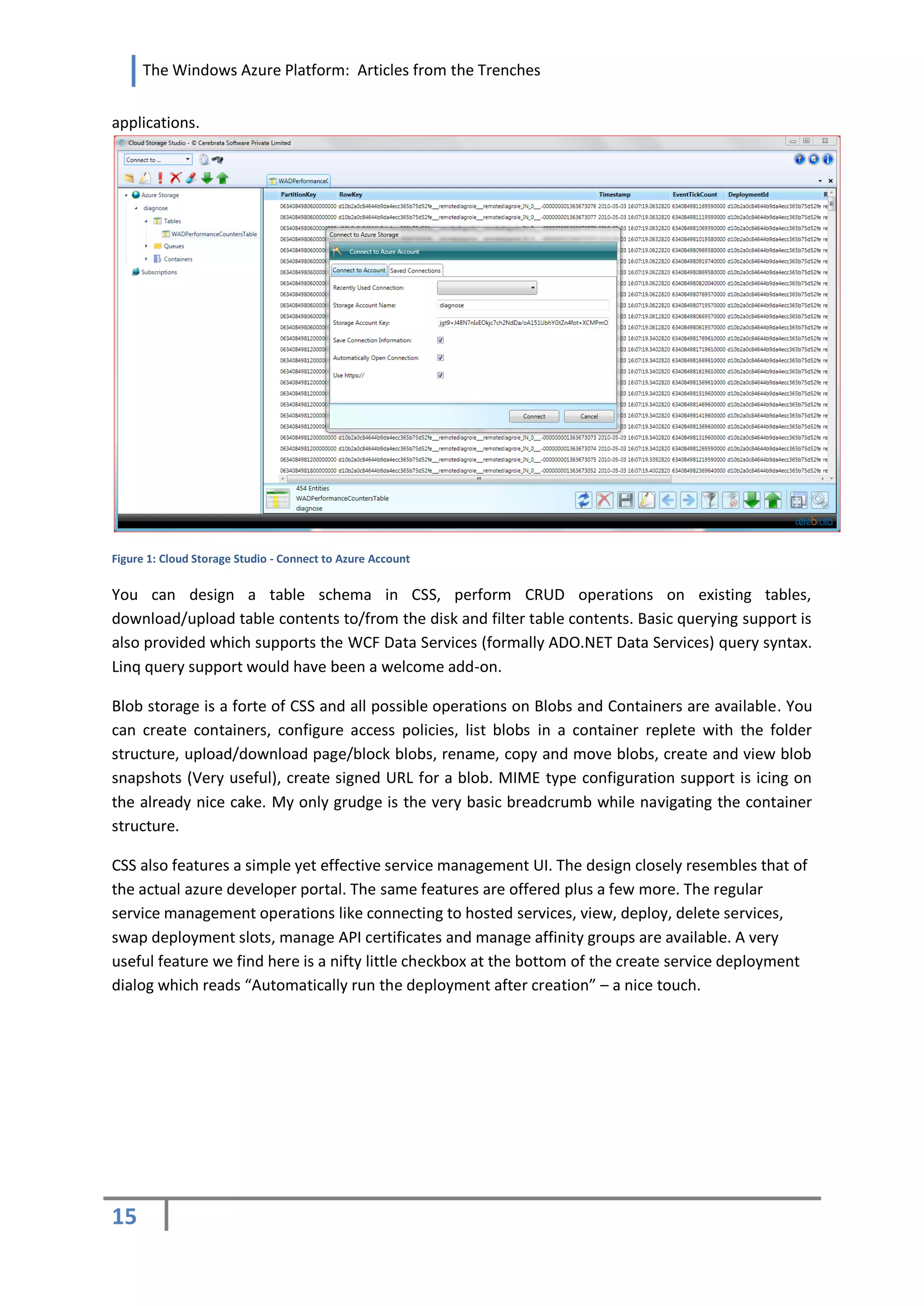
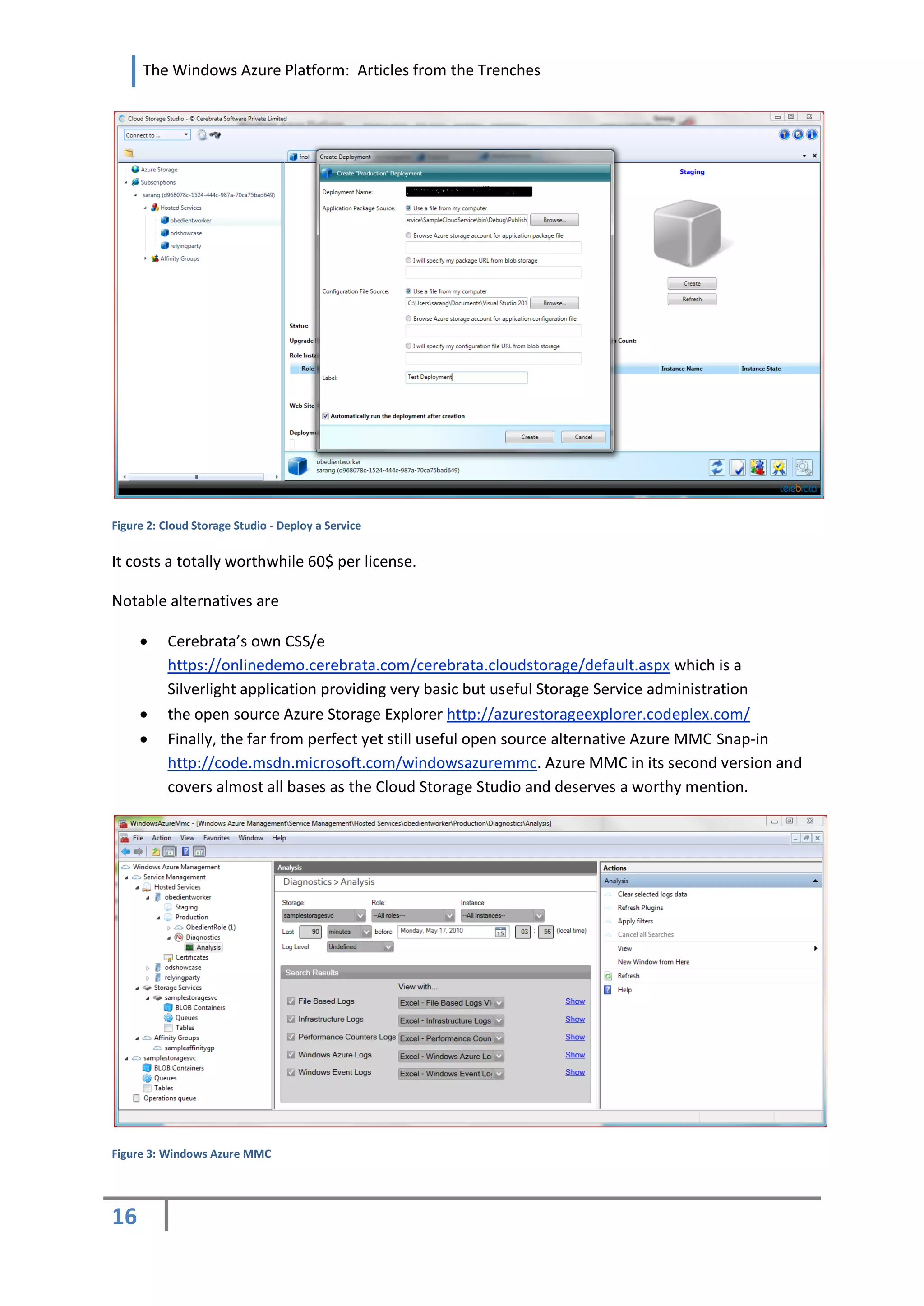

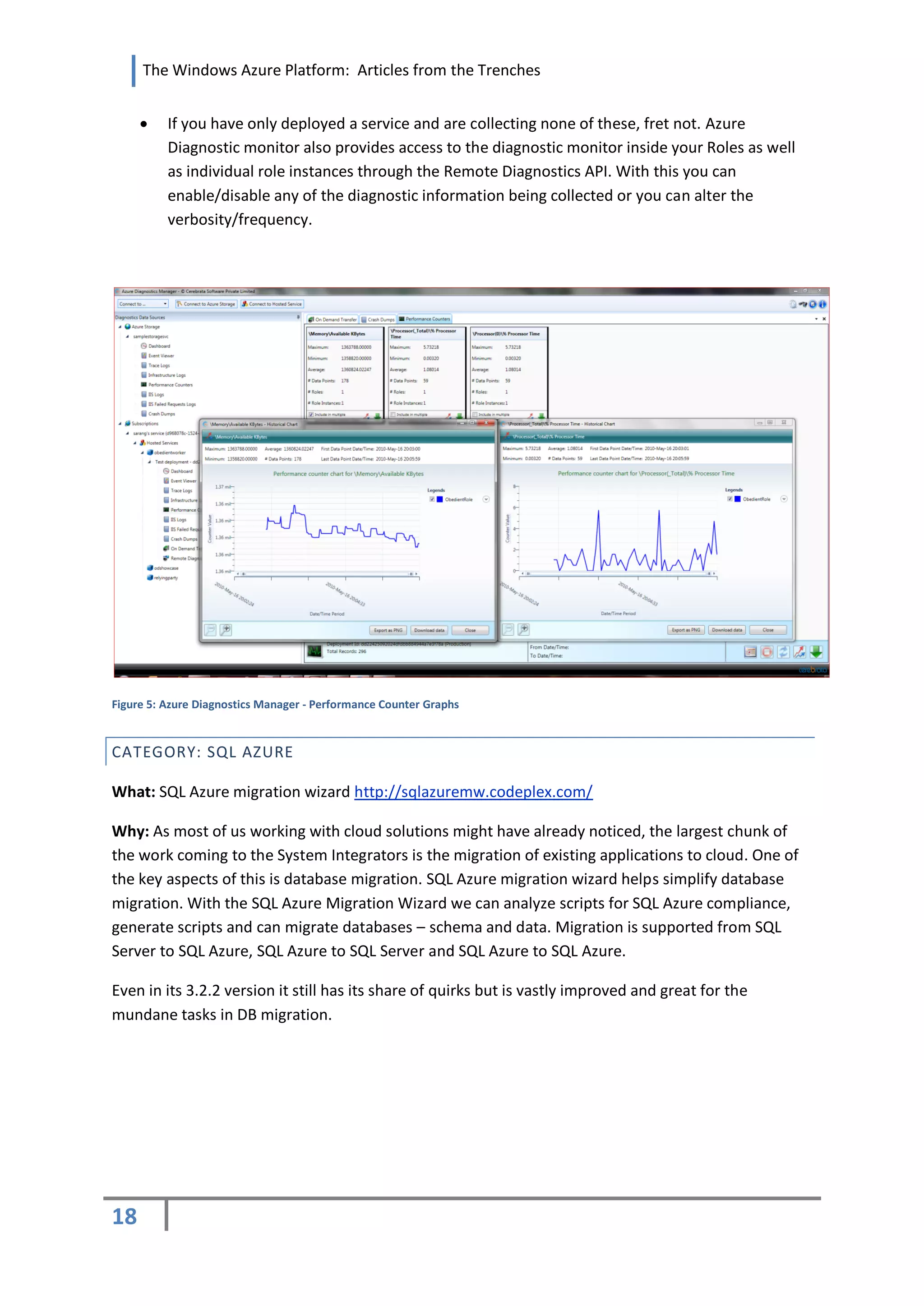
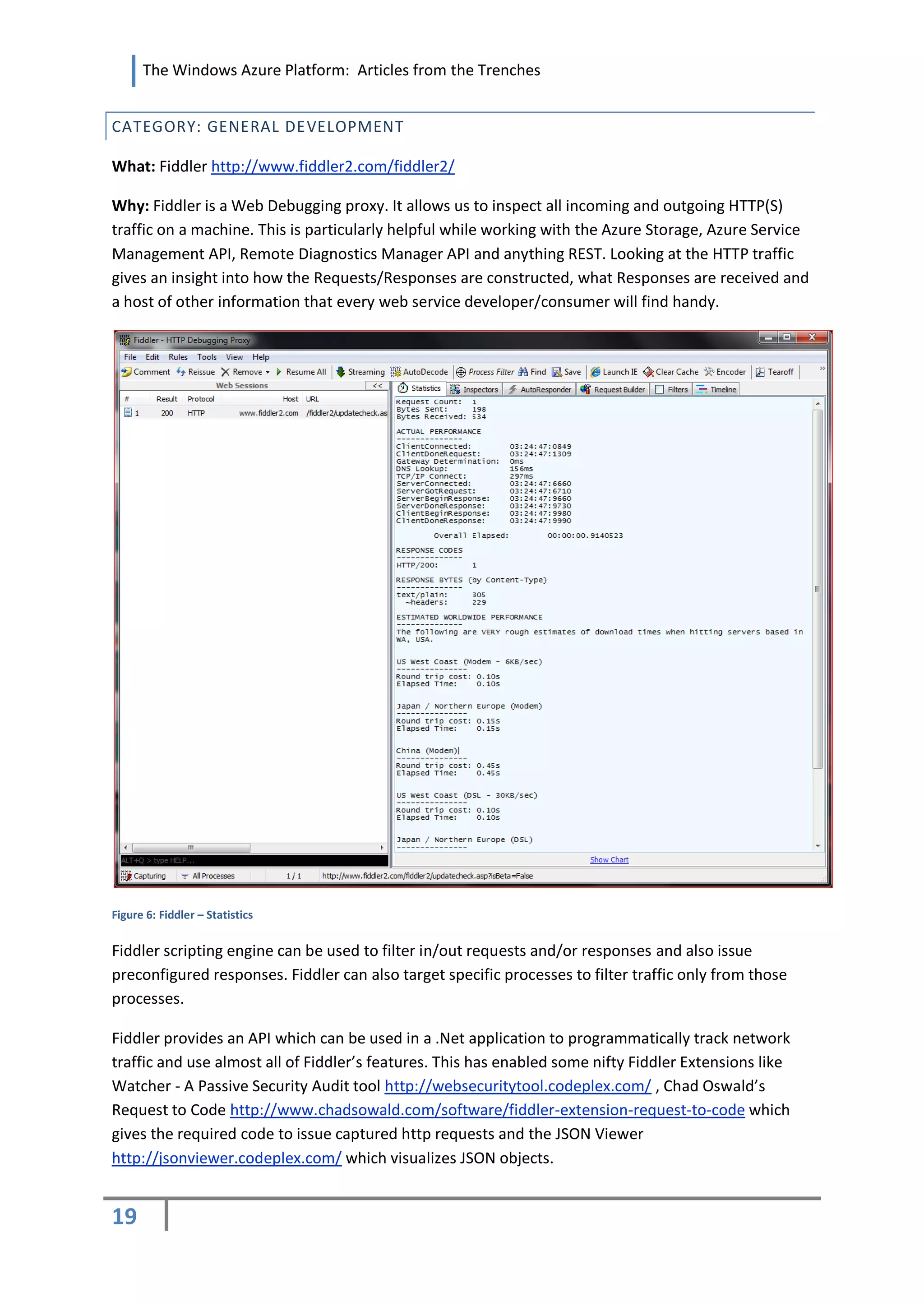















![The Windows Azure Platform: Articles from the Trenches
The Windows Azure Storage Explore running in Eclipse.
RUNNING JAVA CODE ON WINDOWS AZURE
If you want to host a Java application in Windows Azure, there are a number of considerations.
The first thing to note is that even if your Java application is a Web application you probably won’t
want to use an Azure Web Role. The principle difference between web roles and worker roles is
whether Internet Information Services (IIS) is included. Most Java developers will want to use a Java
specific web server or framework, so it’s usually best to go with a worker role and include your
choice of web server within your deployment package.
