More Related Content
Similar to SharePoint 2013 -sharepoint-search-architecture
Similar to SharePoint 2013 -sharepoint-search-architecture (20)
More from David J Rosenthal
More from David J Rosenthal (20)
SharePoint 2013 -sharepoint-search-architecture
- 1. Search Architectures for SharePoint Server 2013
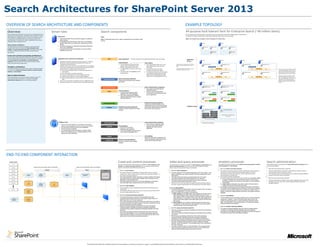
OVERVIEW OF SEARCH ARCHITECTURE AND COMPONENTS EXAMPLE TOPOLOGY
Overview Server roles Search components All-purpose fault tolerant farm for Enterprise Search (~40 million items)
Search in Microsoft® SharePoint® Server 2013 is re-architected with new This farm illustrates a fully fault-tolerant, virtual environment for SharePoint Server 2013 including search. This illustration is
components to facilitate greater redundancy within a single farm and to an example of a medium enterprise farm with approximately 40 million items in the search index.
allow scalability in multiple directions. The search architecture consists Web server None
of components and databases that work cohesively to perform the · Hosts Search Web Parts and Web Part pages for answering Note: In SharePoint Server 2013, search components are not hosted on Web Note: This example does not apply to search topologies for Internet Sites.
search operation. All components reside on application servers and all search queries. servers.
databases reside on database servers. · In dedicated search service farms, this role is not necessary
because Web servers at remote farms contact query servers Host A Host B
Index and query architecture directly.
The index and query architecture responds to search queries and · This role is necessary for farms that include other SharePoint
Web server Web server Web server Web server
provides search results. It includes the index component, index Server 2013 capabilities.
partition, and query processing component, all of which can be scaled · In small farms, this role can be shared on a server with the
out based on content volume, query volume, and performance application server role.
Office Web Office Web
requirements. Apps Server Apps Server
Crawl and content processing architecture
The crawl and content processing architecture crawls content, processes
content, and then feeds content into the index component. It includes Application server with search components Index Index component — The index component is the logical representation of an index replica.
the crawl component, crawl database and content processing
Application
Host C Host D Host E Host F
component. These components can be scaled out based on crawl · Holds all of the search components if only one server is configured. servers
volume and performance requirements. Otherwise, it holds components associated with the server, as Index partitions Index replicas
configured by the administrator. · You can divide the index into discrete · Each index partition holds one or more Up to 4 VMs can be combined onto one physical Application Server Application Server Application Server Application Server
host if the host has sufficient CPU cores and
· Holds the entire search index if only one index partition is configured. portions called index partitions, each index replicas that contain the same
Analytics architecture Otherwise, it holds portions of the index that are associated with the holding a separate part of the index. information.
RAM. Query Processing Query Processing
The analytics architecture provides search analytics and usage analytics. index partitions as configured by the administrator. · An index partition is stored in a set of files · You have to provision one index Combining all Application Server roles onto one Replica Index partition 0 Replica Replica Index partition 2 Replica
The index is stored across replicas. Each replica
It consists of the analytics processing component, analytics reporting on a disk. VM requires Windows Server 2012.
q The query processing component routes incoming queries to component for each index replica. for a given index partition contains the same
database and link database. index replicas. · The search index is the aggregation of all · To achieve fault tolerance and redundancy, data. The data within index replicas is stored in
Application Server Application Server Application Server Application Server the file system on the server. Each replica is a
q Each index replica is an index component. index partitions. create additional index replicas for each logical representation of an index component.
q At least one index partition must be configured per farm. index partition and distribute the index
Search administration When scaling out search, typically one index
q Add more index replicas to increase query throughput. replicas over multiple application servers. Index partition 1 Index partition 3 partition is replicated across two servers or
Search administration runs system processes related to search. The Replica Replica Replica Replica
q Add one index partition for every 10 million items in the search VMs. In this configuration, a VM hosts only one
search administration architecture is composed of the search Query processing component index replica. Index replicas for the same
index. Query processing
administration component and its corresponding database. Analyzes and processes search queries partition must run on separate physical hosts
· At least one of each search component must be configured per farm. (whether virtualized or not) to achieve fault
· Add search components on separate servers to provide redundancy. and results. Host G Host H tolerance.
Application server— All other Application server— All other
Search administration Search administration component application roles application roles
· Runs system processes that are
essential to search.
Crawl Crawl component Application server Application server
· Only one search administration
· Crawls content based on what is Analytics Analytics
component can be active per Search
specified in the crawl databases. Content processing Content processing
service application.
· Add crawl components to address
capacity requirements and to increase
Application server Application server
crawl performance.
Admin Admin
Crawl Content processing Crawl Content processing
Content processing component
Content processing
Carries out various processes on the
crawled items such as: document parsing Host I Host J
Analytics processing component Database servers
Analytics and property mapping before feeding the
Carries out search analytics and usage items to the index component.
analytics. All SharePoint databases All SharePoint databases
Crawl db
Search admin db Crawl db
Redundant copies of all databases using
Link db Analytics db SQL clustering, mirroring, or SQL Server
2012 AlwaysOn
SharePoint Config db
All other SharePoint databases
Database server Search administration database
Search admin db Paired hosts for fault-tolerance
· Hosts search-related databases: crawl database, link database, · Stores search configuration data.
analytics reporting database and search administration database. · Only one search administration
Crawl db Crawl database
· database per Search service
Can host other SharePoint Server 2013 databases. · Stores the crawl history
· application.
