


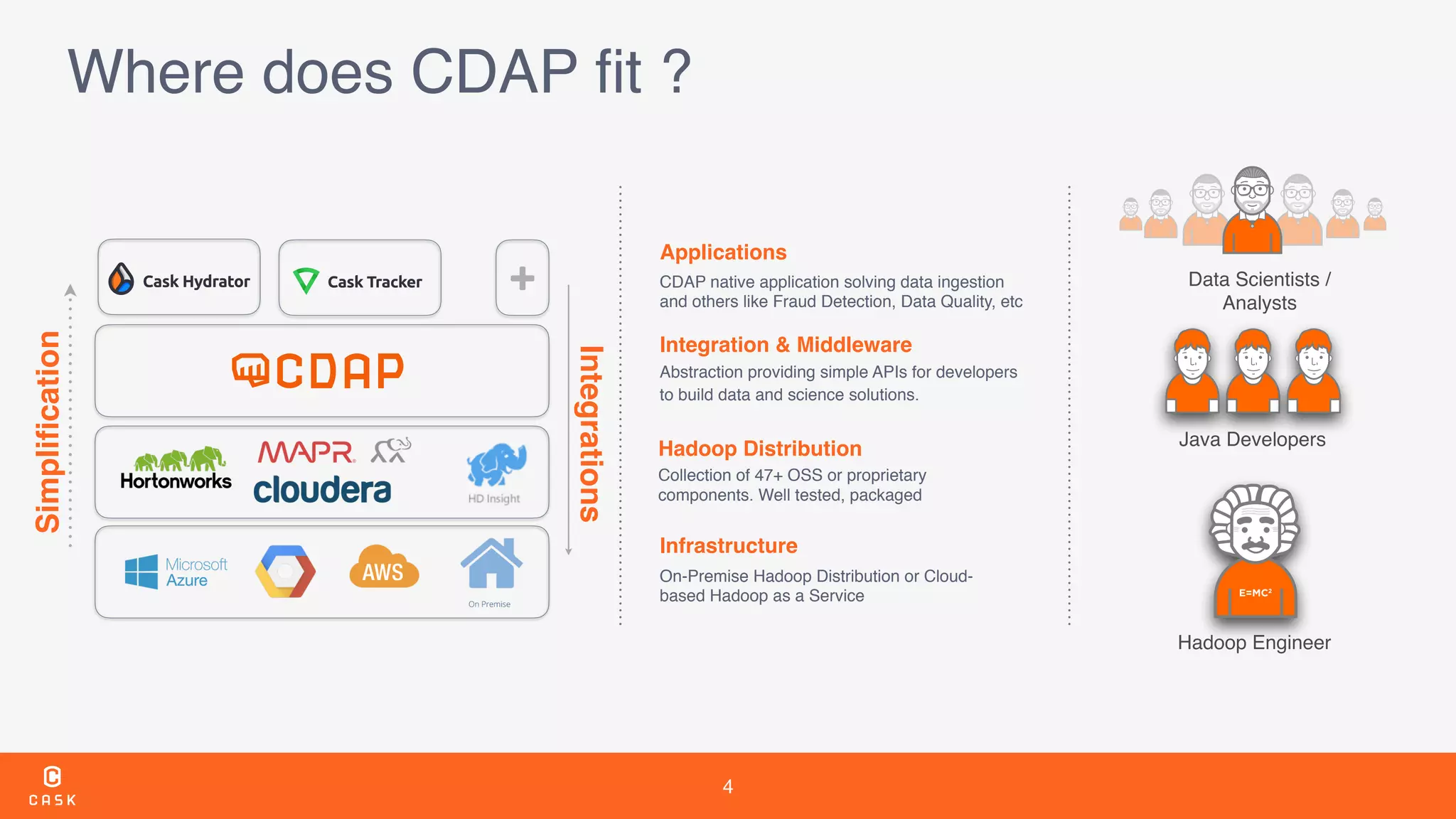

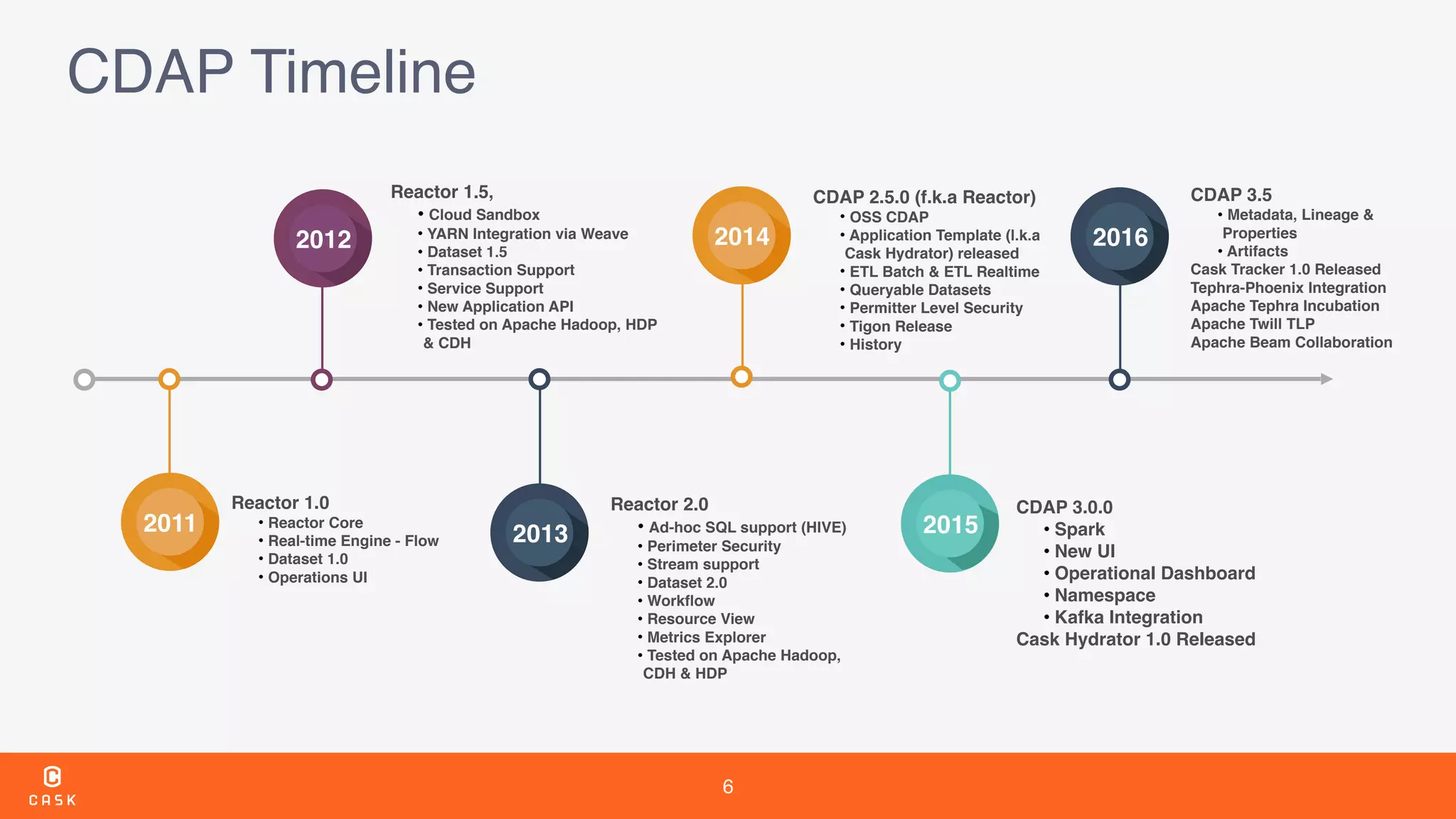





















The document outlines the features and improvements introduced in CDAP 3.5, a framework for building and managing data pipelines. It highlights self-service capabilities, integration with Hadoop technologies, enhanced security measures, and new functionalities for real-time data processing and analytics. Additionally, it details the timeline of CDAP releases and the introduction of tools for metadata management and data quality tracking.







































































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)