You’ll also need to bootstrap Java from a small .NET program that will essentially invoke the Java
runtime through a Process.Start call.
Both web roles and worker roles are provisioned behind a load-balancer so either is suitable for
hosting web applications. In a worker role you just have to do some additional plumbing to connect
up your web server to the appropriate load-balanced Input End Point. So for example, the public
facing port 80 of yourapp.cloudapp.net might get mapped to, say port 5100 in your worker role.
The following code allows you to determine this port at runtime:
RoleEnvironment.CurrentRoleInstance.InstanceEndpoints["Http"].IPEndpoint.Po
rt
36](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-36-2048.jpg)







![The Windows Azure Platform: Articles from the Trenches
BUILDING A CONTENT-BASED ROUTER SERVICE ON WINDOWS AZURE
By Josh Tucholski
Some applications, depending on their nature, require priority processing based on request content.
It is typical in these scenarios to develop an application layer to route requests from the client to a
specific business component for further processing. Implementing this in Windows Azure is not
straightforward due to its built-in load balancer. The Windows Azure load balancer only exposes a
single external endpoint that clients interact with; therefore it is necessary to know the unique IP
address of the instance that will be performing the work. IP addresses are discoverable via the
Windows Azure API when marked as internal (configured through the web role’s properties).
While this tutorial may seem more of an exercise on WCF than on Windows Azure, it is important to
understand how to perform inter-role communication without the use of queues.
