Cassandra's data model is more flexible than typically assumed.
Cassandra allows tuning of consistency levels to balance availability and consistency. It can be made consistently when certain replication conditions are met.
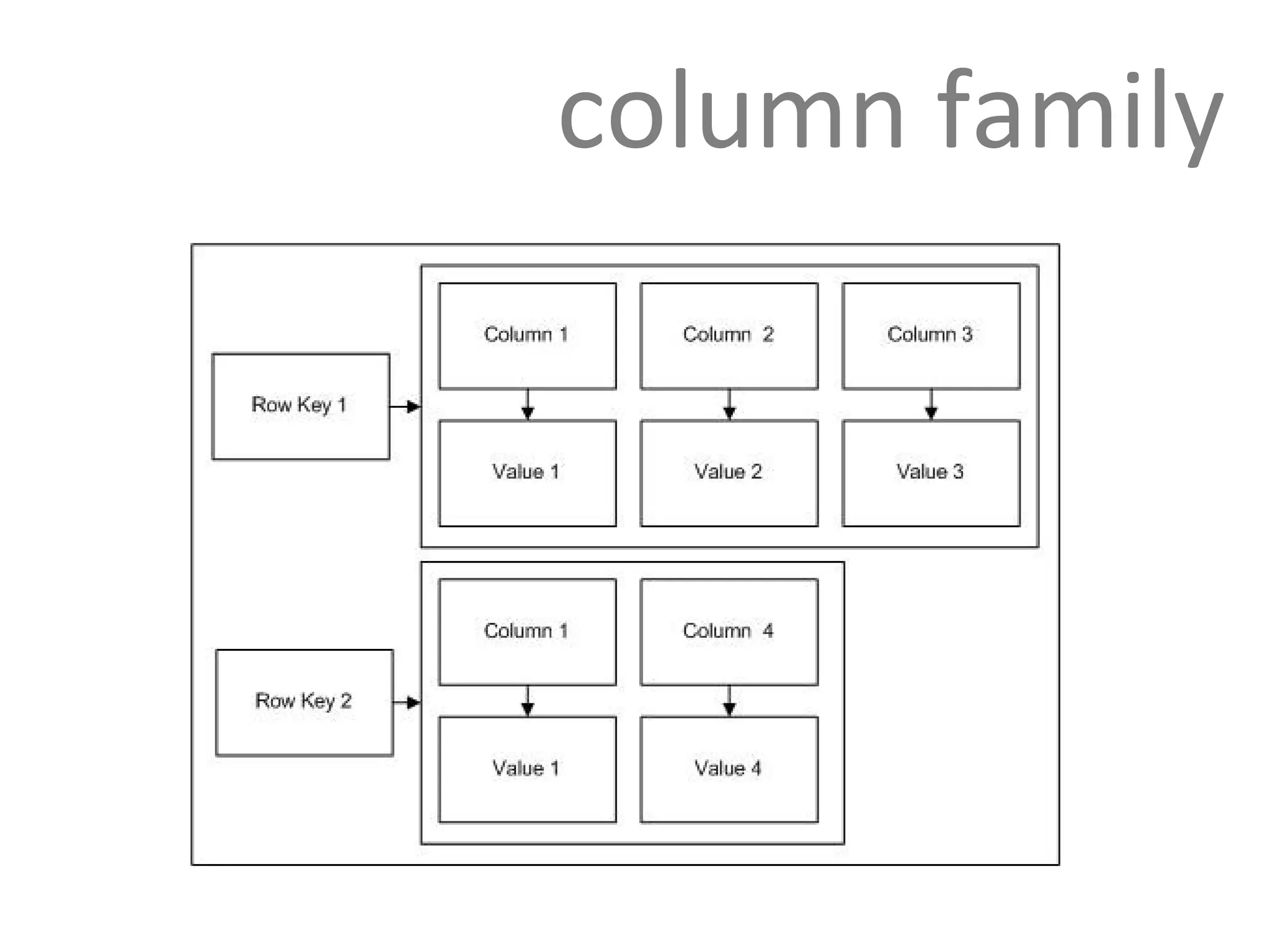