Can be mirrored or clustered. · Manages crawl operations
· To increase performance and capacity, consider adding · Each crawl database can have one or
disks to the database server or adding database servers more crawlers associated with it.
(depending on the bottleneck).
Link db Link database
Stores the information extracted by the
content processing component and also
Analytics db Analytics reporting database
stores click-through information.
Stores the results of search usage
analytics.
END-TO-END COMPONENT INTERACTION
COMPONENT OVERVIEW
Content Sources Crawl and content processes Index and query processes Analytics processes Search administration
HTTP The crawl and content processing architecture includes the crawl component, crawl The index and query architecture includes the index component, index partition, and The analytics architecture consists of the analytics processing component, analytics Search administration is composed of the search administration component and its
database and content processing component. Both components can be scaled out query processing component, all of which can be scaled out based on content reporting database and link database. corresponding database.
Content is fed to the search index in this direction Query is sent to the search index in this direction based on crawl volume and performance requirements. 6
File shares volume, query volume, and performance requirements.
3 About the analytics processing component About the search administration component
Content Query
SharePoint Front-end 1 About the crawl component 4 About the index component · The analytics processing component analyzes crawled items (search analytics) · The search administration component is responsible for running a number of
· The crawl component is responsible for crawling content sources. It delivers · An index component is the logical representation of an index replica. In the and how users interact with search results (usage analytics). It uses the system processes that are essential to search.
User Profiles 1 Content 2 4 5
crawled items – both the actual content as well as their associated metadata – to search architecture, you have to provision one index component for each information to improve search relevance, and to create search reports, · This component carries out provisioning, which is to add and initialize additional
Crawl Index Query Processing
Component
Processing
Component Component the content processing component. index replica. recommendations, and deep links. instances of the other search components.
Component Client Application
Exchange · The crawl component invokes connectors or protocol handlers that interact · The index component receives processed items from the content · This component extracts the following: D
with content sources to retrieve data. Multiple crawl components can be processing component and writes those items to an index file. q Search analytics information such as links, anchor text, information related About the search administration database
Lotus Notes deployed to crawl simultaneously. · The index component receives queries from the query processing to people, metadata, etc. from items that it receives via the content · The search administration database stores search configuration data, such as the
· The crawl component uses one or more crawl databases to temporarily component and provides results sets in return. processing component and stores the information in the link database topology, crawl rules, query rules, and the mappings between crawled and
Documentum Crawl
A 3 store information about crawled items and to track crawl history. · Queries are sent to the index replicas through the query processing component. unprocessed. managed properties.
Analytics
Database
Processing Link
B
The system routes and load balances the incoming queries to the index replicas. q Usage analytics information such as the number of times an item is
Component Database viewed, from the front-end via the event store.
A About the crawl database
· The analytics processing component analyzes both types of information.
Index file store on disk
· The crawl database contains detailed tracking and historical information about About the index partition The results from the analyses are then returned to the content processing
Custom crawled items. · An index partition is a logical portion of the entire search index. The search component (using a partial update) to be included in the search index. In
Analytics C · This database holds information such as the last crawl time, the last crawl ID and index is the aggregation of all index partitions. addition, results from usage analytics are stored in the analytics reporting
Reporting
Database the type of update during the last crawl. · The search index can be scaled in two directions: database.
q Index replicas can be added within index partitions according to query
2 About the content processing component load or fault tolerance needs. Each index partition has one or more B About the link database
· The content processing component is placed between the crawl index replicas. Within an index partition, each index replica contains the
Search
6 D same information. For example, in a farm with one index partition that · The link database stores information extracted by the content processing
Search component and the index component. It processes crawled items and component. In addition, it stores information about search clicks; the
Administration Administration
feeds these items to the index component. contains three index replicas, each index replica serves one-third of the
Component Database Event store number of times people click on a search result from the search result
· The content processing component transforms crawled items into artifacts total queries.
q Index partitions can be added to handle increased content volume. page. This information is stored unprocessed. The analytics processing
that can be included in the search index by carrying out operations such as component performs the analysis.
document parsing and property mapping. For example, in a farm with three index partitions, each index partition
· Both the content processing component and the query processing contains one-third of the entire search index.
C About the analytics reporting database
component perform linguistics processing. Examples of linguistics 5 About the query processing component · The analytics reporting database stores the results of usage analysis.
processing during content processing are language detection and entity
extraction. · The query processing component is between the search front-end and the · In addition, the analytics reporting database also stores statistics
· The content processing component writes information about links and index component. information from the different analyses. SharePoint uses this information in
URLs to the link database. In turn, the analytics processing component · The query processing component analyzes and processes search queries to create Excel reports that show different statistics.
writes information related to the relevance of these links and URLs to the and results.
search index via the content processing component. · Both the query processing component and the content processing
component perform linguistics processing. Examples of linguistics
processing during query processing are word-breaking and stemming.
· When the query processing component receives a query from the search
front-end, it analyzes and processes the query to attempt to optimize
precision, recall, and relevancy. The processed query is then submitted to
the index component.
· The index component returns a result set based on the processed query
back to the query processing component, which in turn processes that
result set before sending it back to the search front-end.
© 2012 Microsoft Corporation. All rights reserved. This documentation is preliminary and subject to change. To send feedback about this documentation, please write to us at ITSPDocs@microsoft.com.