In order to filter requests by content, an internal LoadBalancer class is created. This class ensures
requests are routed to live endpoints and not dead nodes. The LoadBalancer will need to account for
endpoint failure and guarantee graceful recovery by refreshing its routing table and passing requests
to other nodes capable of processing. Following is the class definition for the LoadBalancer to detect
endpoints and recover from unexpected failures that occur.
public class LoadBalancer
{
public LoadBalancer()
{
if (IsRoutingTableOutOfDate())
{
RefreshRoutingTable();
}
}
private bool IsRoutingTableOutOfDate()
{
//Retrieve all of the instances of the Worker Role
var roleInstances = RoleEnvironment.Roles["WorkerName"].Instances;
//Check current amount of instances and confirm sync with the LoadBalancer’s //record
if (roleInstances.Count() != CurrentRouters.Count())
{
return true;
46](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-46-2048.jpg)
![The Windows Azure Platform: Articles from the Trenches
}
foreach (RoleInstance roleInstance in roleInstances)
{
var endpoint = roleInstance.InstanceEndpoints["WorkerEndpoint"];
var ipAddress = endpoint.IPEndpoint;
if (!IsEndpointRegistered(ipAddress))
{
return true;
}
}
return false;
}
private void RefreshRoutingTable()
{
var currentInstances = RoleEnvironment.Roles["WorkerName"].Instances;
RemoveStaleEndpoints(currentInstances);
AddMissingEndpoints(currentInstances);
}
private void AddMissingEndpoints(ReadOnlyCollection<RoleInstance> currentInstances)
{
foreach (var instance in currentInstances)
{
if
(!IsEndpointRegistered(instance.InstanceEndpoints["WorkerEndpoint"].IPEndpoint
))
{
//add to the collection of endpoints the LoadBalancer is aware of
}
}
}
private void RemoveStaleEndpoints(ReadOnlyCollection<RoleInstance> currentInstances)
{
//reverse-loop so we can remove from the collection as we iterate
for (int index = CurrentRouters.Count() - 1; index >= 0; index--)
{
bool found = false;
foreach (var instance in currentInstances)
{
//determine if IP address already exists set found to true
}
if (!found)
{
//remove from collection of endpoints LoadBalancer is aware of
}
}
}
private bool IsEndpointRegistered(IPEndpoint ipEndpoint)
{
foreach (var routerEndpoint in CurrentRouters)
{
if (routerEndpoint.IpAddress == ipEndpoint.ToString())
{
return true;
}
}
return false;
}
public string GetWorkerIPAddressForContent(string contentId)
{
//Custom logic to determine an IP Address from one of the CurrentRouters
//that the load balancer is aware of
}
47](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-47-2048.jpg)
![The Windows Azure Platform: Articles from the Trenches
}
The LoadBalancer is capable of auto-detecting endpoints and the remaining work for the router
service is WCF. A router, by definition, must be capable of accepting and forwarding any inbound
request. The IRouterServiceContract will accept all requests with the base-level message class and
handle and reply to all actions. Its interface is as follows:
[ServiceContract(Namespace = "http://www.namespace.com/ns/2/2009", Name = "RouterServiceContract")]
public partial interface IRouterServiceContract
{
[OperationContract(Action = "*", ReplyAction = "*")]
Message ProcessMessage(Message requestMessage);
}
The implementation of the IRouterServiceContract will use the MessageBuffer class to create a copy
of the request message for further inspection (e.g. who the sender is or determining if there is a
priority associated with it). GetWorkerIPAddressForContent on the LoadBalancer is invoked and a
target endpoint is requested. Once the router has an endpoint, a ChannelFactory is initialized to
create a connection to the endpoint and the generic ProcessMessage method is invoked. Ultimately
the endpoint that the router forwards requests to will have a detailed service contract capable of
completing the message processing.
public partial class RouterService : IRouterServiceContract
{
private readonly LoadBalancer loadBalancer;
public RouterService()
{
loadBalancer = new LoadBalancer();
}
public Message ProcessMessage(Message requestMessage)
{
//Create a MessageBuffer to attain a copy of the request message for inspection
string ipAddress = loadBalancer.GetWorkerIPAddressForContent("content");
string serviceAddress = String.Format("http://{0}/Endpoint.svc/EndpointBasic",
ipAddress);
using (var factory = new ChannelFactory<IRouterServiceContract>(new
BasicHttpBinding("binding")))
{
IRouterServiceContract proxy = factory.CreateChannel(new
EndpointAddress(serviceAddress));
using (proxy as IDisposable)
{
return proxy.ProcessMessage(requestMessageCopy);
}
}
}
}
Detecting and ensuring that the endpoints are active is half the battle. The other half is determining
what partitioning scheme effectively works when filtering requests to the correct endpoint. You may
decide to implement some way of consistently ensuring a client’s requests are processed by the
same back-end component or route based on message priority. The approach outlined above also
attempts to accommodate for any disaster-related scenarios so that an uninterrupted experience
can be provided to the client. If one of the back-end components happens to shut down due to a
hardware failure, the load balancer implementation will ensure that there is another endpoint
available for processing.
48](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-48-2048.jpg)


![The Windows Azure Platform: Articles from the Trenches
CLOUDDRIVE
A CloudDrive object can be created using either a constructor or the CreateCloudDrive extension
method to CloudStorageAccount. For example, the following creates a CloudDrive object for the VHD
contained in the page blob resource identified by the URI in cloudDriveUri:
CloudStorageAccount cloudStorageAccount = CloudStorageAccount.Parse(
RoleEnvironment.GetConfigurationSettingValue("DataConnectionString"));
CloudDrive cloudDrive =
cloudStorageAccount.CreateCloudDrive(cloudDriveUri.AbsoluteUri);
Note that this creates an in-memory representation of the Azure Drive which still needs to be
mounted before it can be used.