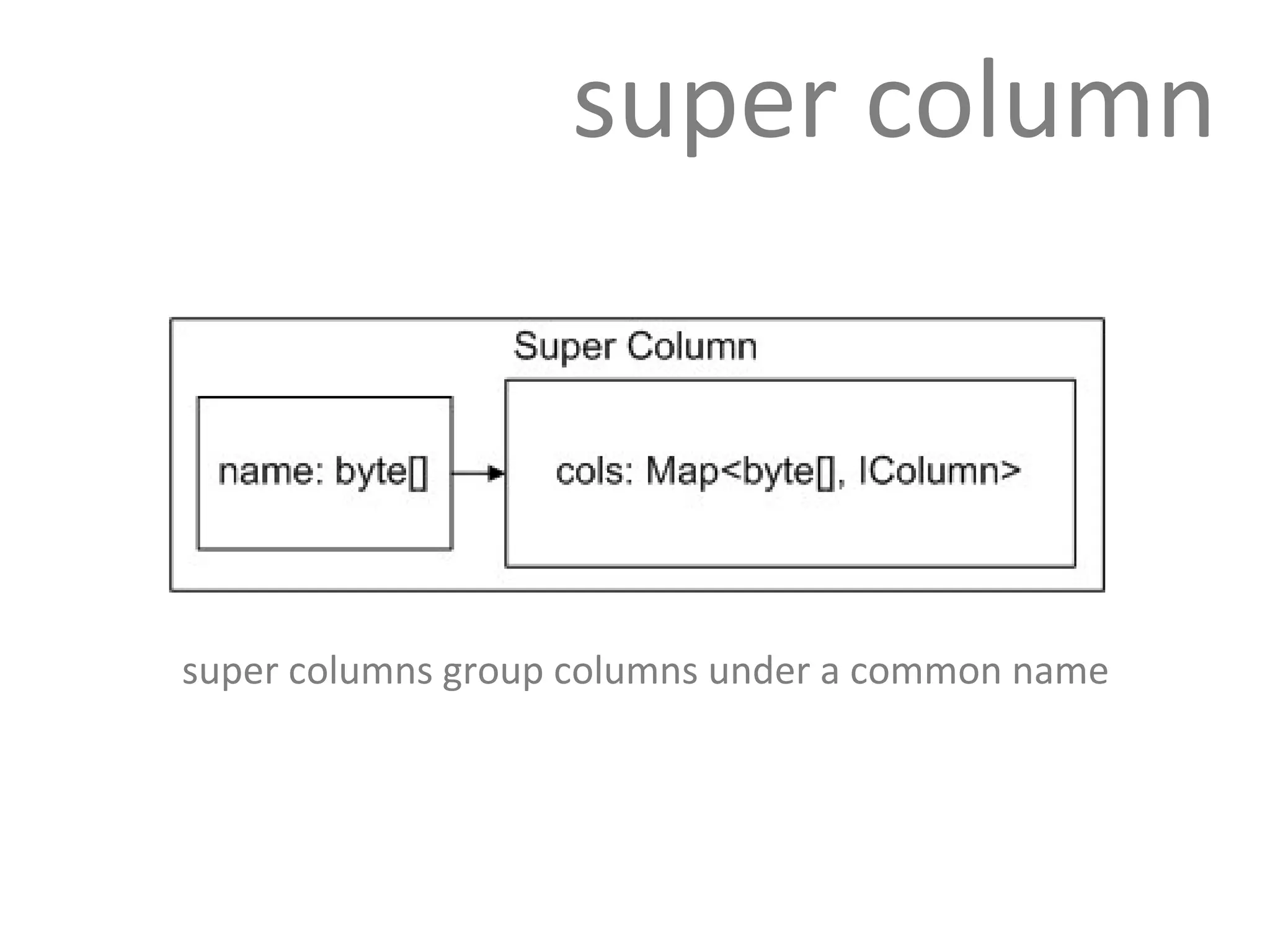
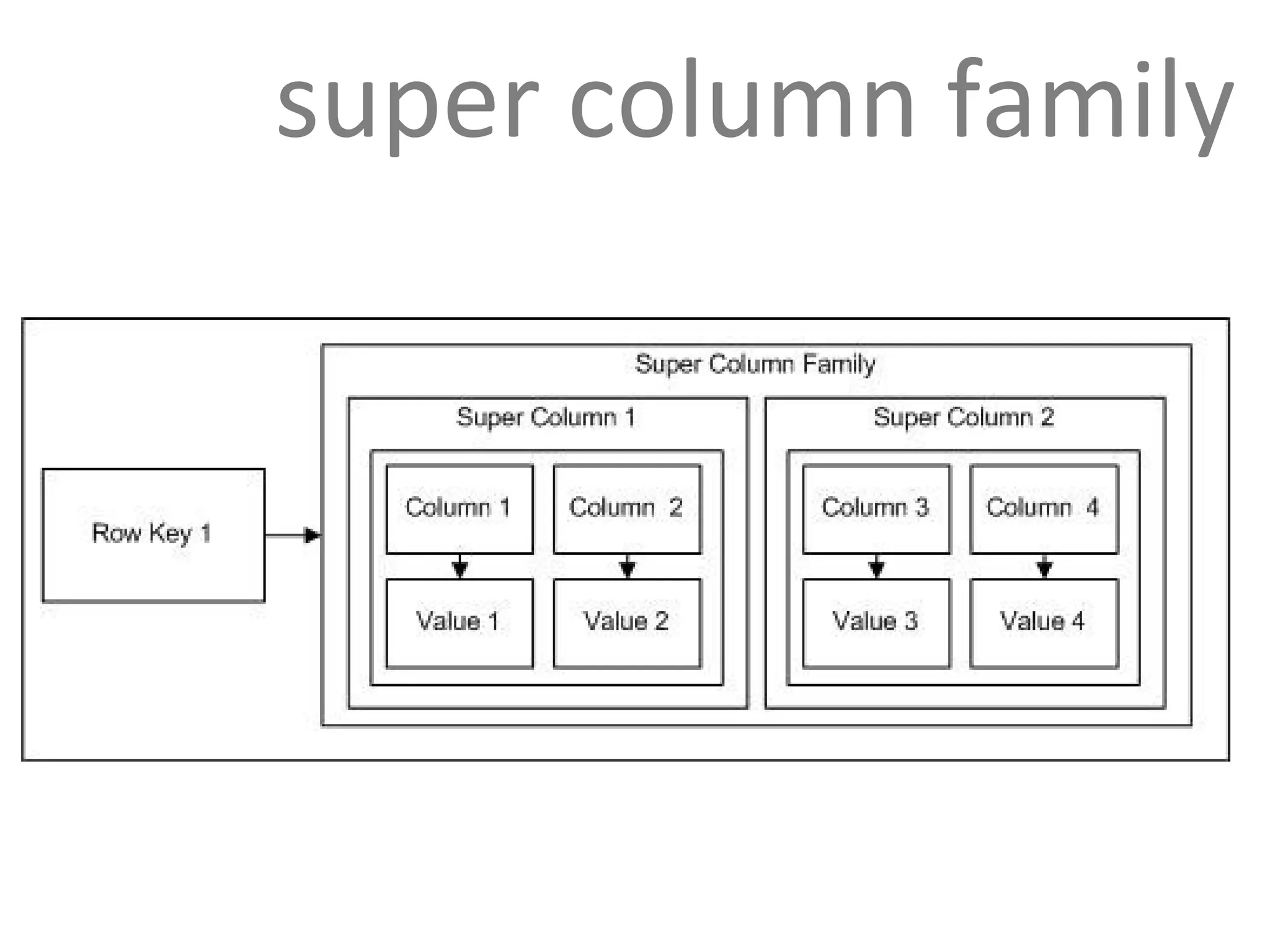
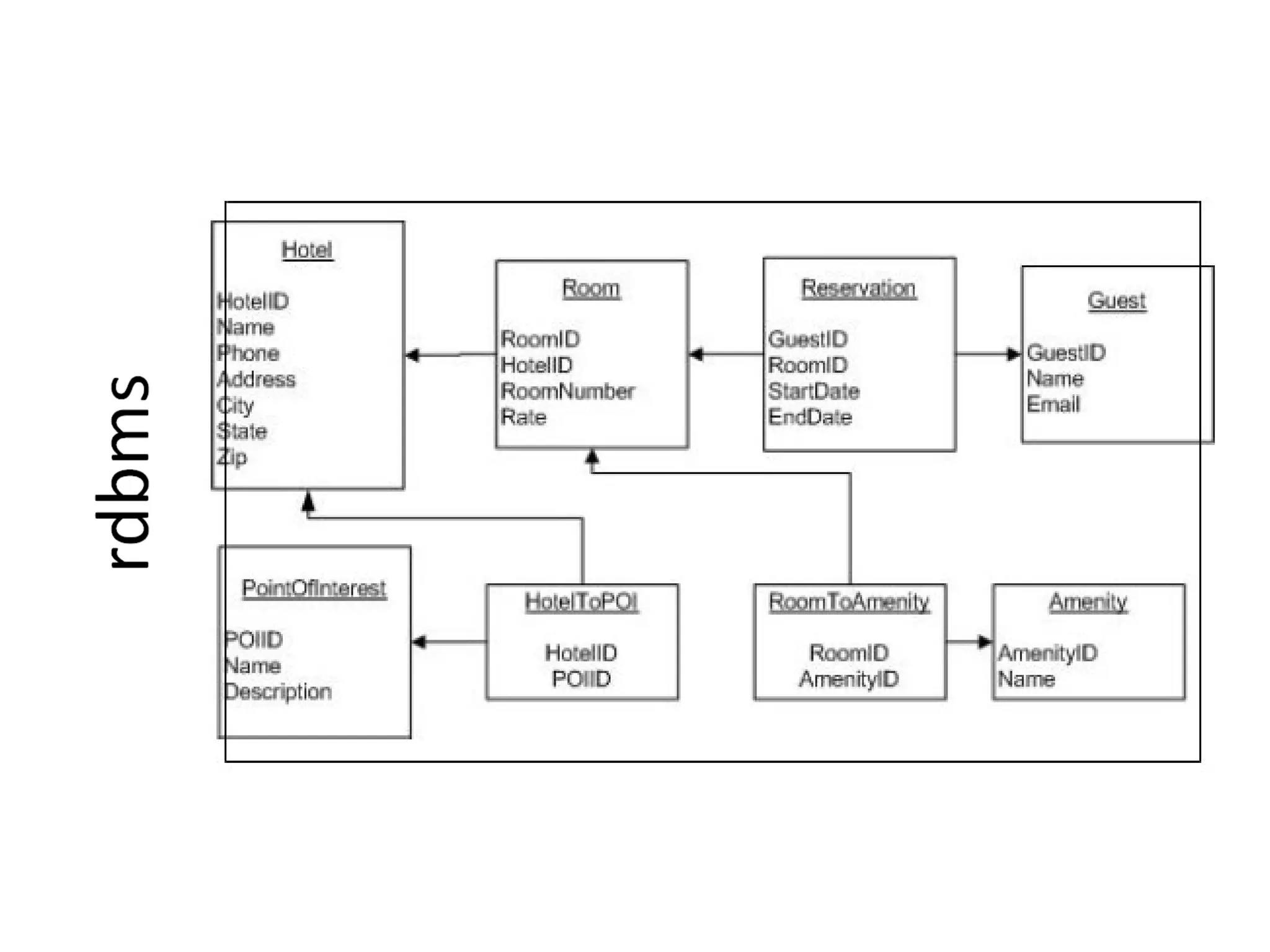
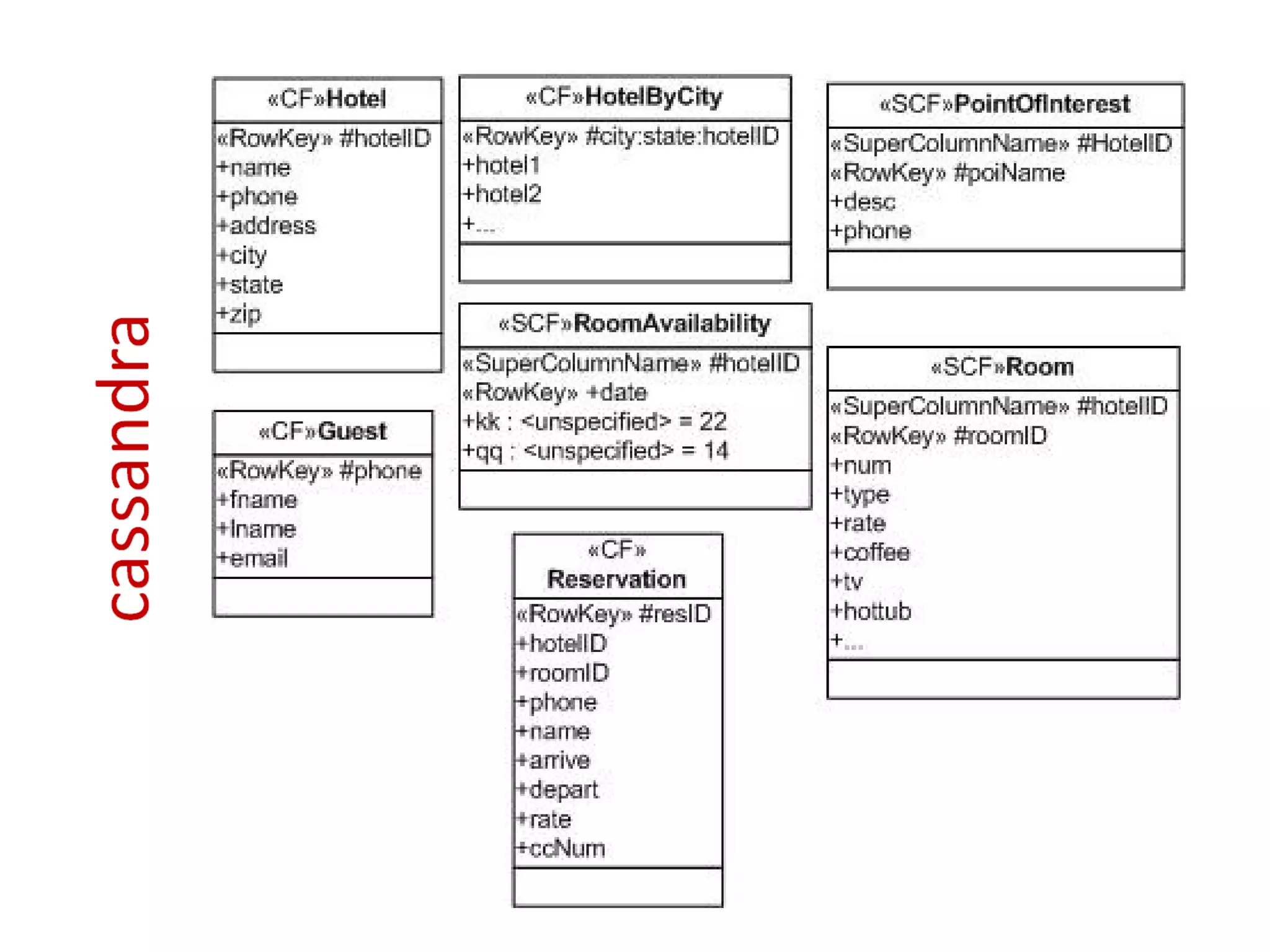
Cassandra uses a row-oriented model where rows are uniquely identified by keys and group columns and super columns. Super column families allow grouping columns under a common name and are often used for denormalizing data.
Cassandra's data model is query-based rather than domain-based. It focuses on answering questions through flexible querying rather than storing predefined objects. Design patterns like materialized views and composite keys can help support different types of queries.




























![problem Indexes require repeating columns from other column families. solution Treat the name of the column as the value . Use a byte[0] as the column ‘value’. impacts Only works with <= 2B columns in 0.7 valueless column](https://image.slidesharecdn.com/cassandra-data-model-100816185514-phpapp02/75/Cassandra-Data-Model-32-2048.jpg)

















































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)