Create() physically creates a VHD of the specified size and stores it as page blob. Note that Microsoft
charges only for initialized pages of a page blob so there should only be a minimal charge for an
empty VHD page blob even when the VHD is nominally of a large size. The Delete() method can be
used to delete the VHD page blob from Azure Storage. Snapshot() makes a snapshot of the VHD page
blob containing the VHD while CopyTo() makes a physical copy of it at the specified URL.
A VHD page blob must be mounted on an Azure instance to make its contents accessible. A VHD
page blob can be mounted on only one instance at a time. However, a VHD snapshot can be
mounted as a read-only drive on an unlimited number of instances simultaneously. A snapshot
therefore provides a convenient way to share large amounts of information among several
instances. For example, one instance could have write access to a VHD page blob while other
instances have read-only access to snapshots of it – including snapshots made periodically to ensure
the instances have up-to-date data.
Before a VHD page blob can be mounted it is necessary to allocate some read cache space in the
local storage of the instance. This is required even if caching is not going to be used.
InitializeCache() must be invoked to initialize the cache with a specific size and location. The
following shows the Azure Drive cache being initialized to the maximum size of the local storage
named CloudDrives:
public static void InitializeCache()
{
LocalResource localCache = RoleEnvironment.GetLocalResource("CloudDrives");
Char[] backSlash = { '' };
String localCachePath = localCache.RootPath.TrimEnd(backSlash);
CloudDrive.InitializeCache(localCachePath,
localCache.MaximumSizeInMegabytes);
}
The tweak in which trailing back slashes are removed from the path to the cache is a workaround for
a bug in the Storage Client library.
An instance mounts a writeable Azure Drive by invoking Mount() on a VHD page blob. The Azure
Storage Service uses the page blob leasing functionality to guarantee exclusive access to the VHD
page blob. An instance mounts a read-only Azure Drive by invoking Mount() on a VHD snapshot.
Since it is read-only, multiple instances can mount the VHD snapshot simultaneously. An instance
52](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-52-2048.jpg)













![The Windows Azure Platform: Articles from the Trenches
USING WORKER ROLES TO IMPLEMENT A DISTRIBUTED CACHE
By Josh Tucholski
One of the most sought after goals of an aspiring application, viral growth, is also one of the quickest
routes to failure if the application receives it unexpectedly. Windows Azure addresses the problem
of viral growth by supporting a scalable infrastructure to scale and quickly allocate additional
instances of a service on an as-needed basis. However as traffic and use of an application grows, it is
inevitable that its database will suffer without any type of caching layer in place.
In smaller environments, it is sufficient to use the built-in cache that a server provides for efficient
data retrieval. This is not the case in Windows Azure. Windows Azure provides a transparent load
balancer, thereby making the placement of data into specific server caches impractical unless one
can guarantee each user continually communicates with the same web server. Armed with a
distributed cache and a well-built data access tier, one can address this issue to ensure that all
clients that issue similar data requests only retrieve to the database once and use the cached version
going forward (pending updates).
CONFIGURING THE CACHE
One of the most popular distributed caching implementations is memcached , used by YouTube,
Facebook, Twitter, and Wikipedia. Memcached can run from the command line as an executable,
making it a great use case for a Windows Azure worker role. When memcached is active all of its
data is stored in memory which makes increasing the size of the cache as easy as increasing the
worker instance count.
The following code snippet demonstrates how a worker role initializes the memcached process and
defines required parameters identifying its unique instance IP address and the maximum size of the
cache in MB. Note: Your will need to include the memcached executable to start the process within
the Windows Azure app fabric.
//Retrieve the Endpoint information for the current role instance
IPEndPoint endpoint =
RoleEnvironment.CurrentRoleInstance.InstanceEndpoints["EndpointName"].IPEndpoint;
string cacheSize = RoleEnvironment.GetConfigurationSettingValue(CacheSizeKey);
//memcached arguments
//m = size of the cache in MB
//l = IP address of the cache server
//p = port address of the cache server
string arguments = "-m " + cacheSize + " -l " + endpoint.Address + " -p " + endpoint.Port;
ProcessStartInfo startInfo = new ProcessStartInfo()
{
CreateNoWindow = true,
UseShellExecute = false,
FileName = "memcached.exe",
Arguments = arguments
};
//The worker role’s only purpose is to execute the memcached process and run until shutdown
using (Process exeProcess = Process.Start(startInfo))
{
exeProcess.WaitForExit();
}
68](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-68-2048.jpg)









![The Windows Azure Platform: Articles from the Trenches
CHAPTER 4: SQL AZURE
CONNECTING TO SQL AZURE IN 5 MINUTES
By Juliën Hanssens
"Put your data in the cloud!" Think about it… no more client side database deployment, no more
configuring of servers, yet with your data mirrored and still accessible using comfortable familiarities
for SQL Server developers. That’s SQL Azure. In this article we will quickly boost you up to speed on
how to get started with your own SQL Azure instance in less than five minutes!
PREREQUISITE – GET A SQL AZURE ACCOUNT
Let’s assume you already have a SQL Azure account. If not, you’re free to try one of the special offers
that Microsoft has available on Azure.com[1] like the free-of-charge Introductory Special or the offer
that is available for MSDN Premium subscribers.
WORKING WITH THE SQL AZURE PORTAL
With a SQL Azure account at your disposal, you first need to login to the SQL Azure Portal[2]. This is
your dashboard for managing your own server instances. The first time you login to the SQL Azure
Portal, and after first accepting the Terms of Use, you will be asked to create a server instance for
SQL Azure like the screenshot below illustrates:
1: Create a server through the SQL Azure Portal
Providing a username and password is pretty straight forward. Do notice that these credentials will
be the equivalent of your “sa” SQL Server account, for which logically strong password rules apply.
And certain user names are not allowed for security reasons. With the location option you can select
the physical location of the datacenter at which your server instance will be hosted. It is advisable to
select the geographical location nearest to your – or your users - needs.
79](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-79-2048.jpg)
![The Windows Azure Platform: Articles from the Trenches
Once you press the Create Server button it takes a second or two to initialize your fresh, new server
and you’ll be redirected to the Server Administration subsection. Congratulations, you’ve just
performed a “SQL Server installation in the cloud”!
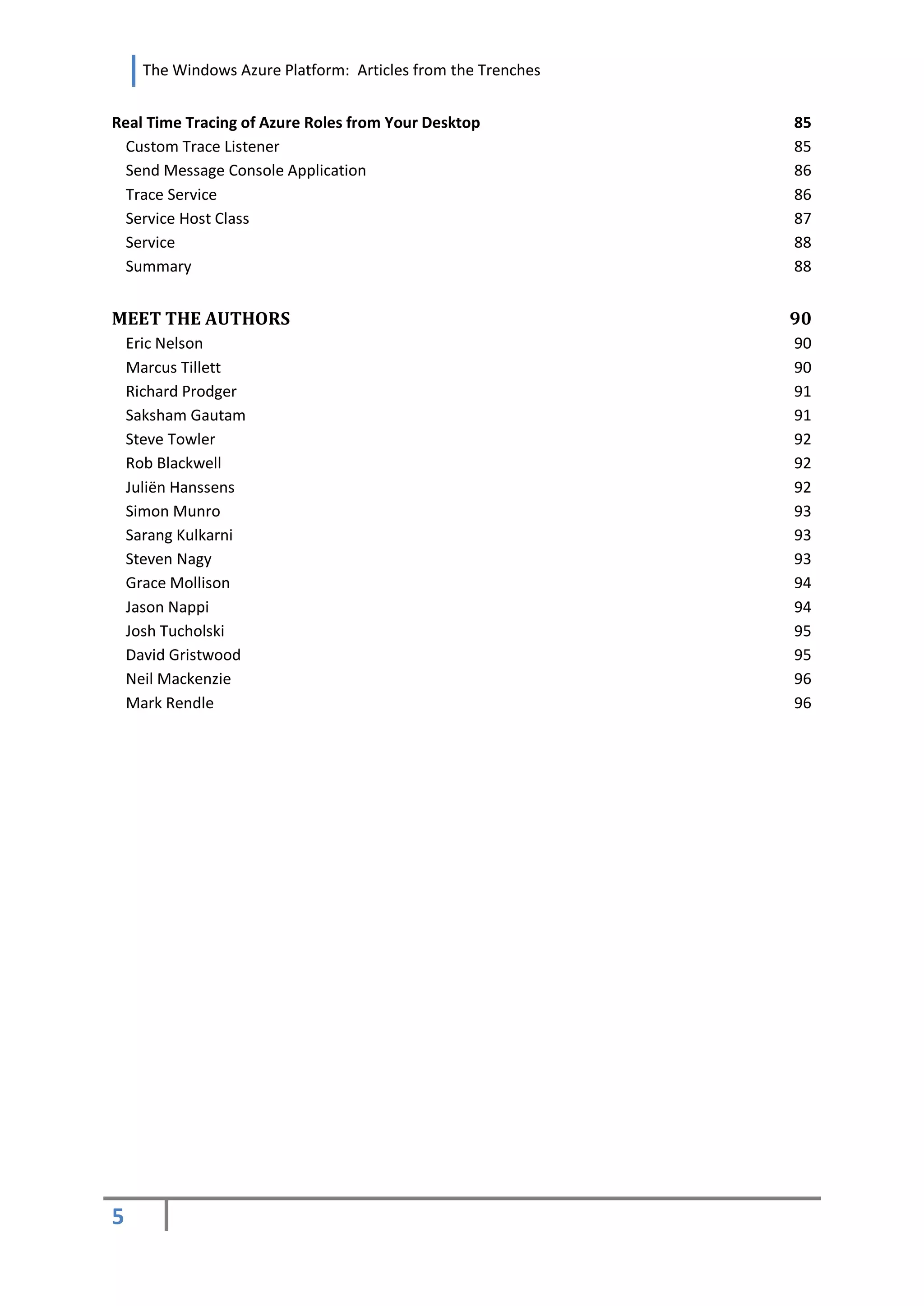
CREATE A DATABASE THROUGH THE SERVER ADMINISTRATION
Whilst still in the SQL Azure Portal[2] Server Administration section our server details are list, like the
name used for the connection string, and a list of databases. The latter is, by default, only populated
with a 'master' database. Exactly like SQL Server this specific database contains the system-level
information, such as system configuration settings and logon accounts.
We are going to leave the master database untouched and create a new database by pressing the
Create Database button.
2: Create a database through the SQL Azure Portal
On confirmation the database will be created in the “blink of an eye”. But for those who find this too
convenient you can achieve the same result using a slim script like:
CREATE DATABASE SqlAzureSandbox GO
However, in order to be able to feed our database some scripts we need to set security and get our
hands on a management tool. And for the latter why not use the tool we have used since day and
age to connect to our “regular” SQL Server instances: SQL Server Management Studio R2 (SSMS).
CONFIGURING THE FIREWALL
By default you initially cannot connect to SQL Azure with tools like SSMS. At least, not until you
explicitly tell your SQL Azure instance that you want a specific IP address to allow connectivity with
pretty much all administrative privileges.
80](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-80-2048.jpg)
![The Windows Azure Platform: Articles from the Trenches
To enable connectivity, add a rule by entering your public IP address in the Firewall Settings tab on
your SQL Azure Portal.
3: Add a firewall rule through the SQL Azure Portal’s Server Administration
Do notice the “Allow Microsoft Services access to this server” checkbox. By enabling this you allow
other Windows Azure services to access your server instance.
CONNECTING USING SQL SERVER MANAGEMENT STUDIO
Having set up everything required for enabling SSMS to manage the database, let’s start using it. If
you haven’t done so already, install the latest R2 release of the SSMS[3] first. Older versions will just
bore you with annoying error messages, so don’t waste time on that. Once in place, boot up the
81](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-81-2048.jpg)
![The Windows Azure Platform: Articles from the Trenches
SSMS application, enter the full server name and authenticate using the provided credentials.
4: Connecting SQL Server Management Studio to your SQL Azure instance
No rocket science there either. Optionally you can provide a specific database instance to connect to
in the Options section (more on that later). Once connected, you have a pretty similar environment
with SSMS on SQL Azure as you have on a ‘regular’ SQL Server instance. Although keep in mind that
with the current installment you have to do without the comfortable dialog boxes. This means you
need to brush up your skills with T-SQL. SQL Azure offers a subset, albeit significant subset, of the
familiar T-SQL features and commands you are used to using with SQL Server. This is due to the fact
that SQL Azure is designed natively for the Windows Azure platform
In a nutshell this means that the creation of tables, views, logins, stored procedures etc. by using
scripts is roughly the same in T-SQL syntax but only lacks certain (optional) parameters.
Let’s demonstrate this by creating an arbitrary table. In SSMS right click on the Tables section of our
SqlAzureSandbox database and select “New Table”. The result will be no dialog box with fancy fields,
but a basic SQL script for us to edit. Once modified, it doesn’t really differ from your average SQL
Server script. For example:
-- =========================================
-- Create table template SQL Azure Database
-- =========================================
IF OBJECT_ID('[dbo].[Beer]', 'U') IS NOT NULL
DROP TABLE [dbo].[Beer]
GO
CREATE TABLE [dbo].[Beer]
(
[Id] int NOT NULL,
[BeerName] nvarchar(50) NULL,
[CountryOfOrigin] nvarchar(50) NULL,
[AlcoholPercentage] int NULL,
[DateAdded] datetime NOT NULL,
82](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-82-2048.jpg)
![The Windows Azure Platform: Articles from the Trenches
CONSTRAINT
[PK_Beer] PRIMARY KEY CLUSTERED ( [Id] ASC )
)
GO
Once executed the table is generated. This is one thing to take notice off: tables have to be created
through SSMS by default. But once they’re available you can simply boot up Visual Studio and use
the Server Explorer to access them in your project. In fact, you can even use familiar tools with
design-time support like LINQ to SQL, ADO.NET DataSets or Entity Framework for even more
productivity.
APPLICATION CREDENTIALS
Last but not least, a recommendation on security. Up until now we have used our godlike master
credentials for managing our database. We really don’t want these credentials to be included in our
application, so let’s create a lightweight custom user/login for our application to use:
-- 1. Create a login
CREATE LOGIN [ApplicationLogin] WITH PASSWORD = 'I@mR00tB33r'
GO
-- 2. Create a user
CREATE USER [MyBeerApplication]
FOR LOGIN [ApplicationLogin]
WITH DEFAULT_SCHEMA = [db_datareader]
GO
-- 3. And grant it access permissions
GRANT CONNECT TO [MyBeerApplication]
GO
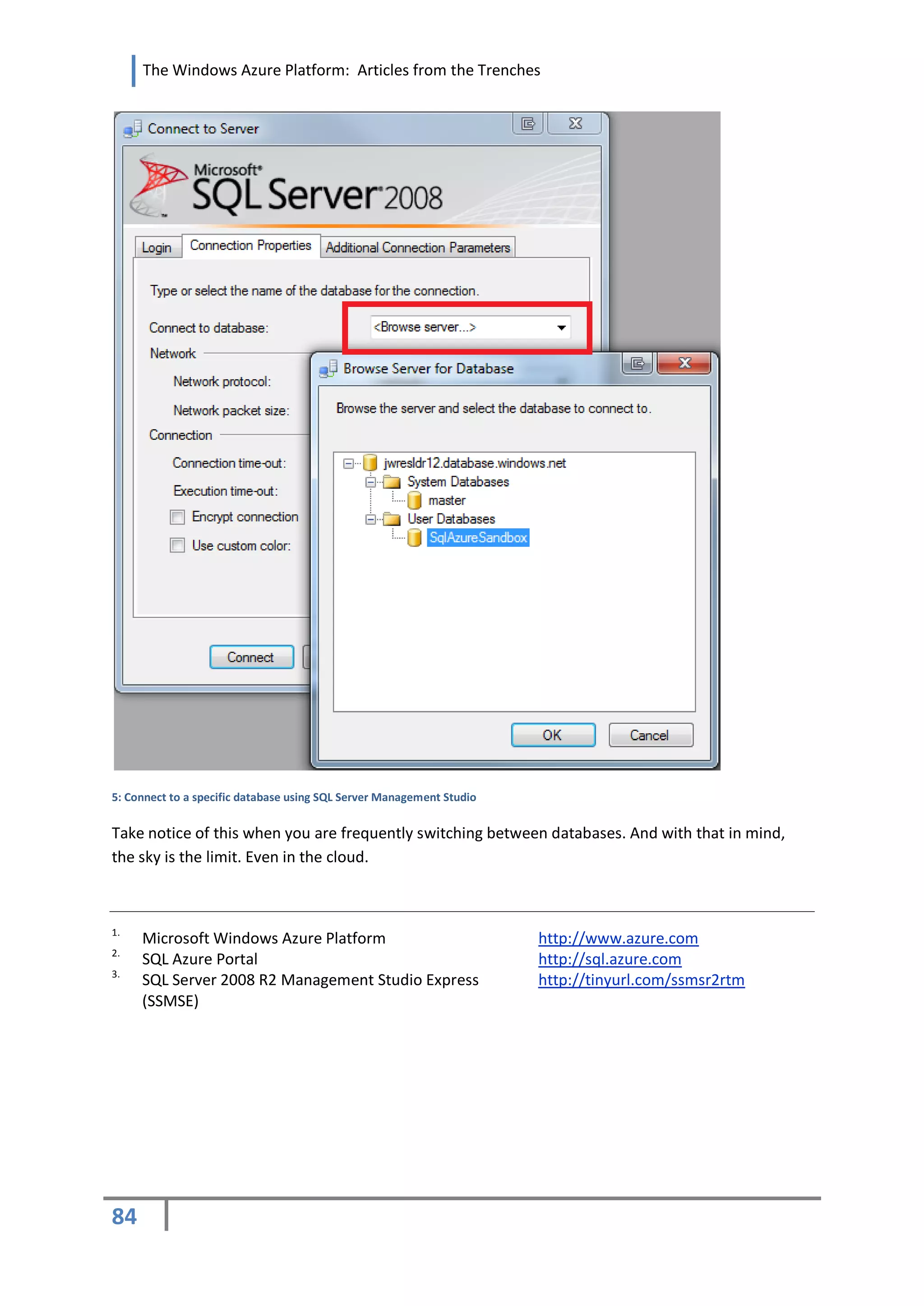
KEEP IN MIND – THE TARGET DATABASE
As you may have noticed all samples lack the USE statement, i.e. “USE *SqlAzureSandbox+”. This is
because the USE <database> command is not supported. With SQL Azure you should keep in mind
that each database can be on a different server and therefore requires a separate connection. With
SSMS you can easily achieve this in the options of the Connect to Server dialog box:
83](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-83-2048.jpg)

![The Windows Azure Platform: Articles from the Trenches
}
}
As you can see, there is some setup stuff for WCF and the service bus, but basically all you have to do is
override the Write and WriteLineMethods. The ITrace interface is simple as well:
[ServiceContract]
public interface ITrace
{
[OperationContract(IsOneWay=true)]
void WriteLine(string text);
[OperationContract(IsOneWay = true)]
void Write(string text);
}
SEND MESSAGE CONSOLE APPLICATION
Now we need an app to send the messages. For the purposes of this article, I have created a simple
console app, but this could be any Azure role.
static void Main(string[] args)
{
string issuerName = "yourissuerName";
string issuerSecret = "yoursecret";
string serviceNamespace = "yourNamespace";
string servicePath = "tracer";
TraceListener traceListener = new AzureTraceListener(serviceNamespace, servicePath,
issuerName, issuerSecret);
Trace.Listeners.Add(traceListener);
Trace.Listeners.Add(new TextWriterTraceListener(Console.Out));
while (true)
{
Trace.WriteLine("Hello world at " + DateTime.Now.ToString());
Thread.Sleep(1000);
}
}
This simple app simply creates a new custom TraceListener and adds it to the TraceListener’s collection and
that pushes out a timestamp every second. I’ve also added Console.Out as another listener so you can see
what’s being sent.
TRACE SERVICE
So that’s the Azure end done, what about the desktop end? The first thing you have to do is implement the
TraceService that the custom listener will call:
public class TraceService : ITrace
{
public static event ReceivedMessageEventHandler RecievedMessageEvent;
void ITrace.WriteLine(string text)
{
86](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-86-2048.jpg)

![The Windows Azure Platform: Articles from the Trenches
SERVICE
Now all we have to do is implement the desktop app. Again, for simplicity, I am creating a simple console
app:
static void Main(string[] args)
{
Console.Write("AZURE Trace Listener Sample started.nRegistering with Service
Bus...");
string issuerName = "yourissuerName";
string issuerSecret = "yoursecret";
string serviceNamespace = "yourNamespace";
string servicePath = "tracer";
// Start up the receiver
AzureTraceReceiver receiver = new AzureTraceReceiver(serviceNamespace, servicePath,
issuerName, issuerSecret);
receiver.Start();
// Hook up the event handler for incoming messages
TraceService.RecievedMessageEvent += new
ReceivedMessageEventHandler(TraceService_myEvent);
// Now, just hang around and wait!
Console.WriteLine("DONEnWaiting for trace messages...");
string input = Console.ReadLine();
receiver.Stop();
}
static void TraceService_myEvent(object sender, string message)
{
Console.WriteLine(message);
}
This app simply instantiates the receiver class and starts the service host. An event handler is registered
and then just waits for messages. When the client sends a trace message the event handler fires and the
message is written to the console.
You may have noticed that I have used the NetEventRelayBinding for the service bus. This was deliberate as
it allows you to hook up multiple server ends to receive the messages in a classic pub/sub pattern. This
means you can run multiple instances of this server on multiple machines and they all receive the same
messages. You can use other bindings if required. Another advantage of this binding is that you don't have
to have any apps listening, but bear in mind you will be charged for the connection whether you are
listening or not, although you won’t have to pay for the outbound bandwidth. I put all the WCF and service
bus setup into the code, but this could easily be placed into a configuration file. I prefer it this way as I have
a blind spot when it comes to reading WCF config in xml and I always get it wrong, but it does mean you
can’t change the bindings without recompiling.
SUMMARY
There is more that could be done in the TraceListener class to improve thread safety, error handling and to
ensure that the service bus channel is available when you want to use it, but I’ll leave that up to you. This
88](https://image.slidesharecdn.com/windowsazureplatformarticlesfromthetrenches-100623054253-phpapp01/75/Windows-Azure-Platform-Articles-from-the-Trenches-Volume-One-88-2048.jpg)









The document is a comprehensive guide about the Windows Azure platform, compiling articles from various developers to assist others in effectively utilizing the platform for cloud computing. It covers essential topics from getting started, architectural principles, and development best practices, to specific technologies like SQL Azure and AppFabric. This book serves as a resource for both new and experienced developers looking to leverage Azure's capabilities for building scalable applications.







































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

